


Data is no longer just an operational byproduct — it's central to how companies innovate, scale, and make decisions. With global data generation expected to exceed 394 zettabytes by 2028, the demand for systems that collect, process, and deliver accurate information is rising fast. But raw data on its own doesn’t drive outcomes. It’s the structure behind it — the pipelines, quality controls, integrations, and infrastructure — that determines its value.
That’s where data engineering comes in.
In this guide, we’ll walk through the essentials of data engineering — what it is, how it works, the technologies it relies on, and how organizations are using it to build scalable, reliable data ecosystems.
TL;DR — Key Takeaways
Data engineering is the discipline of designing, building, and managing systems that collect, transform, store, and serve data at scale. Its primary goal is to ensure that data is accurate, accessible, and ready for use by analysts, data scientists, applications, and business teams.
While data scientists focus on interpreting data, data engineers build the foundation that makes that interpretation possible. From real-time data streaming in finance to batch processing in retail analytics, data engineering is the framework that supports modern decision-making.
At its core, data engineering is responsible for:
This function is especially critical in businesses that deal with large volumes of data across multiple systems, departments, or regions. Without strong engineering practices in place, data tends to become fragmented, outdated, or unusable leading to costly missteps.
Streamline your data pipelines and architecture with scalable, reliable engineering solutions designed for modern analytics.
See Data Engineering Services →
Use Case:
Consider an e-commerce platform managing customer data, order history, product inventory, and delivery timelines. For marketing, logistics, and sales to function seamlessly, the underlying systems must ensure that all of this data flows in real time and stays accurate across departments. That orchestration is the result of solid data engineering.
If you're interested in understanding how the initial part of this process works — particularly moving data from multiple sources into a unified pipeline — you can read our guide on Data Ingestion here.
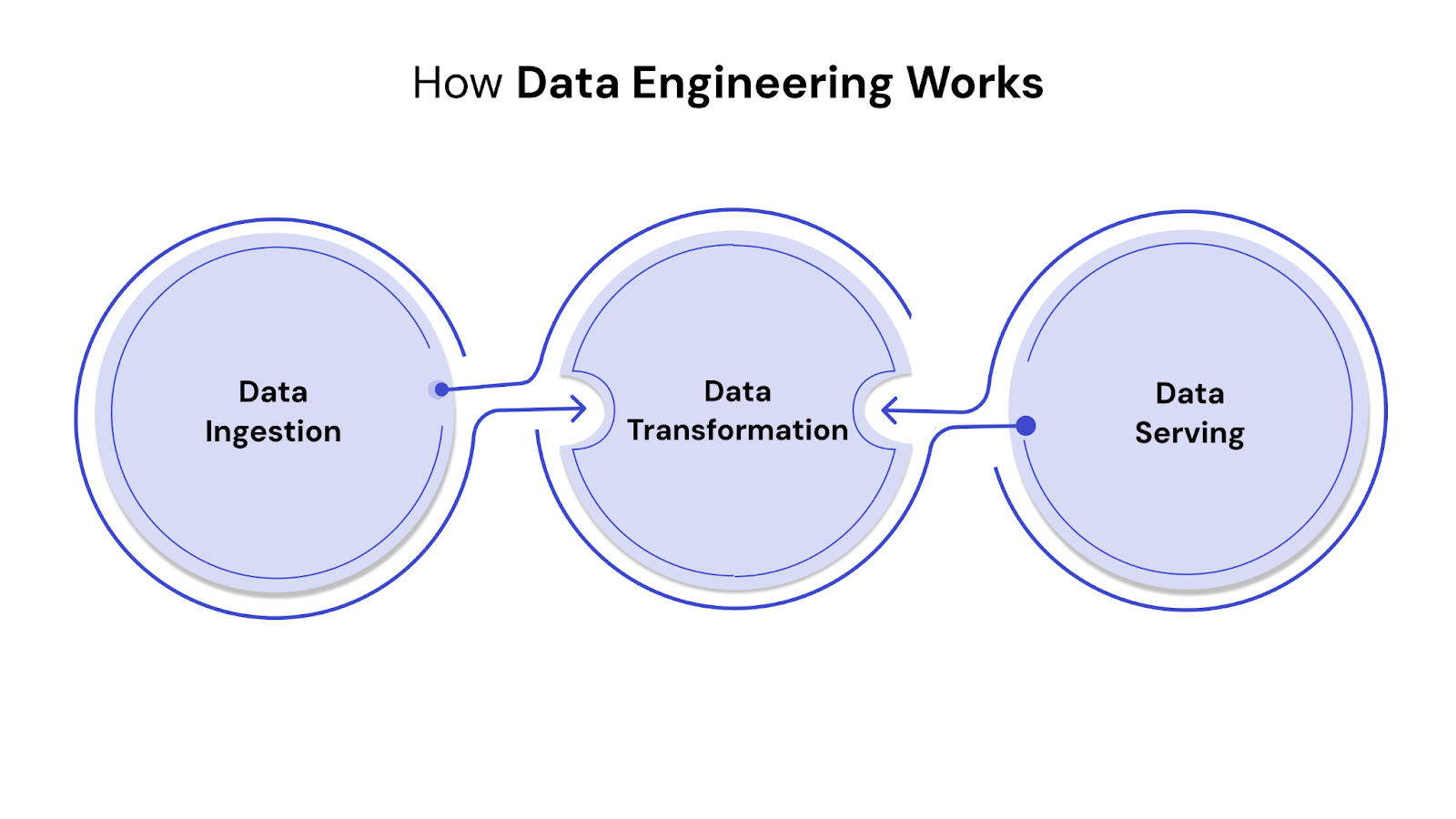
Data engineering is more than just moving data from one place to another — it’s about architecting resilient systems that handle scale, complexity, and change. At a high level, data engineering workflows involve three foundational stages:
