


Over 30% of annual revenue is lost to siloed data from poor orchestration and integration. This makes the right tools essential for consistent performance and scalability.
As organizations handle growing volumes of structured and unstructured data, the need for orchestration tools that automate, monitor, and manage data workflows is more urgent than ever. These tools serve as the backbone for data pipeline reliability, enabling seamless integration between systems, optimized resource usage, and faster time-to-insight.
In this guide, you’ll explore 15 of the best orchestration tools in 2025, each offering features tailored for modern data teams, including workflow scheduling, dependency management, real-time monitoring, and error recovery.
TL;DR
Top Container and Data Pipeline Orchestration tools manage the execution, scheduling, and monitoring of workflows in data pipelines. Rather than manually triggering each task, these tools define dependencies between operations and execute them in sequence or parallel.
Whether you're running daily batch jobs or streaming real-time data, orchestration platforms help ensure your workflows are repeatable, observable, and fault-tolerant.
They support data engineers by offering:
Types of Orchestration Tools
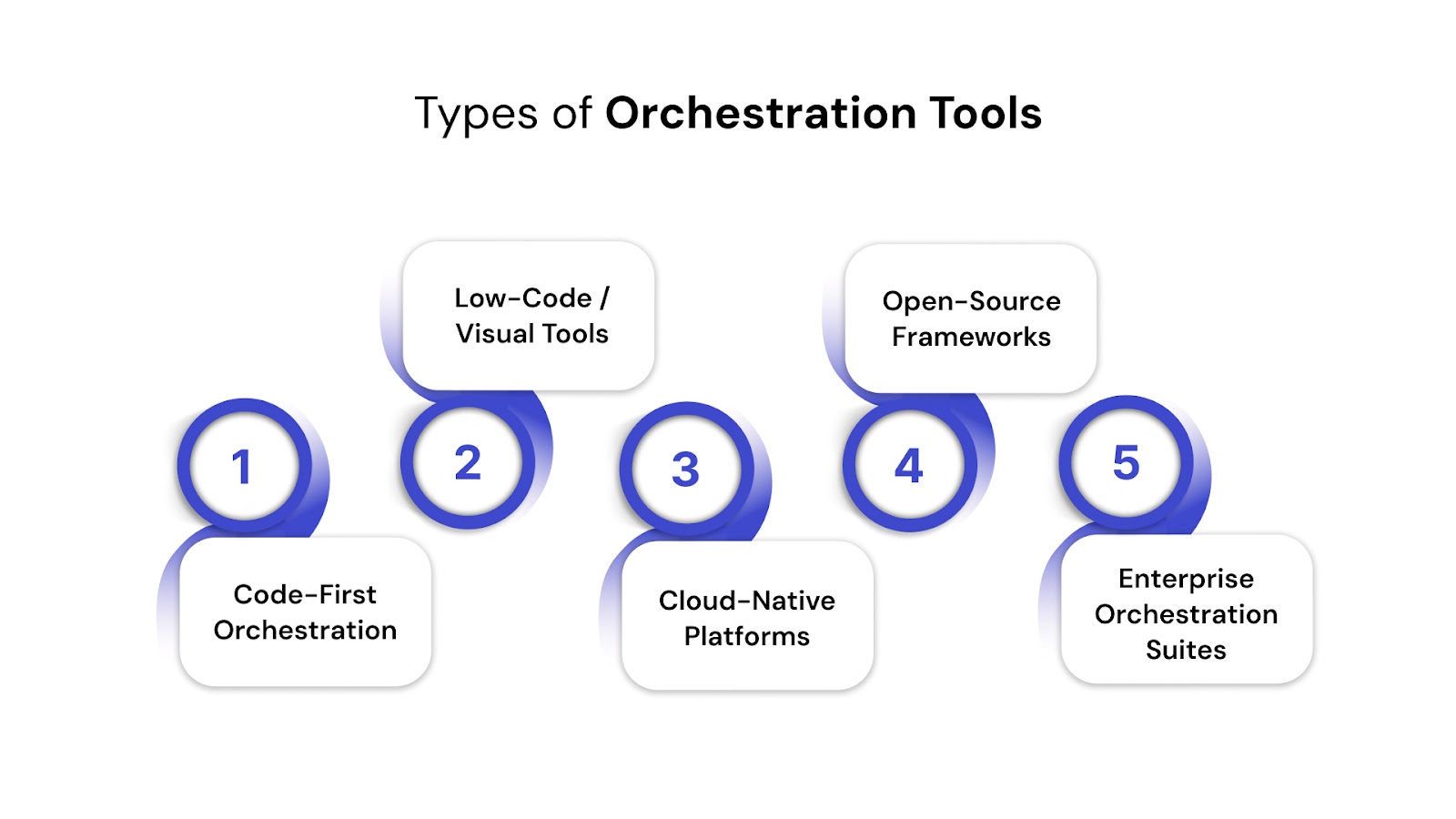
Before choosing the right orchestration tool, it helps to know the different types available. Each one is built with specific use cases, team preferences, cloud and infrastructure needs in mind.
Here's how top Container and Data Pipeline Orchestration tools differ based on architecture, usability, and purpose:
Once you understand your architecture, team needs, and workflow patterns, the next step is choosing a top Container and Data Pipeline Orchestration tool that aligns with them.
In 2025, The data orchestration tools market is valued at $28.73 billion in 2025 and is forecasted to reach $112.95 billion by 2032.
Orchestration tools offer greater flexibility, stronger reliability, and tighter integration with cloud environments. Some are built for batch processing, while others support real-time data pipelines with detailed monitoring and automation features. The right tool can streamline workflows, reduce errors, and scale alongside your data needs.
Let’s look at some of the most widely used and dependable top Container and Data Pipeline Orchestration tools this year.

