
.png)

Businesses often struggle to make confident decisions when their data isn't reliable. Transforming raw, fragmented information into insights you can trust is a significant hurdle. In fact, 67% of organizations don't completely trust their data for decision-making, according to a Precisely 2025 Outlook report. This lack of confidence directly impacts agility and growth.
Here’s where dbt (Data Build Tool) changes the game for data transformation.
This blog will explain how dbt enables data teams to build robust, high-quality data models right within your data warehouse. Learn how dbt ensures your business operates with trustworthy data, leading to decisive and impactful outcomes.
dbt, or Data Build Tool, is an open-source command-line tool that empowers data analysts and engineers to transform, test, and document data directly within their cloud data warehouses. It functions by allowing them to write modular SQL SELECT statements, which dbt then compiles into tables and views.
The primary purpose of dbt is to bring software engineering best practices, such as version control, automated testing, and clear documentation, to the crucial process of data transformation. This approach helps ensure that your organization's data assets are not only reliable and accurate but also consistently ready for robust analytics and decision-making.
Also read: Data Lake vs. Data Warehouse: Key Differences for Smarter Data Management
Timely and reliable data is now a necessity for any business, not just an advantage. Yet, many organizations find themselves wrestling with significant challenges in their data transformation processes. These aren't just technical hiccups; they translate directly into tangible business problems:
dbt directly confronts these challenges by introducing principles from software engineering into the data transformation layer. It brings structure, testing, and collaboration to your data work, transforming chaotic data pipelines into a reliable, efficient, and trustworthy foundation for your business intelligence and advanced analytics.
We help forward-thinking teams build secure, scalable systems for analytics, AI, and business agility.
Start Your Modernization Journey →
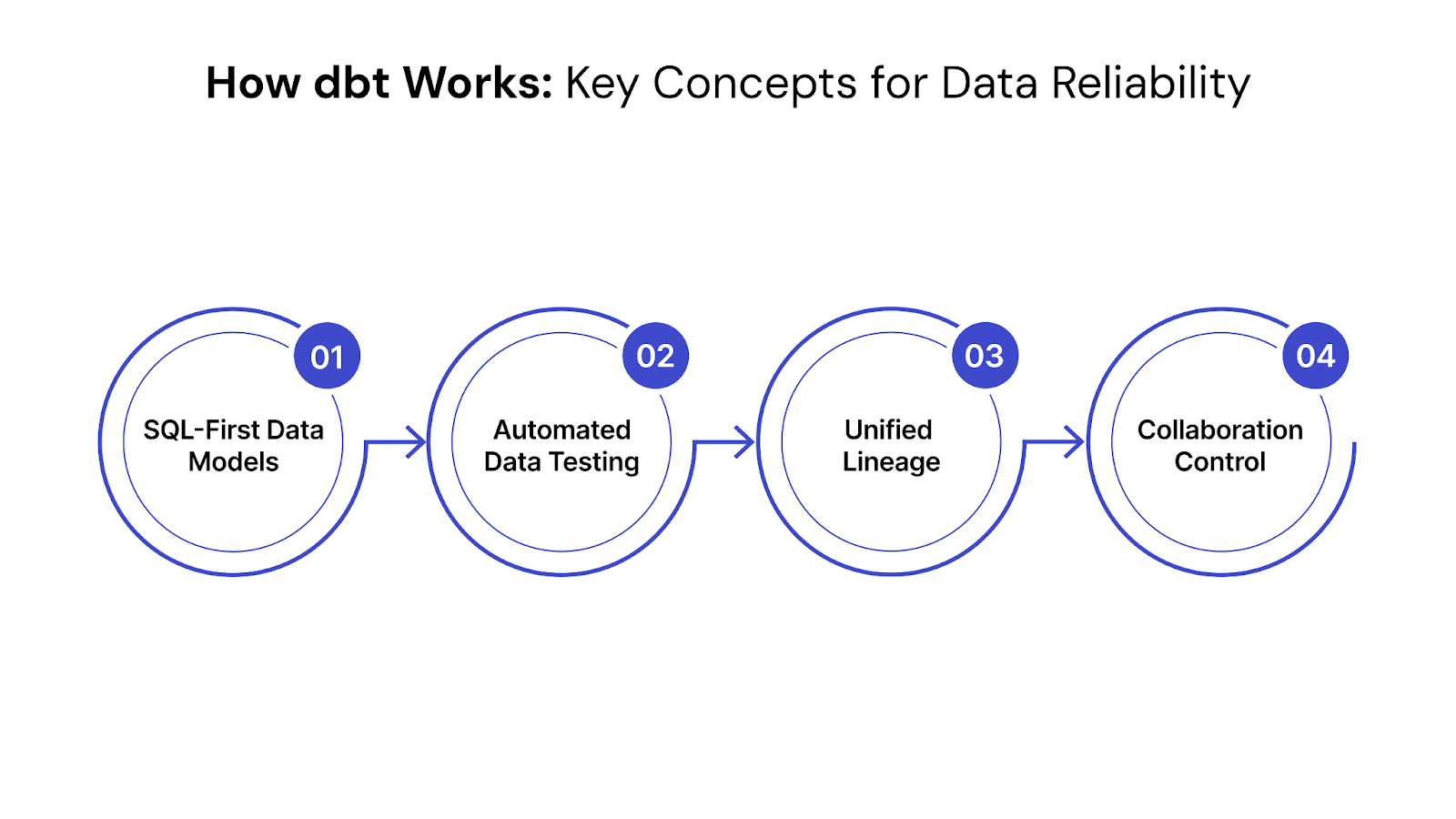
dbt’s power lies in its ability to bring structure and discipline to your data transformation layer, directly contributing to the reliability and trustworthiness of your analytics. It achieves this through a few key pillars:
At the heart of dbt are data models, which are essentially just SQL code. Instead of writing complex, monolithic scripts, dbt encourages you to break down your data transformations into smaller, modular SQL queries.