This is the entry point — bringing data in from internal systems (like CRMs, ERPs, IoT devices) or external sources (APIs, partner systems, third-party datasets). Depending on use case, ingestion can be real-time (streaming) or batch-based. Tools like Apache Kafka, AWS Kinesis, and Flume are common in this phase.
Once ingested, raw data is rarely usable. It may be incomplete, inconsistent, or poorly structured. Transformation involves cleaning, normalizing, enriching, and reformatting data so it fits downstream use cases — whether that’s BI reporting, analytics, or machine learning models.
To dive deeper into this, check out our blog on preparing data for AI, where transformation plays a pivotal role in model accuracy and readiness.
After transformation, data needs to be accessible to teams and tools. This stage involves pushing data into warehouses, lakes, or APIs that serve reports, dashboards, or applications. The goal is to deliver clean, timely data where it’s needed, whether to a business analyst using Tableau or a machine learning model updating forecasts.
To build systems that handle modern data volumes and complexity, data engineers rely on several interconnected elements. These define the structure and success of any data platform.

Data may originate from dozens of sources — clickstreams, transactions, sensor networks, customer interactions. Engineers must build reliable connectors that pull this data without loss or delay, handling both structured (SQL databases) and unstructured formats (logs, documents, audio, etc.).
Data engineers design storage systems based on speed, cost, volume, and access needs. Common storage solutions include:
Each has trade-offs, and most mature architectures blend these depending on team needs.
Data must be transformed before it’s usable. This includes validation, cleansing, enrichment, and aggregation. Engineers use frameworks like Apache Spark, dbt, or Pandas for batch processing, and tools like Kafka Streams or Flink for real-time pipelines.
Bringing together disparate data sources is a core part of the job. Data integration ensures that sales, marketing, finance, and product teams are all using the same version of the truth. ETL/ELT tools like Fivetran, Stitch, or Airbyte help standardize this flow.
Curious about data pipeline architectures and how to build them? Explore our blog on building data pipelines from scratch.
