


For many businesses, the promise of data-driven transformation remains just that—a promise. Despite significant investments in analytics and AI, nearly half of AI proof-of-concepts (46%) are scrapped before reaching production, turning potential breakthroughs into costly setbacks. This widespread challenge isn't merely about complex algorithms or brilliant ideas; it's often rooted in the fundamental inability to reliably move, transform, and deliver data at the required scale and speed.
This guide will illuminate the essential practices for building robust, scalable data pipelines. Discover how to transform your raw data into an agile, reliable asset that fuels real-time decision-making, optimizes operations, and ensures your enterprise is poised for future growth and innovation.
A data pipeline is an automated sequence of processes that systematically ingests raw data from diverse sources, transforms it into a usable format, and loads it into a target destination for analysis, reporting, or operational applications. It functions as the foundational infrastructure for data movement and preparation within an organization.
A scalable data pipeline takes this a step further. It is specifically engineered to handle increasing data volumes, velocities, and varieties without compromising performance, reliability, or cost-efficiency. This means it can seamlessly expand or contract its capacity based on demand, integrate new data sources with ease, and maintain consistent data quality even as your business scales.

The necessity to scale these pipelines arises directly from modern business demands. As data volumes explode, velocity increases, and data types diversify, unscalable pipelines become critical bottlenecks. This leads to slow processing, data inaccuracies, and inefficient resource utilization.
Scaling your data pipelines offers the following benefits for your business:
To understand how these high-quality data feeds are critical for the successful deployment and management of AI models, read our detailed article on MLOps Principles and Automation Pipelines.
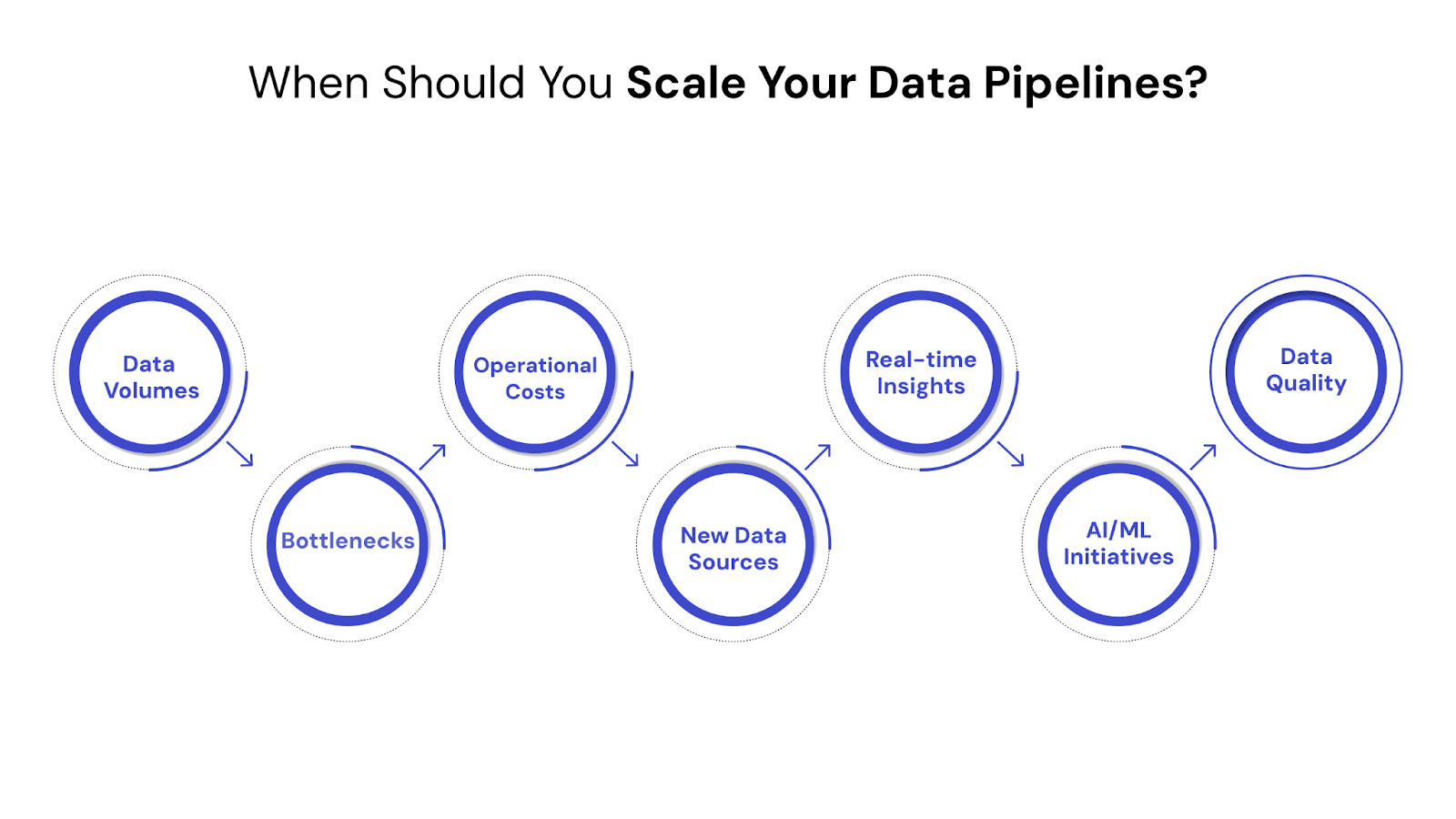
