


Most companies today collect more data than they know how to use. That data lives in different systems, takes different formats, and often arrives faster than teams can process it. As a result, critical decisions are delayed, and insights stay buried in fragmented datasets.
To turn raw data into something useful — whether for dashboards, forecasting models, or automation — organizations need a reliable system that moves and prepares data in the background. That system is a data pipeline.
Data pipelines are at the core of how modern businesses organize information, reduce manual work, and make their data usable. With the growing demand for real-time analytics, AI models, and cloud-native architecture, having a well-structured pipeline is essential.
TL;DR – Key Takeaways
A data pipeline is a structured set of processes that automatically moves and transforms data from one system to another — typically from its source to a centralized location like a data warehouse, data lake, or analytics tool.
It’s how raw data is collected, cleaned, reshaped, and delivered to the right place for reporting, analysis, or machine learning.
Without a pipeline, teams often rely on ad hoc scripts, manual data pulls, or error-prone exports — which slow down workflows and create data quality issues. Pipelines remove that friction by automating the entire flow.
Organizations use data pipelines to:
Not exactly. ETL — Extract, Transform, Load — is one type of data pipeline. It follows a defined sequence to move data. But pipelines can also follow different models, like ELT (where transformation happens after loading), or stream data in real time instead of in batches.
A data pipeline is the broader concept — covering everything from ingestion to transformation, storage, monitoring, and delivery.
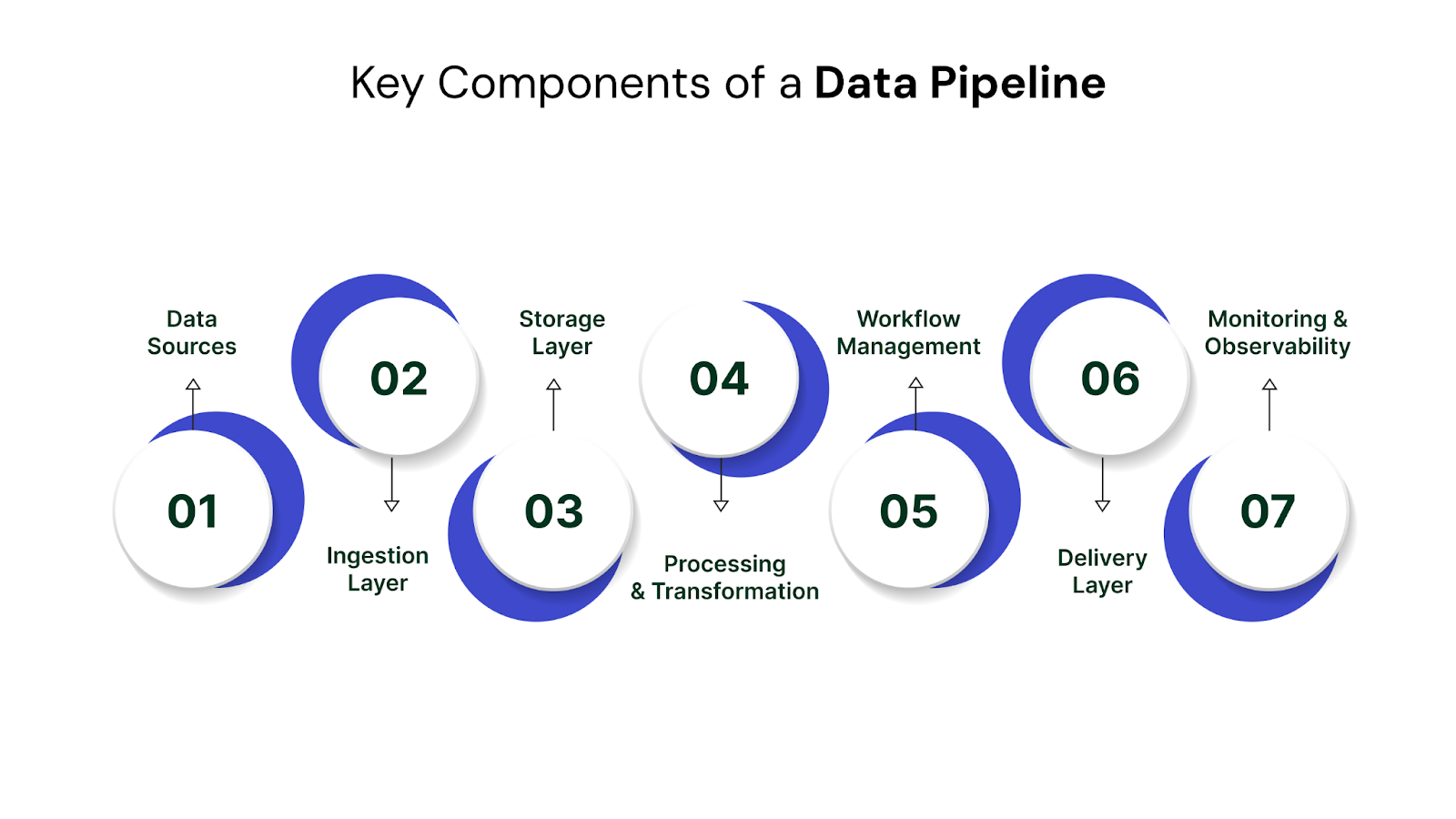
A data pipeline isn’t a single tool — it’s a coordinated system made up of several moving parts. Each part plays a role in collecting, preparing, and delivering data reliably. While the specific tools and architecture may vary, most pipelines follow a common set of core components.
