


Did you know? Over 80% of data engineering teams report that pipeline orchestration and reliability are their biggest operational challenges, making the right pipeline tools critical for success.
With enterprises processing petabytes of data daily across hybrid cloud environments, robust pipeline tools have become essential for maintaining data quality, reducing downtime, and enabling real-time analytics. Modern data pipeline tools help automate complex workflows, ensure data lineage, and provide monitoring capabilities across distributed systems.
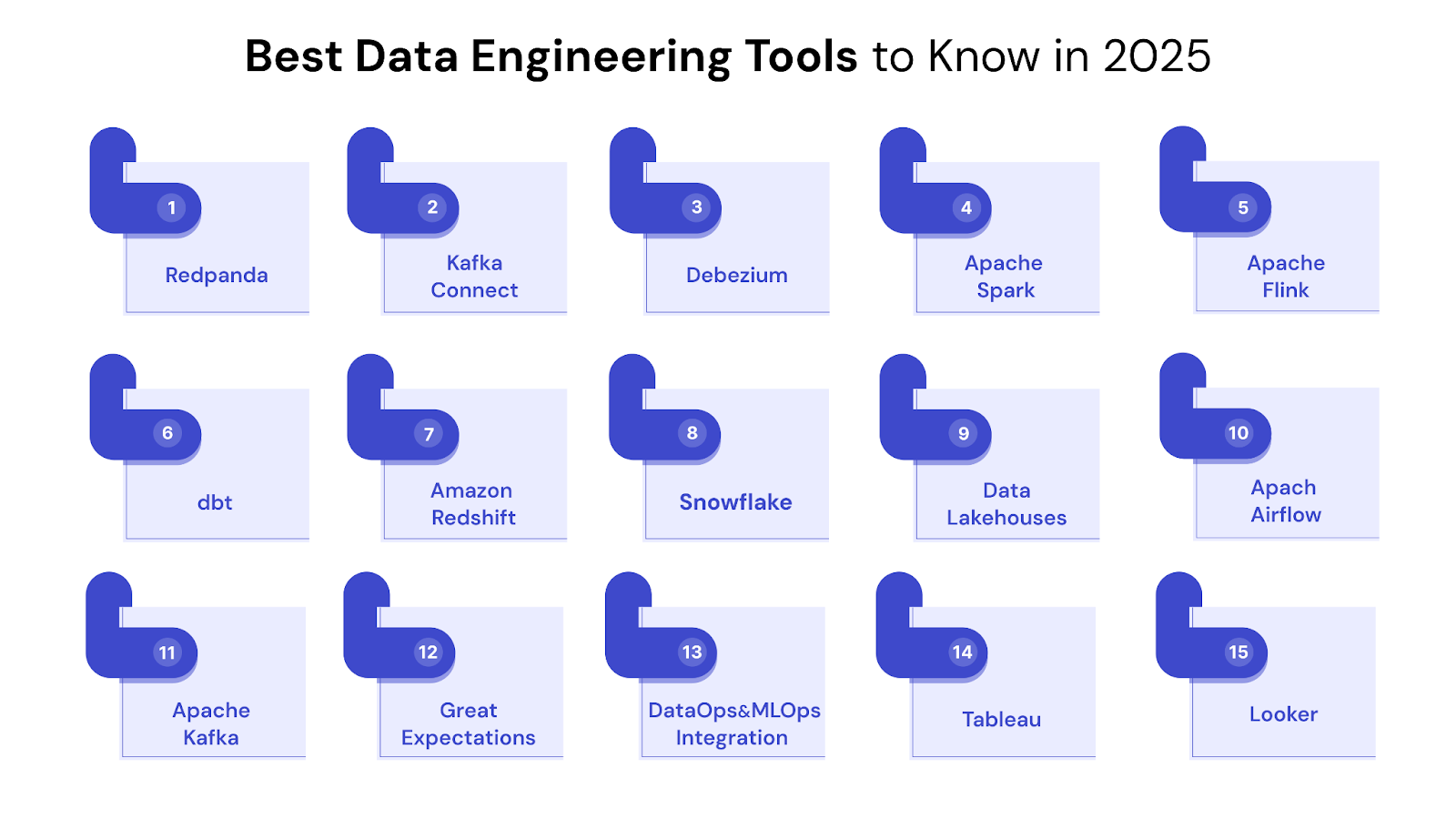
This comprehensive guide explores the top 15 data pipeline tools of 2025, covering orchestration, ETL/ELT, streaming, and integration platforms with their key features, use cases, strengths, and limitations.