Recognizing the symptoms of an unscalable data infrastructure is the first step toward building a robust, future-ready system. As your business evolves, certain indicators will signal that your current data pipelines are struggling to keep pace, necessitating an investment in scalability.
Look out for these critical signs:
Optimize your data infrastructure with modern pipelines and architecture that enable faster analytics and smarter decisions at scale.
Future-Proof Your Data Stack →
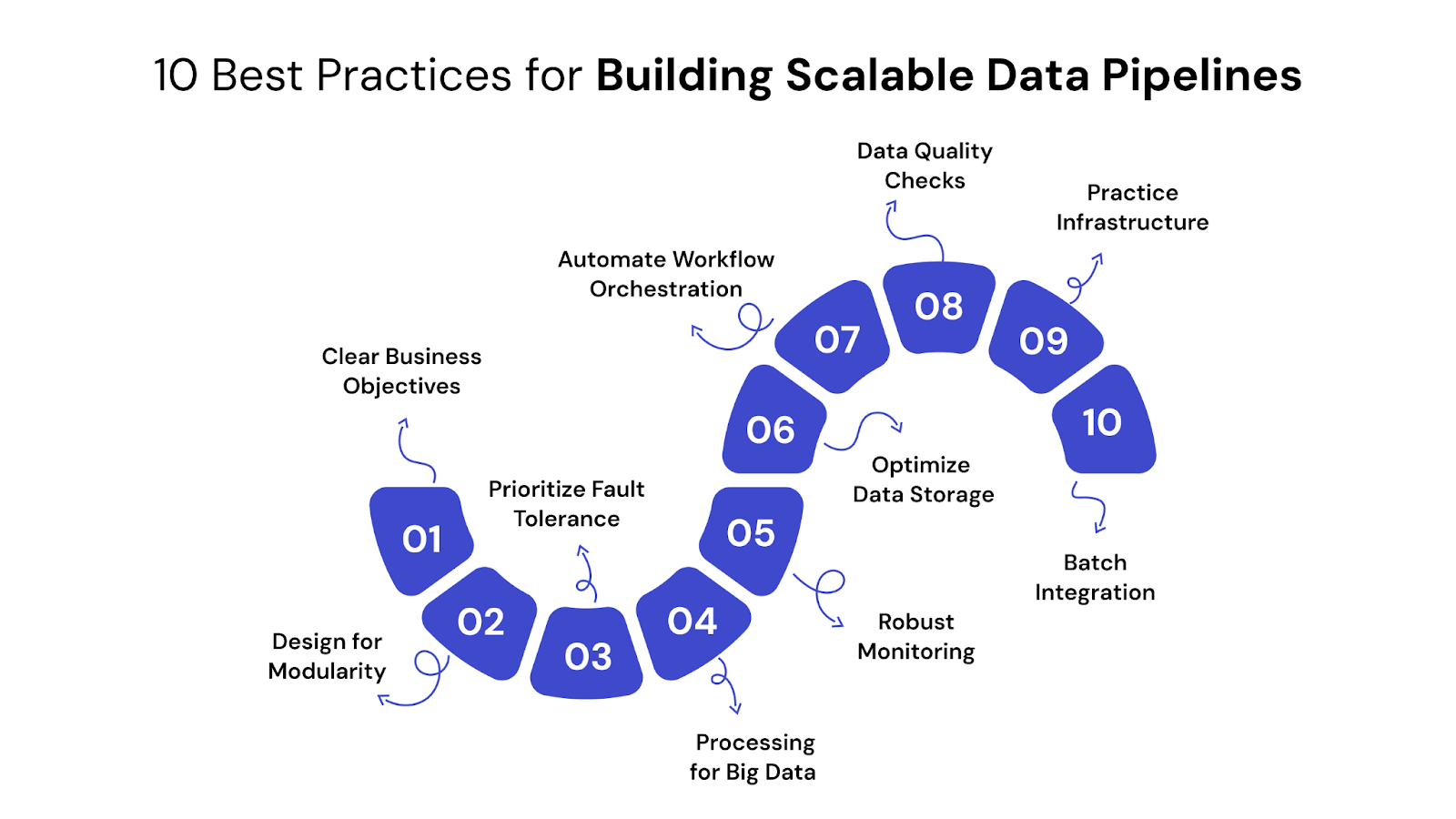
Building scalable data pipelines requires more than just connecting tools; it demands a strategic approach grounded in proven engineering principles. Here are the essential practices that form the blueprint for a robust, future-ready data infrastructure:
A scalable data pipeline's success is fundamentally tied to well-defined business goals. Before selecting technologies or designing architectures, clearly articulate the specific problems you aim to solve and the value those solutions will bring. This foundational step ensures your data efforts directly support strategic outcomes, preventing misaligned projects.
For instance, Netflix's highly personalized recommendation engine relies on data pipelines specifically designed to capture and process real-time user viewing habits. This direct alignment with their objective of enhancing user experience and retention showcases how clear goals drive effective pipeline design.
A scalable data pipeline consists of independent, specialized components rather than a single, tightly integrated system. This involves breaking down complex data flows into smaller, manageable, and reusable units for distinct tasks like data ingestion, transformation, and loading.
This modular approach offers significant advantages for scalability and maintenance:
Adopting a decoupled architecture, where components communicate through well-defined interfaces (like message queues or APIs), is crucial for enabling this flexibility.
In any large-scale data system, failures are inevitable, whether due to network issues, infrastructure outages, or unexpected data anomalies. A scalable pipeline is engineered not to prevent all failures, but to recover from them without data loss or significant disruption to data flow.