Every pipeline starts with source systems — the places where raw data originates. These might include:
Pipelines are designed to handle structured, semi-structured, and unstructured data from these diverse sources.
The ingestion layer is responsible for bringing data into the pipeline. This can happen in two main ways:
Depending on the use case, ingestion may happen through connectors (e.g., Fivetran, Airbyte), change data capture (CDC), or custom APIs.
Once data is ingested, it needs a place to live. The storage layer is where raw or semi-processed data is held before further transformation or analysis.
Common storage options include:
This is where the real work happens. The transformation layer cleans, reshapes, and enriches data so it can be used effectively. Typical processing tasks include:
Tools like dbt, Apache Spark, or native SQL engines handle this stage.
Orchestration tools control when and how data tasks run. They manage dependencies between steps, handle retries when failures occur, and ensure data flows in the correct sequence. Common orchestration tools include:
These tools are essential for scheduling, monitoring, and managing complex workflows in production environments.
Once transformed, data is sent to its final destination — typically where people or systems consume it.
Examples include:
This final step ensures data consumers have timely access to accurate, reliable information.
A reliable pipeline is one you can trust — and that means tracking its health. Monitoring tools track:
Solutions like Monte Carlo, Databand, or built-in observability from modern platforms help teams proactively detect and fix issues.
These components work together to ensure that raw data can be turned into a usable, trustworthy asset — one that supports analytics, operations, and machine learning in real time or at scale.
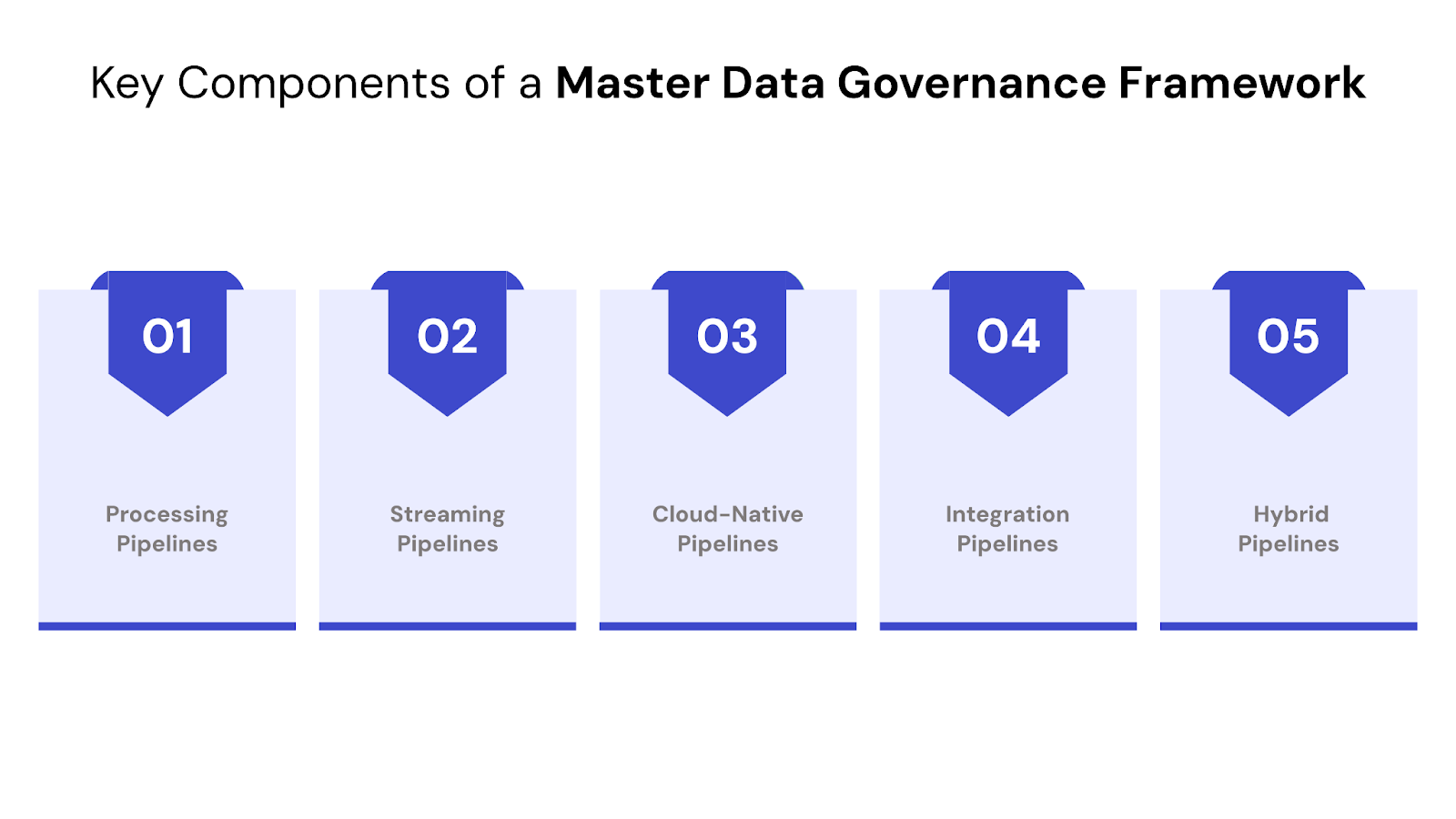
Not all data pipelines are built the same. Depending on the use case—whether it's real-time analytics, historical reporting, or cross-system integration—different types of pipelines serve different purposes.