Each model defines a specific piece of business logic or data preparation step. For instance, one model might clean customer data, while another might aggregate sales figures.
Once your data models (transformations) are executed by dbt and built in the data warehouse, a critical next step is ensuring their quality. dbt facilitates this by allowing you to define and run automated data tests directly against this newly prepared data.
These tests, defined using SQL, check for common data quality issues such as ensuring that customer IDs are always unique, revenue figures are never negative, or critical fields are never null.
dbt enables you to write documentation alongside your data models. This documentation is then automatically compiled into a searchable website that includes detailed descriptions of your tables, columns, and transformation logic.
Even more powerfully, dbt automatically generates a visual data lineage graph, showing how every piece of data flows from its raw source through various transformations.
dbt integrates seamlessly with standard version control systems like Git. This means every change to your data transformation code is tracked, allowing teams to collaborate effectively on data models. You can see who changed what, when, and why, and even roll back to previous versions if needed.
With these concepts, let’s see how dbt plays a pivotal role in this changing data landscape.
Also read: Tips on Building and Designing Scalable Data Pipelines
dbt has carved out a distinct and critical niche in the modern data stack, fundamentally reshaping how organizations manage and utilize their data. It primarily functions as the "Transform" layer in the popular ELT (Extract, Load, Transform) paradigm.
Data is first extracted from various sources and loaded directly into a powerful cloud data warehouse (like Snowflake, Google BigQuery, or Amazon Redshift). It's within this robust, scalable environment that dbt then executes all the complex data transformations.
This focus on in-warehouse transformation empowers data teams to build on the full compute power and flexibility of their cloud infrastructure, avoiding the need for separate, often costly, processing engines.