Apache Airflow has established itself as the gold standard for workflow orchestration, processing millions of tasks daily across organizations worldwide. Its Python-based approach and extensive operator library make it incredibly flexible for complex data workflows.
Best use case: Complex, time-based workflows with interdependent tasks requiring high visibility and custom scheduling logic.
Key Features:
Strengths vs Limitations:
Real-world case study: Netflix processes 100,000+ daily ETL jobs using Airflow, managing data pipelines across 50+ microservices. Adobe orchestrates ML model training workflows serving 1M+ Creative Cloud users with 99.9% uptime.
Looking to manage your data across platforms with ease? Discover the top tools and solutions for modern data integration guide.
Dagster brings software engineering best practices to data orchestration with its asset-centric approach and strong typing system. It treats data as first-class assets, making it easier to understand data lineage and dependencies.
Best use case: Data teams prioritizing data quality, testing, and observability with software engineering practices like version control and CI/CD.
Key Features:
Strengths vs Limitations:
Real-world case study: Elementl processes 500TB+ daily data transformations using Dagster's asset-centric approach for ML feature stores. Sling TV manages streaming analytics pipelines across 20+ data sources with automated testing reducing incidents by 75%.
Luigi, developed by Spotify, offers a lightweight approach to workflow orchestration with minimal setup requirements. It excels at batch processing workflows and provides clear dependency visualization.
Best use case: Batch processing workflows requiring minimal overhead and simple dependency management without complex scheduling needs.
Key Features:
Strengths vs Limitations:
Real-world case study: Foursquare uses Luigi for processing 50M+ location data points daily across batch ETL pipelines. Stripe leverages Luigi for financial reporting workflows processing billions of transactions with dependency-aware execution.

Flyte is designed for machine learning and data science workflows, offering strong support for versioning, reproducibility, and resource management. It provides native support for containerized execution and cloud-native scaling.
Best use case: ML workflows requiring reproducibility, versioning, and resource isolation with Kubernetes-native execution.
Key Features:
Strengths vs Limitations:
Real-world case study: Lyft runs 10,000+ ML experiments monthly using Flyte for autonomous vehicle algorithms with reproducible model training. Spotify processes 300M+ user recommendation pipelines using Flyte's multi-language support for Python and Scala workflows.
Streamline your data pipelines and architecture with scalable, reliable engineering solutions designed for modern analytics.
See Data Engineering Services →
Google Cloud Composer provides a fully managed Apache Airflow service on Google Cloud Platform, eliminating operational overhead while maintaining Airflow's flexibility and ecosystem compatibility.
Best use case: Teams already using Google Cloud Platform requiring managed Airflow without operational complexity.
Key Features:
Strengths vs Limitations:
Real-world case study: Twitter processes 500TB+ daily analytics using Cloud Composer for real-time ML model training pipelines. Home Depot orchestrates supply chain data across 2,000+ stores using Composer's auto-scaling for seasonal demand fluctuations.
Ready to optimize your workflows? Explore our guide on Ultimate Guide on Data Migration Tools, Resources, and Strategy for seamless and efficient execution.
Metaflow focuses on data science workflows with human-friendly APIs and robust infrastructure abstraction. It provides seamless scaling from laptop to cloud.
Best use case: Data science teams needing to scale from prototyping to production with minimal infrastructure concerns.
Key Features:
Strengths vs Limitations:
Real-world case study: CNN uses Metaflow for processing 1M+ daily news articles with NLP models scaling from local development to AWS Batch. Outreach automates sales intelligence pipelines processing 50M+ customer interactions using Metaflow's versioning capabilities.
Azure Data Factory provides a cloud-native data integration service with visual pipeline design and extensive connector support. It's deeply integrated with Microsoft's ecosystem.
Best use case: Organizations heavily invested in Microsoft ecosystem requiring visual pipeline design and extensive connector support.
Key Features:
Strengths vs Limitations:
Real-world case study: H&R Block processes 50M+ tax documents annually using Data Factory for automated compliance reporting pipelines. Asos orchestrates retail analytics across 200+ countries using Data Factory's hybrid connectors for on-premises ERP integration.