Here are the most common types of data pipelines used in modern businesses:
Batch pipelines are designed to collect and process data at scheduled intervals. They’re ideal for scenarios where real-time access isn’t necessary — such as daily sales reports, end-of-day reconciliations, or monthly performance dashboards.
Batch processing is still widely used in enterprises, especially for legacy systems or cost-sensitive workloads where latency isn't a priority.
Streaming pipelines ingest and process data continuously as it’s generated. This enables real-time analytics and instant response systems — useful for fraud detection, personalized product recommendations, or operational alerts.
Streaming pipelines are typically more complex to implement and monitor, but they offer significant advantages when speed is critical.
These pipelines are built entirely within cloud environments, using tools that are designed to scale on-demand and handle elastic workloads. Cloud-native pipelines are optimized for flexibility, cost-efficiency, and ease of integration with cloud storage and analytics platforms.
With more organizations moving away from on-prem infrastructure, cloud-native architectures have become the new standard for data pipeline development.
These pipelines are designed to combine and unify data from multiple sources, especially when formats or schemas differ. They often support both batch and streaming modes, depending on the system.
In an integration-focused pipeline, maintaining consistency, handling schema drift, and ensuring data lineage are critical — especially in industries with strict compliance requirements.
Some businesses need hybrid pipelines that support both batch and streaming data, depending on source systems and use case needs. These pipelines are often built using modular, orchestrated components that handle mixed data loads.
At QuartileX, we help clients design hybrid and multi-purpose pipelines that balance cost, performance, and flexibility—especially useful for enterprises undergoing digital modernization or platform migrations.