Poor quality data leads to poor decisions. Engineers establish validation rules, monitor pipelines for anomalies, and define governance protocols to ensure accuracy, lineage, and accountability. This includes tagging sensitive fields, creating data catalogs, and tracking data provenance.
Data engineers also enforce access controls, encryption, and audit logs to protect sensitive data. Compliance with regulations like GDPR, HIPAA, and SOC 2 is a non-negotiable for most industries — especially finance, healthcare, and government.
Modern data engineering isn’t possible without the right tech stack. From ingestion to orchestration, every layer of the data lifecycle is powered by purpose-built tools. Below, we break them down by functionality:
Managing dependencies across data pipelines is crucial. Tools like Apache Airflow, Prefect, and Dagster help schedule, monitor, and manage complex workflows, ensuring that each task runs in sequence and on time.
In use cases where data freshness matters (think fraud detection, stock trading, or IoT monitoring), real-time processing tools like Apache Kafka, Apache Flink, and Spark Streaming are essential. They enable stream-based transformations, allowing insights as data arrives.
Optimize your data infrastructure with modern pipelines and architecture that enable faster analytics and smarter decisions at scale.
Future-Proof Your Data Stack →
A data engineer’s toolbox isn’t complete without strong coding skills. These languages form the foundation of most data workflows:

The data engineering landscape is rapidly evolving. With growing demand for real-time insights, AI integration, and scalable operations, here are some of the key trends redefining how modern data teams work:
Borrowed from DevOps, DataOps focuses on collaboration, automation, and monitoring across data pipeline development and deployment. It helps teams streamline handoffs between data engineers, analysts, and stakeholders while reducing errors and delays.
Why it matters:
DataOps ensures faster iteration cycles, fewer bottlenecks, and a more proactive approach to pipeline management. It’s becoming especially relevant in environments where analytics and machine learning models are deployed frequently.
For a deeper dive into optimizing data pipelines for agility, check out this blog on modern data orchestration.
Traditional pipeline monitoring can’t keep up with today’s scale and complexity. This is where data observability tools step in, offering end-to-end visibility into pipeline health, data freshness, quality metrics, and anomalies.
Tools leading the space:
Monte Carlo, Databand, and Bigeye are notable players helping data teams detect silent data failures before they reach stakeholders.
LLMs like GPT and Claude are starting to influence data engineering in several ways:
While LLMs aren’t replacing engineers, they’re augmenting productivity by reducing time spent on repetitive or boilerplate tasks.
Modern pipelines increasingly rely on metadata — lineage, ownership, freshness, and classification — to optimize operations and compliance. This has led to the rise of metadata management platforms and tools like Apache Atlas, Amundsen, and OpenMetadata.
Combining the flexibility of data lakes with the performance of data warehouses, data lakehouses are growing in popularity. Platforms like Databricks Lakehouse and Snowflake offer unified architectures that support both raw and analytical workloads without moving data around.
Curious how this model compares with more traditional architectures? We explain the distinction between data lakes and warehouses here.