Crucially, dbt has been instrumental in the emergence and standardization of the Analytics Engineering discipline. Historically, data engineers focused on infrastructure and raw data pipelines, while data analysts built reports. Analytics Engineering bridges this gap:
Ultimately, dbt redefines how data teams operate, moving them from reactive reporting to proactive data product development.
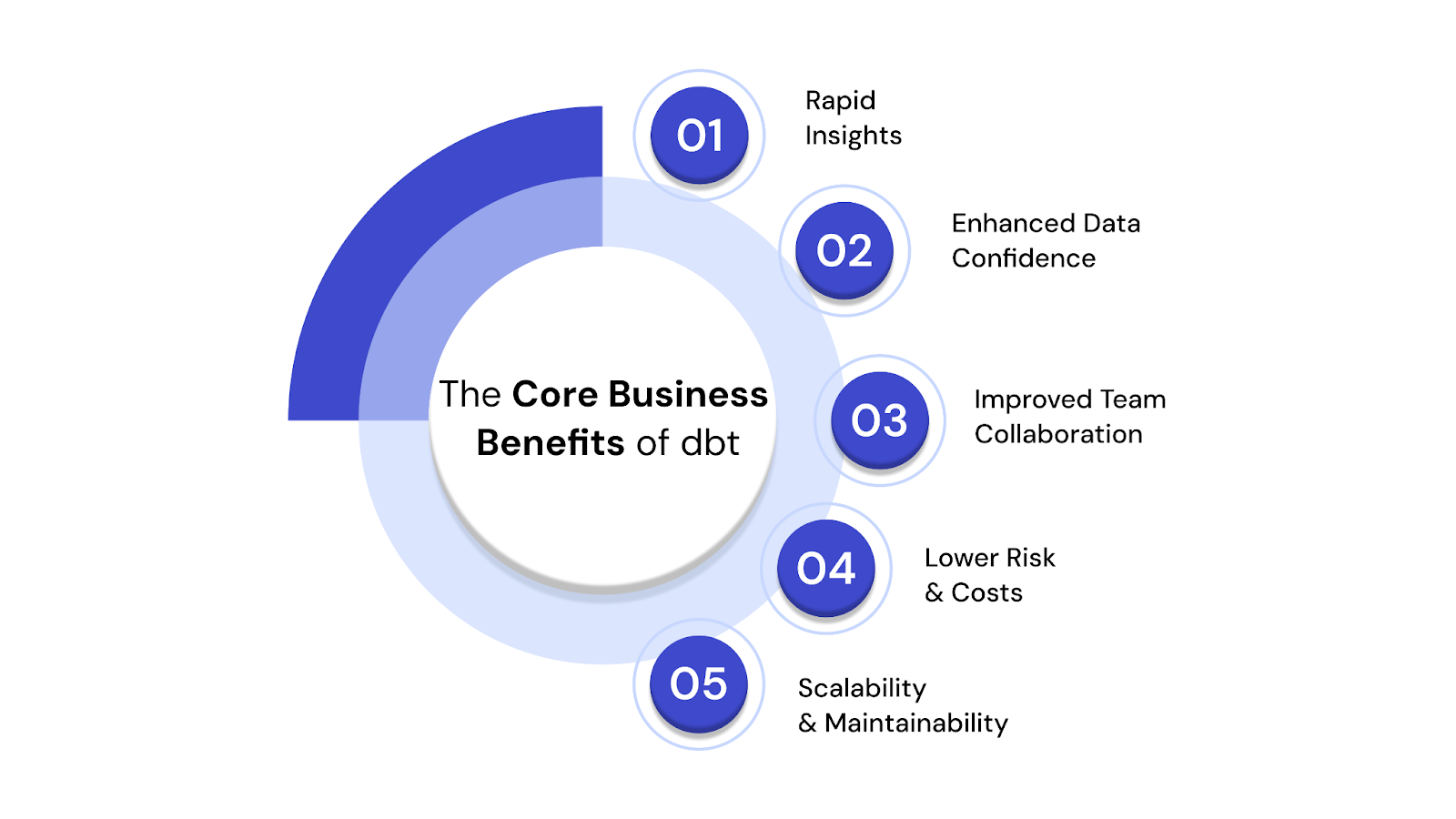
Beyond its technical elegance, dbt offers tangible benefits that directly translate into significant business value. By adopting dbt, organizations can fundamentally improve how they derive insights and operate:
These benefits collectively make a compelling case for dbt as a cornerstone of modern data strategy, driving real business outcomes.
Build a governance framework that not only meets compliance needs but drives trust, transparency, and business value from your data.
Build Your Governance Framework →
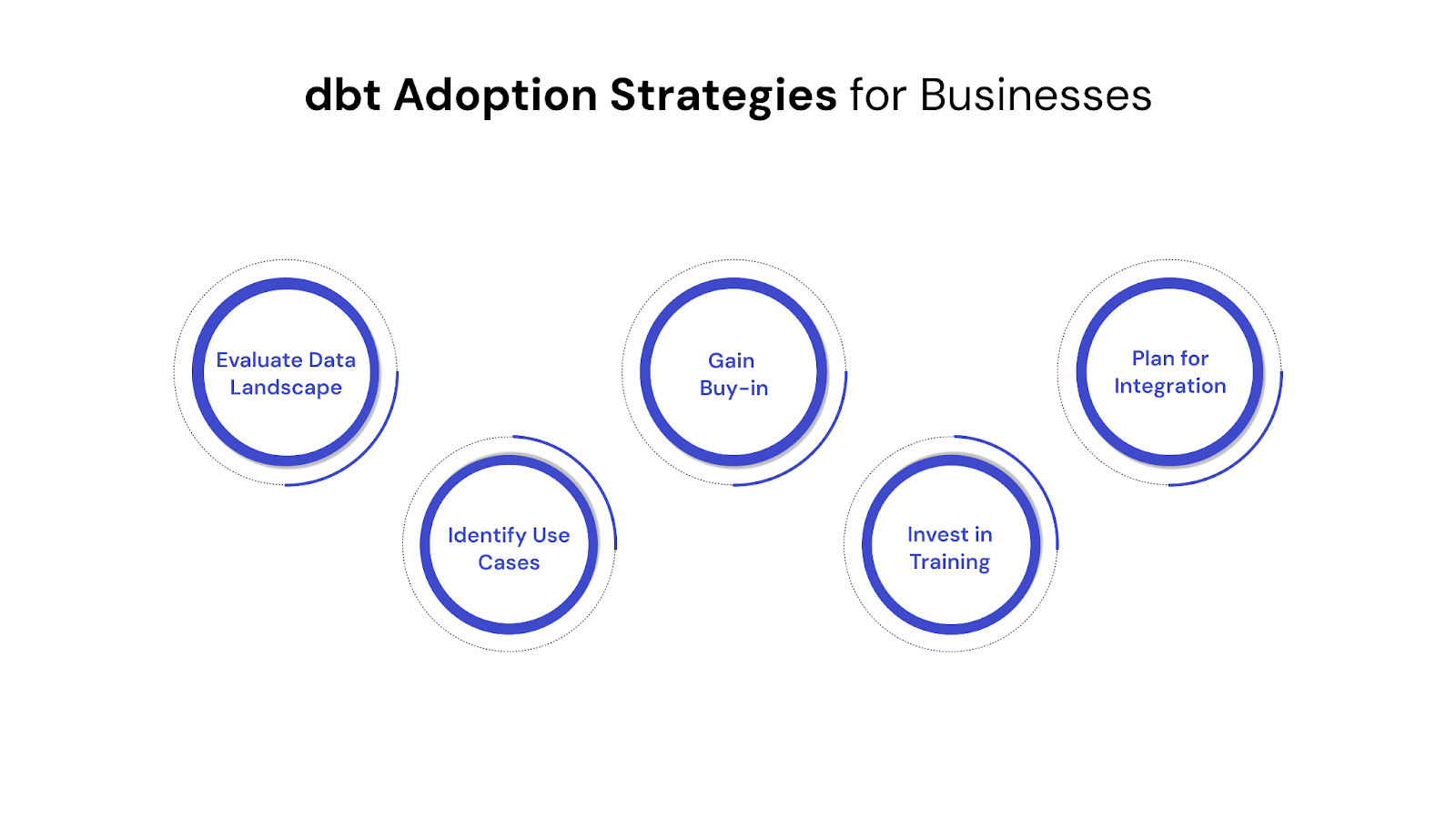
Adopting dbt isn't merely about implementing a new tool; it's a strategic move that involves rethinking your data transformation processes and fostering a data-centric culture. For businesses looking to maximize dbt's benefits, a thoughtful approach to adoption is key:
By approaching dbt adoption strategically, businesses can ensure a smoother transition, build a robust and reliable data foundation, and truly unlock the potential of their data assets for sustained competitive advantage.
Turn raw data into strategic insights with real-time dashboards and data storytelling built for fast, confident decision-making.
View Visualization Solutions →
Transforming raw data into a reliable strategic asset is the ultimate goal for any business, and dbt provides the blueprint. By embedding software engineering best practices into data transformation, dbt ensures your data is not only accessible but also reliable, consistent, and ready for immediate use. This fosters an environment of profound trust, enabling faster, more confident, and ultimately, more impactful decisions across your organization.