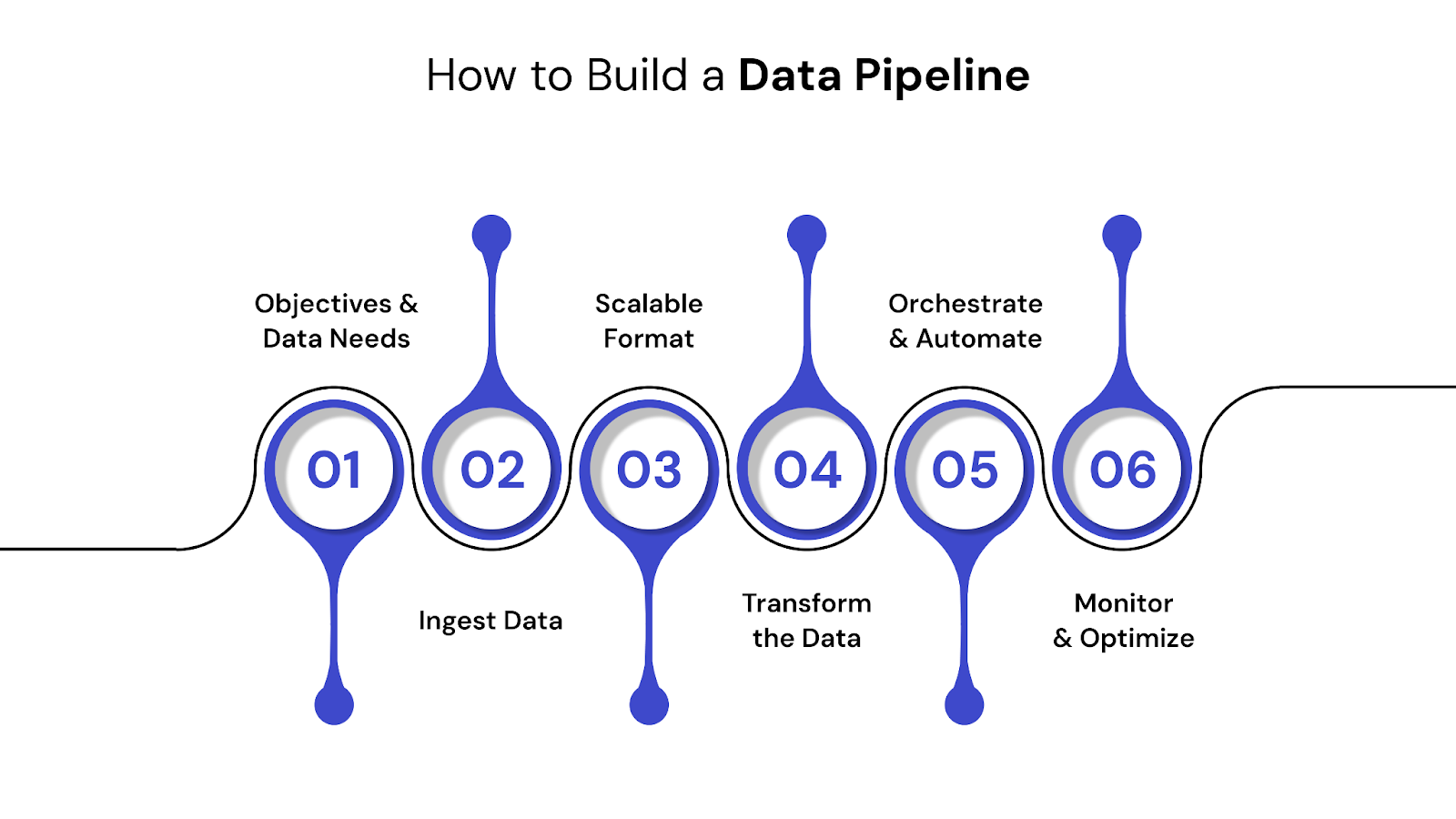
Building a reliable data pipeline doesn’t require reinventing the wheel. However, it does require structure, discipline, and clarity around the pipeline’s purpose. Here’s a typical process followed by engineering teams:
Start with the why. Understand which systems need to connect, what insights are needed, and how frequently data must be updated. This drives all architectural decisions.
Optimize your data infrastructure with modern pipelines and architecture that enable faster analytics and smarter decisions at scale.
Future-Proof Your Data Stack →
Ingest data from your sources — databases, cloud apps, third-party APIs — using connectors or custom integrations. Cloud-native tools like Hevo, Fivetran, or Airbyte make this easier at scale.
🔗 For ingestion design tips, read Data Ingestion Framework: Key Components and Process Flows.
Choose between a data lake, warehouse, or hybrid lakehouse, based on your volume, latency, and analytics needs.
Standardize, clean, and enrich your data using tools like dbt, Spark, or warehouse-native SQL. Transformation ensures consistency across reports and models.
Use orchestration tools like Apache Airflow or Prefect to manage dependencies, retries, and schedule runs across your pipeline components.
🔗 You can explore orchestration options in QuartileX’s Top 10 Best Orchestration Tools.