TL;DR
Data pipeline tools are software solutions that automate the extraction, transformation, and loading (ETL) of structured and unstructured data into centralized repositories. With the global data pipeline market projected to reach US$13.68 billion by the end of 2025, their importance continues to grow as businesses seek faster insights.
ETL pipelines are a subset of data pipelines focused on batch processing, while broader data pipelines include real-time streaming, orchestration, and quality workflows.
These tools address challenges like poor data quality, integration complexity, scalability, reliability, and security, with breaches exposing over 422.61 million records in 2024.
These tools go beyond simple ETL by providing:
Types of Data Pipeline Tools:
The tools below span orchestration engines, cloud-native ETL platforms, streaming processors, and enterprise integration solutions that help to automate data engineering fundamentals.
The data pipeline market is projected to reach $33.94 billion by 2030, driven by cloud adoption, real-time analytics, and regulatory compliance needs. Selecting the right combination of tools determines your team's ability to scale, maintain reliability, and deliver insights at speed.
Let's explore these tools across key functional categories.
Apache Airflow powers over 12,000 organizations worldwide, providing programmatic workflow management with Python-based DAGs (Directed Acyclic Graphs) for complex pipeline orchestration.
Best use case: Teams needing flexible, code-based workflow management with complex dependencies, custom operators, and integration with diverse data systems.
Key Features:
Strengths vs Limitations
Ready to ensure your data flows error-free? Explore our complete guide to testing data pipelines and build trust in every step of your pipeline
AWS Glue provides serverless ETL with automatic scaling, processing millions of records without infrastructure management, integrated with the broader AWS ecosystem.
Best use case: AWS-native environments requiring serverless data processing, automatic schema discovery, and seamless integration with S3, Redshift, and other AWS services.
Key Features:
Strengths vs Limitations
3. Fivetran
Fivetran automates data integration from 500+ sources with pre-built connectors, handling schema changes and providing reliable, fully-managed ELT pipelines.
Best use case: Organizations needing rapid data integration from SaaS applications, databases, and APIs without engineering overhead.
Key Features:
Strengths vs Limitations
Start simplifying your data workflows today. Explore the top tools and solutions designed for seamless modern data integration
Azure Data Factory provides hybrid data integration with 90+ connectors, supporting both cloud and on-premises systems with visual pipeline design.
Best use case: Microsoft-centric environments requiring hybrid cloud integration, on-premises connectivity, and integration with Azure services.
Key Features:
Strengths vs Limitations
Reduce risk and downtime with secure, efficient database migration services backed by technical expertise and proven frameworks.
Plan Your Migration →
Hevo Data offers no-code data pipeline automation with 150+ integrations, real-time monitoring, and automatic error handling for mid-market companies.
Best use case: Mid-market businesses needing quick setup to prepare data, automated data pipelines with minimal technical resources and comprehensive monitoring.
Key Features:
Strengths vs Limitations
Informatica PowerCenter handles enterprise-scale data integration with advanced transformations, supporting complex business rules and high-volume processing across hybrid environments.
Best use case: Large enterprises requiring comprehensive data integration, master data management, and complex transformation logic with strict governance requirements.
Key Features:
Strengths vs Limitations
IBM InfoSphere DataStage provides high-performance ETL with parallel processing, handling massive data volumes with enterprise-grade reliability and integration capabilities.
Best use case: Large enterprises with existing IBM infrastructure requiring high-performance batch processing and complex data transformations.
Key Features:
Strengths vs Limitations
Want to make data transformation easier? Learn how DBT helps build reliable data pipelines step by step.
Google Cloud Dataflow provides serverless stream and batch processing using Apache Beam, with automatic scaling and integration with Google Cloud services.
Best use case: Organizations using Google Cloud requiring unified batch and stream processing with automatic scaling and minimal operational overhead.
Key Features:
Strengths vs Limitations
Migrate from legacy systems to modern infrastructure with zero disruption, complete security, and full business continuity.
Start Your Migration Plan →
Apache Kafka processes trillions of messages daily across 80% of Fortune 100 companies, providing distributed event streaming with high throughput and fault tolerance.