Implementing robust fault tolerance mechanisms is critical for maintaining data integrity and ensuring continuous operation:
Curious about the specific technologies that underpin these resilient and scalable architectures? Explore our list of Top Data Pipeline Tools.
When handling vast and rapidly growing data volumes, a single machine's processing power quickly becomes insufficient. Distributed processing is fundamental for scalability, enabling data tasks to be broken down and executed simultaneously across a cluster of interconnected machines.
This approach significantly accelerates data throughput and enables handling petabytes of data:
Technologies like Apache Spark and Apache Flink are industry standards for distributed data processing. Cloud services such as AWS Glue and Google Cloud Dataflow offer managed solutions that abstract away much of the underlying infrastructure complexity.
You can't effectively manage what you can't see. Comprehensive monitoring and observability are crucial for understanding the health, performance, and data quality of your pipelines in real time. This proactive approach allows you to identify bottlenecks, potential failures, or data inconsistencies before they impact business operations.
Effective observability covers several key areas:
Platforms like Prometheus and Grafana are widely used for infrastructure monitoring. For deeper insights into data health, consider specialized data observability solutions such as Monte Carlo, Acceldata, or Soda.
Build high-performance pipelines that keep your data flowing reliably — from ingestion to insight.
Build with Data Engineering →
The choice and optimization of your data storage layers significantly impact pipeline performance and cost-efficiency. Different data needs often require different storage solutions (e.g., raw data lakes, structured data warehouses, or hybrid lakehouse architectures).
Here’s what strategic storage optimization involves:
Consider managed service partners like QuartileX, who offer AI-powered cloud optimization and auto-scaling to ensure your system adapts seamlessly to fluctuating data loads while controlling costs.