Build observability into your pipeline: monitor success/failure rates, data latency, and schema changes. Automated alerts and dashboards reduce the risk of silent failures.
🔗 We recommend reviewing the Guide to Testing Data Pipelines for validation techniques.
Investing in a well-designed data pipeline architecture yields long-term advantages across the entire data lifecycle. Here’s what organizations can expect:
Automated data pipelines reduce manual errors and enforce uniform standards. With proper transformation and validation in place, data reaches analysts, engineers, and decision-makers in a clean, trusted state.
Whether it’s real-time streaming or daily batch loads, a functioning pipeline ensures data is available when it’s needed. This is crucial for operations like demand forecasting, fraud detection, and performance monitoring.
Pipelines connect data from CRMs, ERPs, SaaS tools, and databases, allowing you to create unified views across departments. This integration supports everything from executive dashboards to ML model training.
Automated workflows free up technical teams from repetitive, manual tasks. Engineers can focus on optimization and innovation instead of constant data firefighting.
As data volume and velocity grow, a modular pipeline architecture allows you to scale ingestion, processing, and storage independently, ensuring performance doesn’t degrade as demand increases.
🔗 If you’re currently assessing your analytics maturity, we recommend reading How to Build a Scalable, Business-Aligned Data Analytics Strategy.
Designing a data pipeline isn't just about stitching tools together—it's about creating a system that's reliable, scalable, and resilient. However, even well-planned pipelines can run into operational and architectural challenges.
Below are some of the most common issues organizations face during data pipeline development:
As source systems evolve, their data models often change—new fields are added, formats shift, or column names are updated. If the pipeline doesn’t detect and adapt to these changes, it can:
Solution: Use tools with automatic schema detection and alerts. Implement version control for data models and test ingestion logic regularly.
When pulling data from multiple systems, inconsistencies are inevitable—duplicates, missing values, incorrect formats, or out-of-sync timestamps can all degrade downstream insight.
Solution: Apply data validation rules early in the pipeline. Build in cleansing and anomaly detection layers, and automate reporting for data quality metrics.
Manual steps in pipeline execution—like ad hoc scripts or manual file uploads—introduce fragility, increase risk, and make it harder to scale.
Solution: Use orchestration tools (e.g., Airflow or Prefect) to automate dependencies. Ensure pipelines are modular and reusable to avoid one-off hacks.
As data volume grows, pipelines that worked at a small scale may start to lag—resulting in outdated reports or broken SLAs.
Solution: Optimize bottlenecks in your data processing pipeline, and consider transitioning to streaming architecture for real-time use cases.
Without real-time observability, it’s easy for pipeline failures or data mismatches to go undetected until they’ve already affected business decisions.
Solution: Implement monitoring systems that track throughput, failure rates, and data freshness. Add logging, alerting, and lineage tracking to maintain transparency.
Pipelines that move sensitive customer or financial data must meet strict compliance standards (e.g., GDPR, HIPAA). Without built-in controls, they may expose organizations to serious risks.
Solution: Apply fine-grained access control, encrypt data in motion and at rest, and log all interactions with regulated data. QuartileX’s data governance solutions are designed to support compliance from day one.
When these challenges are not addressed early, they compound, turning what should be a streamlined data backbone into a brittle, failure-prone system. But with the right planning, tooling, and expertise, these problems are entirely solvable.
A successful data pipeline isn’t just about getting data from point A to point B — it’s about doing it securely, reliably, and with minimal maintenance overhead. Here are the key principles that guide long-term pipeline success:
Don’t build for technology’s sake. Define the exact business problem the pipeline supports — whether it's feeding a marketing dashboard, centralizing sales data, or training a recommendation engine.
Design pipelines as independent, decoupled components for ingestion, transformation, storage, and delivery. This makes maintenance easier and supports reusability.
Manual interventions increase the risk of failure. Use orchestration tools to automate triggers, retries, and logging. Built-in alerting and self-healing workflows where possible.
Include metadata tracking, access control, and quality checks early in the design. Data lineage and compliance features should be part of the foundation, not added later.
Even well-built pipelines degrade over time if left unchecked. Implement monitoring tools to track processing times, schema anomalies, and data volume spikes. Regular audits prevent long-term performance issues.
Use cloud-native platforms and services when possible — they simplify horizontal scaling, reduce infrastructure overhead, and integrate well with modern tools.
To understand how cloud-native strategies impact pipeline performance, check out Tips on Building and Designing Scalable Data Pipelines.