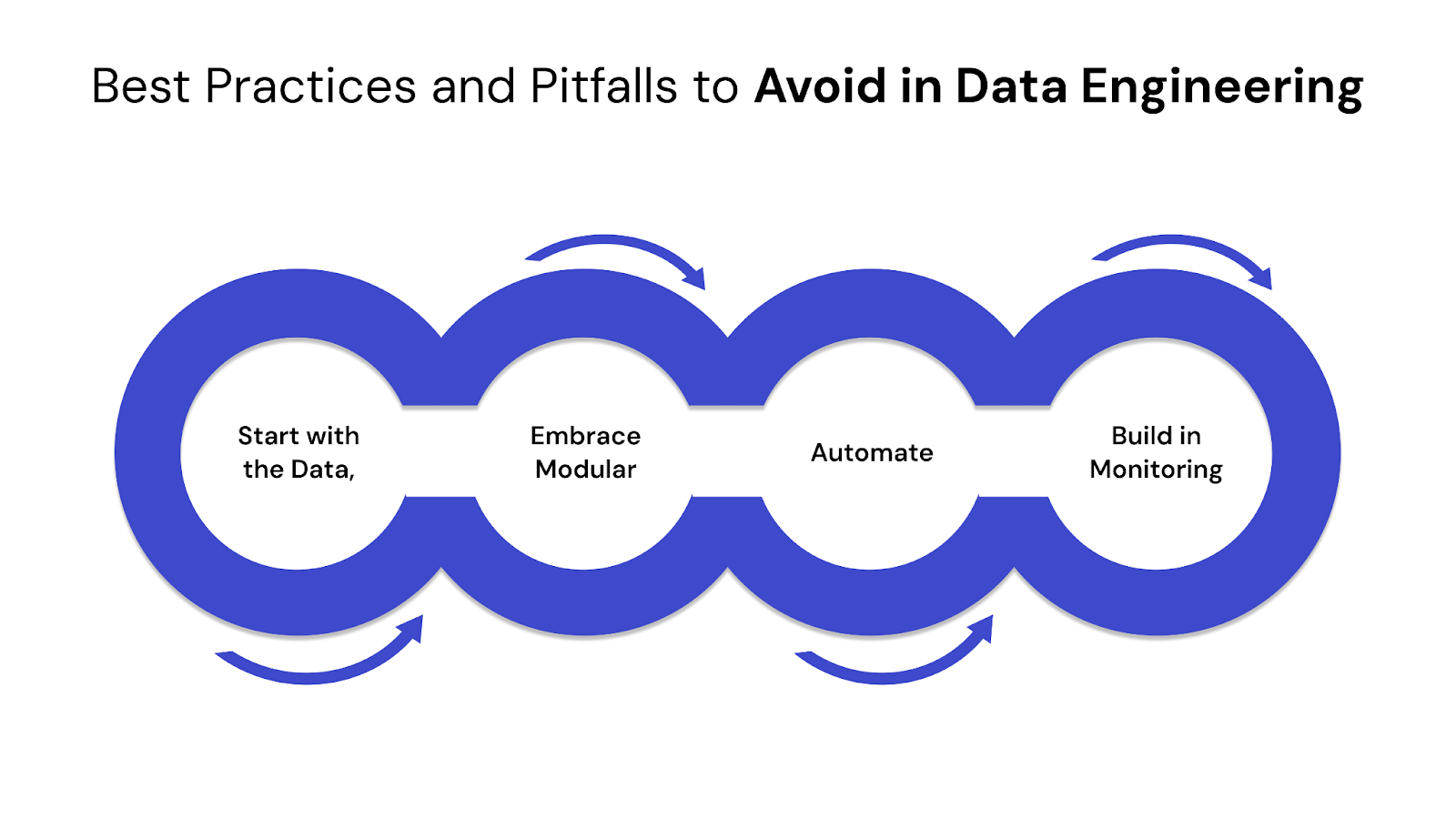
Even the most well-designed architecture can fail if not executed with discipline. Below are proven practices to follow — and common traps to steer clear of — when building scalable, resilient data pipelines.
1. Start with the Data, Not the Tools
Too often, teams choose tools based on hype rather than fit. Good data engineering begins by understanding the nature of your data, your business goals, and your analytics needs. Only then should you evaluate tools (e.g., Spark vs. Snowflake, dbt vs. Airflow) that align with your specific workflows and team skillsets.
For example, if your data is mostly real-time event streams, Kafka and streaming frameworks may be better suited than batch-first platforms.
2. Embrace Modular and Reusable Pipelines
Design your pipelines like software — modular, testable, and loosely coupled. This allows for easier updates, better debugging, and reusability across teams and use cases.
Best practice: Separate ingestion, transformation, and output into distinct layers. Keep configs and code decoupled, and version everything.
3. Automate Where It Matters
From orchestration (using tools like Airflow) to testing and deployment, automation saves time and prevents human error. Use CI/CD pipelines for data workflows just as you would in software engineering.