Example: Airbnb significantly optimized query performance and reduced costs in their data lake by storing data in Parquet format and implementing effective partitioning strategies, making their data readily available for analysis.
Manually managing complex data pipeline dependencies, execution order, and scheduling is highly inefficient and prone to error, especially at scale. Workflow orchestration tools automate these processes, ensuring tasks run in the correct sequence and at the right time.
Effective orchestration offers substantial benefits:
Open-source orchestrators like Apache Airflow or Prefect, and cloud-managed services such as AWS Step Functions, Azure Data Factory, or Google Cloud Composer, are designed for managing complex and scalable data workflows.
The reliability of your data-driven decisions hinges on the quality of your data. Ensuring "garbage in, garbage out" doesn't compromise insights requires embedding robust data quality checks and validation processes throughout the pipeline, not just at the end.
Key practices for maintaining high data quality:
Example: Financial institutions utilize stringent data quality checks embedded throughout their transaction processing pipelines to ensure regulatory compliance and prevent fraudulent activities, where even minor inaccuracies can have significant repercussions.
Treating your data pipeline infrastructure and its configuration like software code is fundamental for scalability, consistency, and rapid iteration. Infrastructure as Code (IaC) defines and provisions infrastructure using code, while CI/CD (Continuous Integration/Continuous Delivery) automates the build, test, and deployment processes.
These practices bring significant benefits to data pipeline management:
For IaC, popular tools include Terraform, AWS CloudFormation, and Azure Resource Manager. For CI/CD, consider platforms like Jenkins, GitLab CI/CD, or GitHub Actions, which integrate seamlessly with code repositories.
Modern business often requires a blend of immediate responsiveness and historical analytical depth. A scalable data pipeline architecture should be designed to accommodate both streaming (real-time) and batch processing paradigms, understanding when to leverage each for optimal efficiency and insight delivery.
Key considerations for integrating these two approaches:
Example: E-commerce platforms frequently use real-time pipelines to power instant product recommendations and dynamic inventory updates, while simultaneously running robust batch processes overnight for comprehensive daily sales analytics, customer segmentation, and warehouse optimization.
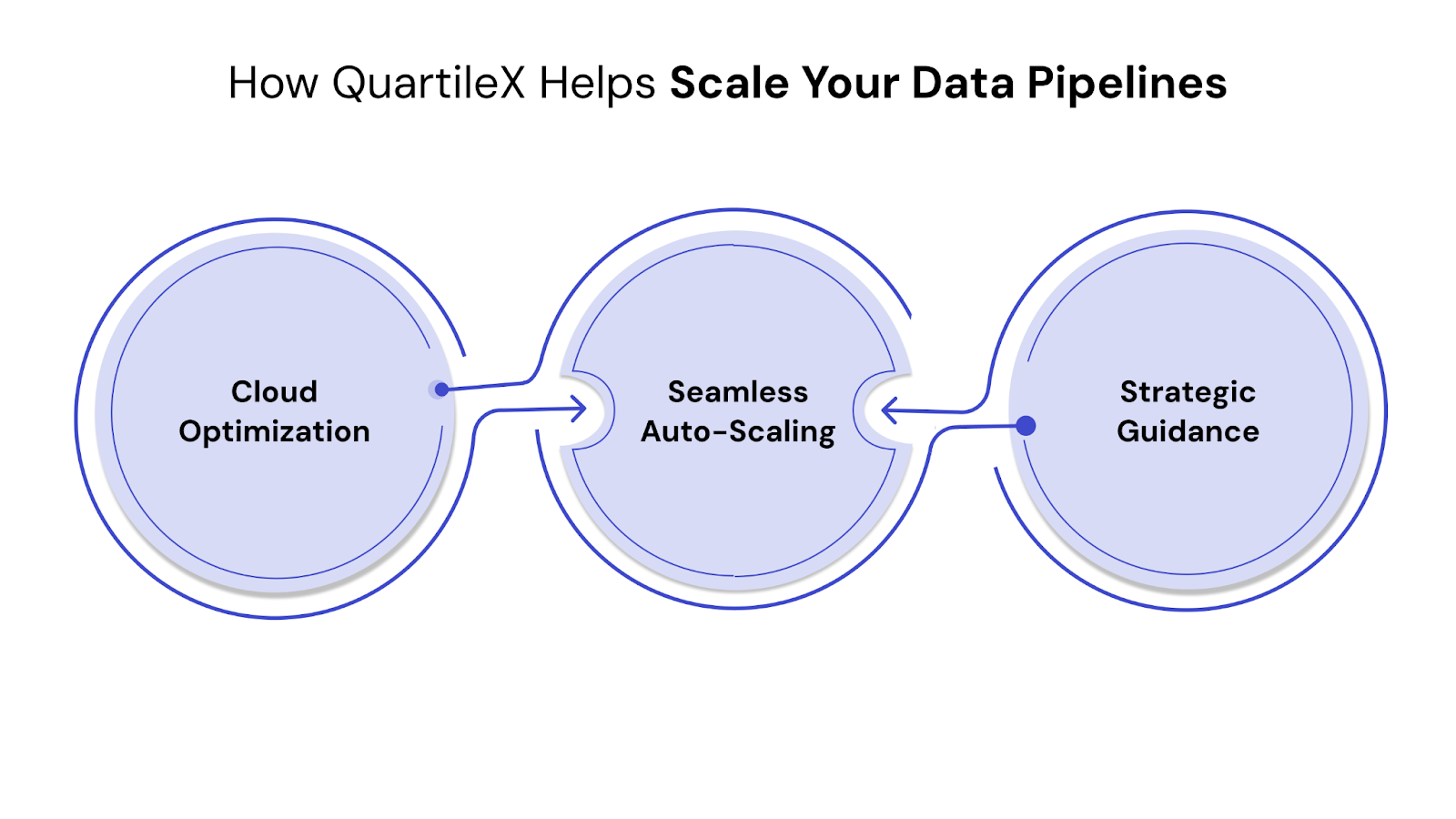
Building scalable data pipelines is a complex endeavor that demands specialized expertise, continuous optimization, and forward-thinking strategies. For many enterprises, navigating this intricate landscape requires a trusted partner.