Best use case: Organizations building event-driven architectures requiring high-throughput message streaming, data preparation, real-time analytics, and system decoupling.
Key Features:
Strengths vs Limitations
Airbyte offers open-source data integration with 300+ connectors, providing flexibility for custom integrations and community-driven development.
Best use case: Engineering teams needing customizable data integration with open-source flexibility and the ability to build custom connectors.
Key Features:
Strengths vs Limitations
Stitch provides simple, reliable data integration with 130+ connectors, focusing on ease of use and quick setup for analytics teams.
Best use case: Small to medium businesses needing straightforward data integration with minimal setup time and technical complexity.
Key Features:
Strengths vs Limitations
Integrate.io combines ETL, ELT, and API management in a unified platform, providing comprehensive data integration capabilities with visual development tools.
Best use case: Mid-market companies needing comprehensive data integration across multiple use cases including ETL, API management, and real-time processing.
Key Features:
Strengths vs Limitations
Ready to create your own data pipeline? Follow these steps to build it from the ground up
Matillion provides cloud-native ETL designed specifically for cloud data warehouses, with push-down optimization and visual pipeline development.
Best use case: Organizations using cloud data warehouses (Snowflake, Redshift, BigQuery) requiring optimized ETL with visual development and strong performance.
Key Features:
Strengths vs Limitations
Qlik Sense provides self-service data preparation and visualization with associative analytics, enabling business users to explore data relationships intuitively.
Best use case: Organizations needing self-service analytics with powerful data exploration capabilities and intuitive business user adoption for interactive dashboards.
Key Features:
Strengths vs Limitations
Want to manage your data pipeline better? Start with our complete guide on engineering data management for clear steps and smart solutions.
Talend provides a comprehensive data integration and governance platform with big data processing, API services, and data quality capabilities.
Best use case: Enterprises requiring comprehensive data management including integration, quality, governance, data engineering and big data processing in a unified platform.
Key Features:
Strengths vs Limitations
Whether you're modernizing legacy systems or scaling analytics, QuartileX helps you harness data for real growth.
Schedule a Strategy Session →
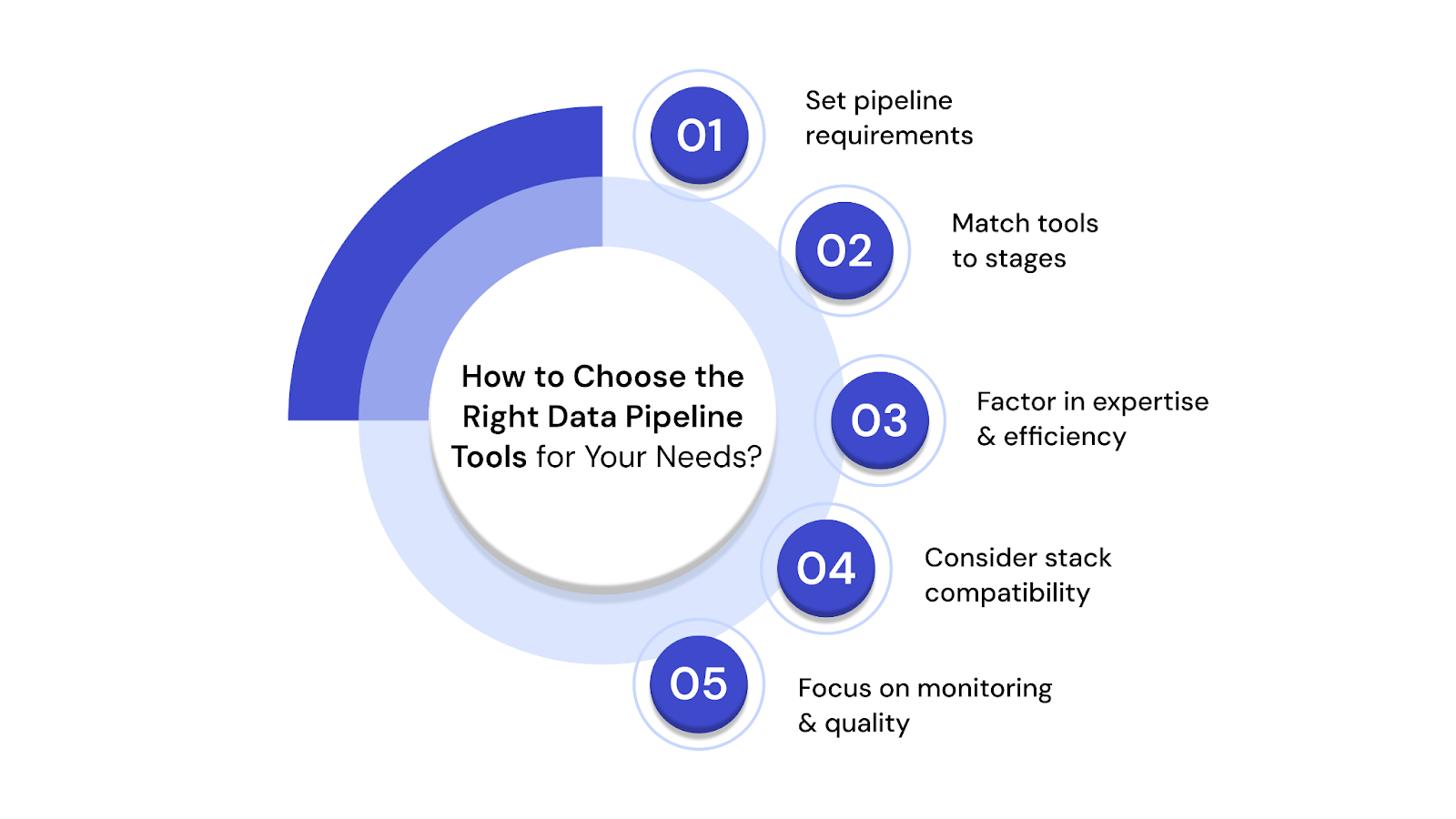
Choosing the right data pipeline tools isn’t just about brand names or feature lists. It’s about finding what fits your data flow, team skills, and business goals. The wrong choice can lead to slow pipelines, integration issues, and higher costs.