Don’t over-engineer, though. Focus automation where you see repetitive or high-risk tasks.
4. Build in Monitoring and Data Validation Early
Don't wait until something breaks. Introduce automated quality checks at ingestion, transformation, and serving stages — validating schema, null values, duplication, freshness, and consistency.
Tip: Use tools like Great Expectations, Monte Carlo, or built-in checks with dbt to flag anomalies before downstream users are affected.
At QuartileX, we believe that strong data engineering isn’t just about moving data. It’s about building resilient systems that support every downstream decision, forecast, and AI model with confidence.
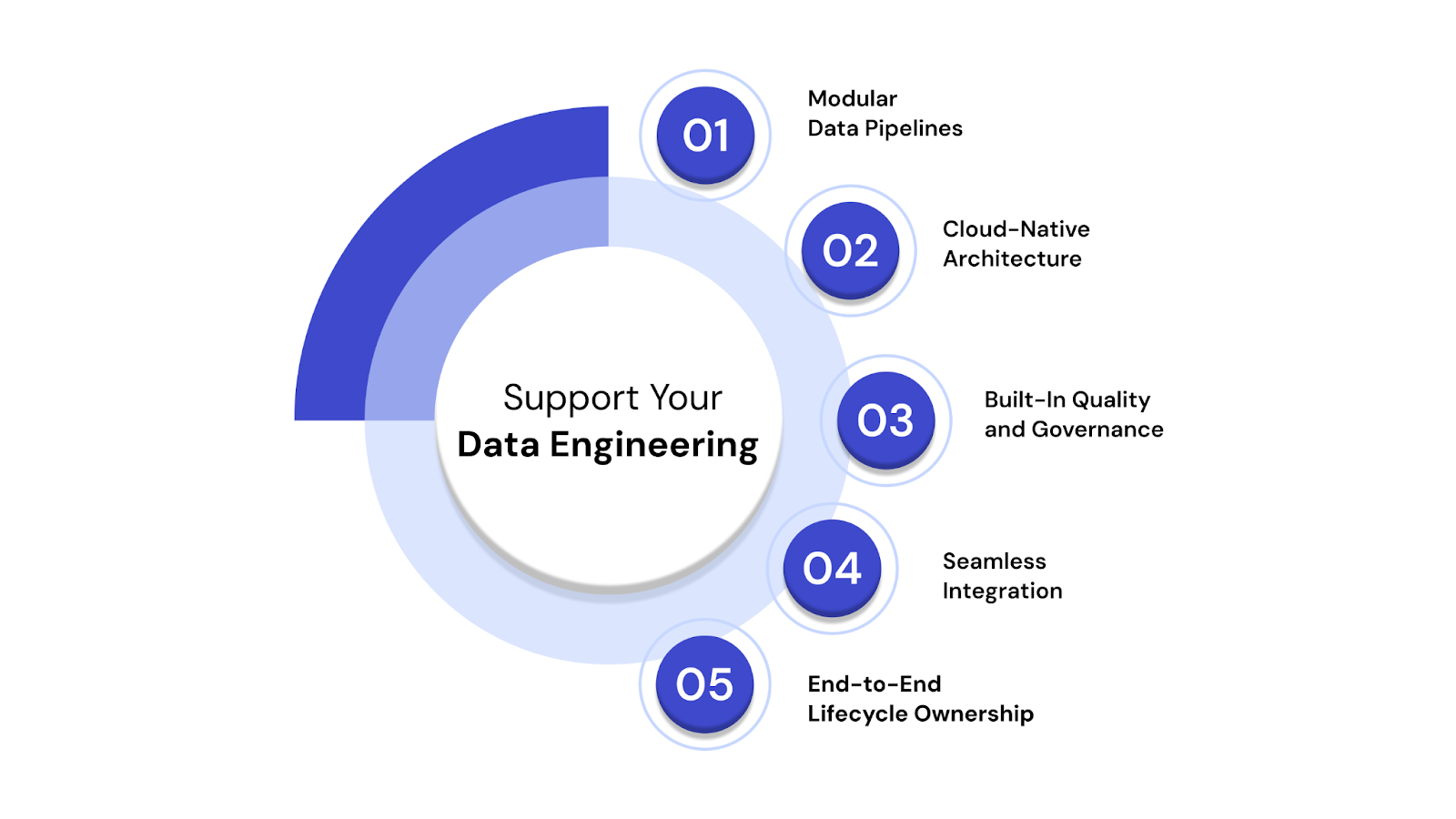
Here’s how we help businesses turn raw data into a strategic advantage:
1. Scalable, Modular Data Pipelines
We design pipelines that scale with your data, not against it. Whether you're dealing with batch or streaming data, our engineers build modular ETL/ELT workflows tailored to your infrastructure.