QuartileX stands apart by combining deep technical proficiency with an unwavering focus on business outcomes. We don't just build pipelines; we engineer intelligent data ecosystems.
Here’s what makes us different:
Partnering with QuartileX means transforming your data challenges into a tangible competitive advantage, ensuring your data infrastructure is not just functional but future-ready.
We don’t just implement technology — we solve real-world problems with intelligent, secure, and scalable solutions.
Let’s Talk Strategy →
The sheer volume of data in modern enterprises presents both immense opportunity and significant challenges. Effectively managing this data is not just a technical task but a core strategic imperative for sustained growth and competitive advantage. By committing to these essential practices, your business can transform data from a bottleneck into a dynamic engine for real-time insights, operational excellence, and unparalleled innovation, ensuring you remain agile and relevant in an ever-accelerating market.
Don't let unscalable data infrastructure hold your enterprise back any longer. The journey to a future-ready data ecosystem begins now, and you don't have to navigate it alone.
Elevate your data strategy: Connect with the experts at QuartileX for a personalized data pipeline scalability assessment and discover your clearest path to unlocking transformative business value.
A data pipeline is a broad concept for automated data movement from source to destination. ETL (Extract, Transform, Load) is a specific type of data pipeline, primarily for batch processing, where data is transformed before loading. All ETL processes are data pipelines, but not all data pipelines are ETL.
Failures often stem from unmanaged schema changes, poor data quality, or overwhelming data volumes and velocity. Insufficient monitoring, complex dependencies, and inadequate error handling also lead to significant bottlenecks, hindering data flow.
Data observability provides deep, real-time visibility into pipeline health, performance, and data quality. It enables proactive identification of bottlenecks and anomalies, preventing issues before they impact downstream consumers. This ensures reliable and consistent data flow at scale.
Yes, serverless technologies are highly effective for scaling complex data pipelines. They offer dynamic auto-scaling and abstract server management, enabling cost-efficient, elastic processing for high throughput. This allows seamless integration with other managed cloud services.
Building in-house offers control but demands significant investment in talent and maintenance. Managed services or partners reduce operational overhead, provide expert access, and accelerate development. The best choice depends on your organization's resources, expertise, and strategic focus.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