Before you pick a tool, evaluate your data strategy, existing infrastructure, and team maturity. The best tool is the one that adapts to your needs without slowing your team down.
With the right tools in place, your pipelines won’t just run, they’ll scale, adapt, and keep delivering accurate data across the board.
The right data pipeline tools help your team focus on insights instead of getting caught up in infrastructure. If your priority is real-time analytics or consistent batch processing, the key lies in choosing tools that align with your specific goals.
This guide outlined top data pipeline tools for 2025 along with factors to consider before making a choice. From open-source frameworks to managed platforms, the objective remains the same: build stable and scalable pipelines that power your data and support business growth.
Data Pipeline Tools with QuartileX
At QuartileX, we help you choose and implement data pipeline tools that align with your business goals. Whether you’re handling real-time transactions, building machine learning pipelines, or syncing BI dashboards, we provide:
We don’t believe in one-size-fits-all tools. Our team tailors data stacks that are reliable, future-ready, and built to meet your specific data challenges.
Struggling with integration issues or slow data sync? QuartileX can help you modernize your pipeline setup with expert-backed, tool-agnostic solutions.
Connect with us to build high-performance pipelines that grow with your business.
We help forward-thinking teams build secure, scalable systems for analytics, AI, and business agility.
Start Your Modernization Journey →
These tools automate the flow of data from various sources to storage or reporting systems. They handle ingestion, transformation, validation, and orchestration to support clean and consistent data delivery.
Yes, many teams use a hybrid setup. For example, Kafka may handle ingestion, Spark performs the processing, and Snowflake serves as the data warehouse. This setup offers flexibility and performance if properly integrated.
Look into its connector support, deployment options, and compatibility with your current infrastructure. Tools that integrate easily with your cloud services, data formats, and scheduling systems can reduce engineering effort.
Managed tools like BigQuery, AWS Glue, or Hevo work well for teams with limited resources. They reduce manual setup, offer built-in scalability, and simplify operations without needing deep infrastructure knowledge.
Common signs include frequent errors, long processing times, limited scalability, and lack of integration with other tools in your workflow. These problems often lead to delays, data quality issues, and higher maintenance costs.
No, dbt handles only analytics transformations after data is loaded into a warehouse. It does not manage data ingestion, movement, or orchestration. For full coverage, dbt is typically used with tools like Airflow or Fivetran.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