Embracing dbt represents a significant step towards data maturity. It helps bridge the gap between raw information and actionable intelligence, establishing a single source of truth for your most critical business metrics. For any organization striving for agility, enhanced data governance, and a sustained competitive edge, dbt is no longer a luxury but an essential component of a modern, efficient data strategy.
Partnering with QuartileX for Your dbt Transformation
While dbt democratizes data transformation, navigating its full capabilities and integrating it seamlessly into your existing ecosystem requires specialized expertise. This is where QuartileX steps in. We partner with businesses like yours to design, implement, and optimize robust data solutions that align perfectly with your strategic goals.
Here's how QuartileX aligns with your data transformation needs:
Secure your competitive edge with truly reliable data. Contact QuartileX today to discuss how we can help you build a trusted, efficient, and future-proof data foundation with dbt.
dbt empowers your data team to transform raw data into reliable, tested, and well-documented datasets directly within your cloud data warehouse. This ensures your business decisions are based on accurate and trustworthy information.
dbt isn't a full ETL (Extract, Transform, Load) tool; it specializes in the "Transform" layer of the ELT (Extract, Load, Transform) process. It works within your data warehouse and brings software engineering best practices to your data modeling.
dbt allows for automated data testing directly on your transformed data. By defining and running tests for data quality issues (like uniqueness or null values), it catches errors immediately after transformation, preventing flawed data from reaching your reports and dashboards.
dbt is primarily used by data analysts and analytics engineers. It allows them to collaborate on building robust data models, define metrics consistently, and manage transformations using familiar SQL, bridging the gap between raw data and business intelligence.
Key benefits include accelerated insights, increased data trust and confidence, enhanced team efficiency, reduced operational risk from data errors, and improved scalability and maintainability of your data pipelines, all leading to more informed and agile business decisions.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