Building a modern data pipeline involves more than just code. It requires a combination of platforms, frameworks, and managed services that work together reliably and efficiently.
Here’s a breakdown of common tools across the pipeline lifecycle:
These tools help pull data from multiple sources—databases, APIs, SaaS platforms, or flat files—into your pipeline.
Popular options:
🔗 QuartileX frequently uses tools like Hevo and Fivetran to build ELT pipelines tailored to client infrastructure. Learn more about our data engineering services.
These tools clean, format, and enrich data to make it usable for analytics or machine learning.
Popular options:
Orchestration is about managing workflows—scheduling jobs, handling dependencies, and recovering from failures.
Popular tools:
These tools allow teams to define pipelines as code, track executions, and automate recoveries with minimal downtime.
This is where the processed data lives—ready for reporting, analytics, or machine learning.
Options include:
Monitoring tools are crucial for detecting failures, understanding bottlenecks, and maintaining trust in your data.
Leading platforms:
These tools ensure that your pipeline remains transparent, auditable, and easy to debug—particularly in regulated or mission-critical environments.
There’s no one-size-fits-all approach. Your tech choices should depend on:
At QuartileX, we specialize in tool-agnostic architecture design—selecting, integrating, and scaling the right combination of platforms based on your specific needs.
Designing and managing a pipeline is one thing — scaling it across teams, systems, and business functions is another. At QuartileX, we specialize in building future-ready, cloud-native, and AI-integrated data pipelines that align with your business goals.
Here’s how we help:
We support every phase — from initial data audit to production deployment and optimization.
Streamline your data pipelines and architecture with scalable, reliable engineering solutions designed for modern analytics.
See Data Engineering Services →
Across industries, data pipelines power the processes behind faster decisions, better customer experiences, and smarter automation.
Here are several real-world examples where data pipelining plays a critical role:
Banks and fintech firms use streaming data pipelines to process transactions as they occur. These pipelines evaluate behavioral patterns and flag anomalies, enabling fraud prevention within milliseconds.
Pipeline Features:
Retailers build customer data pipelines to centralize behavior from web, mobile, CRM, and email platforms. This enables segmentation, dynamic recommendations, and campaign triggers based on real-time activity.
Pipeline Highlights:
In industrial environments, sensor data flows continuously from machines. Data pipelines process this input to predict when a component is likely to fail—reducing unplanned downtime.
How it works:
Whether in healthcare, logistics, or SaaS, organizations need a single source of truth. Data pipelines consolidate inputs from multiple systems into a unified warehouse—fueling company-wide dashboards.
Pipeline Example:
ML pipelines rely on high-quality data at every phase—training, validation, and inference. These pipelines must be robust, auditable, and able to feed dynamic models without delay.
Pipeline Components:
🔗 Explore more in Make Smarter Decisions with Analytics Modernization.
A well-designed data pipeline is more than a technical asset—it’s the foundation for trustworthy analytics, scalable machine learning, and cross-functional visibility. Whether you’re integrating customer data, enabling real-time monitoring, or standardizing metrics for business intelligence, your data pipeline plays a direct role in decision quality and operational efficiency.
But pipelines don’t build or manage themselves. They require thoughtful architecture, the right tooling, and a framework that evolves with your business.
At QuartileX, we work closely with teams to design and implement custom data pipelines that are reliable, secure, and built for scale—whether you're modernizing legacy systems or enabling new AI initiatives.
Looking to streamline your data workflows or build a pipeline from scratch?
Talk to a data expert at QuartileX—we’ll help you turn your data infrastructure into a lasting competitive advantage.

Build high-performance pipelines that keep your data flowing reliably — from ingestion to insight.
Build with Data Engineering →
ETL is a type of data pipeline with a specific order: Extract, Transform, Load. Data pipelines can follow ETL, ELT, or real-time streaming models depending on the architecture.
Pipelines support real-time fraud detection, unified customer views, predictive maintenance, business dashboards, and feeding ML models with structured data.
Popular tools include Fivetran, Airbyte (ingestion), dbt (transformation), Apache Airflow and Prefect (orchestration), and Snowflake or BigQuery (storage).
Common issues include schema drift, data quality breakdowns, latency, manual dependencies, poor observability, and compliance risks.
Batch pipelines process data in scheduled chunks, ideal for reporting. Streaming pipelines handle continuous data in near real-time, ideal for instant insights and alerts.
They control task sequencing, handle failures, manage dependencies, and keep pipelines running smoothly in production environments.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