We also help teams adopt tools like Hevo, Fivetran, or dbt, ensuring faster deployment and easier maintenance of data transformation logic.
2. Cloud-Native Architecture
From Snowflake to Google BigQuery, we align your stack with the right cloud-native solutions, keeping performance high and costs optimized.
Already on the cloud? We help you modernize legacy pipelines or break down data silos using services like AWS Glue or Azure Data Factory.
Not sure where to begin? Our guide to building data pipelines might be a helpful starting point.
3. Built-In Quality and Governance
Every pipeline we deliver includes automated data quality checks, alerting mechanisms, and lineage tracking. This ensures that your data doesn’t just move fast — it moves with context, accuracy, and trust.
Our governance models align with compliance requirements (like GDPR or HIPAA) and support enterprise-scale standards for auditing, access, and retention.
4. Seamless Integration with ML & BI Systems
Data doesn't stop at storage. We make sure your data flows cleanly into analytics and machine learning environments. That includes:
5. End-to-End Lifecycle Ownership
From ingestion design to monitoring and handover, we manage the full lifecycle of your data workflows. Our teams work closely with your stakeholders to ensure pipelines reflect real business logic, not just technical assumptions.
Data engineering is no longer a back-office function — it’s the backbone of how modern companies operate, compete, and grow.
With new trends like DataOps, LLM-powered development, and lakehouse architectures gaining momentum, the discipline continues to evolve rapidly. What remains constant, however, is the need for clean, governed, and accessible data at every stage.
QuartileX helps businesses get there faster and with less friction. Whether you’re building from the ground up or reengineering legacy systems, our data engineering team brings the tools, frameworks, and foresight needed to future-proof your data strategy.
Ready to build smarter with your data?
Talk to a QuartileX expert today and explore how we can elevate your data infrastructure from siloed and slow to scalable and strategic.
Build high-performance pipelines that keep your data flowing reliably — from ingestion to insight.
Build with Data Engineering →
No. While ETL (Extract, Transform, Load) is a key function within data engineering, the discipline extends far beyond it. Data engineers design end-to-end architectures, handle real-time and batch processing, enforce data governance, and manage data quality, storage, and delivery.
If your teams spend more time fixing broken pipelines than analyzing data, or if you're launching AI/ML initiatives without a unified data platform, it’s time to invest in dedicated data engineering.
Tools alone don’t solve structural issues. QuartileX helps connect the dots across ingestion, transformation, monitoring, and governance — ensuring observability, scalability, and reliability as your stack grows.
The modern stack is modular, cloud-native, and designed for scale — using tools like dbt, Snowflake, Airflow, and Kafka. Traditional BI stacks often centralize ETL and analytics in rigid, monolithic platforms.
We help teams implement DataOps workflows with CI/CD pipelines, modular codebases, and validation layers — so analysts and engineers can iterate faster with fewer failures in production.
QuartileX accelerates time-to-value by implementing scalable, production-grade pipelines faster than internal teams starting from scratch. Our modular frameworks reduce rework and technical debt, saving cost over time.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