Argo Workflows provides container-native workflow execution on Kubernetes, offering powerful orchestration capabilities for cloud-native applications and CI/CD pipelines.
Best use case: Container-native workflows requiring Kubernetes orchestration and cloud-native scaling capabilities.
Key Features:
Strengths vs Limitations:
Real-world case study: Intuit processes 10,000+ daily CI/CD builds using Argo Workflows for microservices deployment automation. Red Hat orchestrates OpenShift container builds across 500+ clusters using Argo's parallel execution capabilities.

Kestra offers a modern approach to workflow orchestration with a focus on simplicity and real-time capabilities. It provides both code-based and visual workflow design options.
Best use case: Teams needing both technical and non-technical workflow design with real-time processing capabilities.
Key Features:
Strengths vs Limitations:
Real-world case study: Carrefour uses Kestra for real-time inventory management across 12,000+ stores with event-driven workflows. Decathlon orchestrates e-commerce analytics processing 10M+ daily transactions using Kestra's hybrid visual-code approach.
While not specifically an orchestration tool, Kubernetes provides the foundation for container orchestration and is increasingly used for data workflow management through custom resources and operators.
Best use case: Container-native data workflows requiring fine-grained resource control and cloud-native scaling.
Key Features:
Strengths vs Limitations:
Real-world case study: Spotify runs 1,000+ microservices using Kubernetes for music streaming infrastructure serving 400M+ users. Airbnb orchestrates ML model serving and batch processing across 500+ services using Kubernetes operators for automated scaling.
Not sure which orchestration tool to pick? Our guide on data pipeline tools might help and give insights.
Mage is a modern data pipeline tool that focuses on simplicity and developer experience, providing a notebook-style interface for building data workflows.
Best use case: Data teams wanting a simple, interactive approach to building data pipelines with minimal setup overhead.
Key Features:
Strengths vs Limitations:
Real-world case study: Shopify uses Mage for rapid prototyping of merchant analytics pipelines with notebook-style development. Instacart processes grocery demand forecasting using Mage's interactive data exploration capabilities across 5,000+ stores.
ActiveBatch provides enterprise-grade job scheduling and workload automation with a focus on business process orchestration and cross-platform support.
Best use case: Enterprise organizations requiring comprehensive job scheduling across heterogeneous systems with business process integration.
Key Features:
Strengths vs Limitations:
Real-world case study: JPMorgan Chase uses ActiveBatch for orchestrating 50,000+ daily financial reporting jobs across mainframe and cloud systems. General Electric automates manufacturing processes across 200+ factories using ActiveBatch's cross-platform scheduling capabilities.
Ansible provides infrastructure automation and configuration management capabilities that can be extended to orchestrate data workflows and system provisioning.
Best use case: Infrastructure automation and configuration management with some data workflow orchestration capabilities.
Key Features:
Strengths vs Limitations:
Strengths
Real-world case study: NASA uses Ansible for automating infrastructure provisioning across 100+ research computing clusters. Walmart orchestrates deployment automation for 11,000+ stores using Ansible's idempotent configuration management.
Looking to build a solid data base? Explore our guide on the steps and Essentials to Prepare Data for AI.
Prefect is a modern workflow orchestration platform that emphasizes ease of use and developer experience, with a focus on handling failure gracefully and providing comprehensive observability.
Best use case: Teams needing robust error handling, hybrid execution environments, and modern Python-based workflow development with minimal operational overhead.
Key Features:
Strengths vs Limitations:
Real-world case study: Marqeta processes 10M+ daily payment transactions using Prefect's hybrid execution for PCI-compliant workflows. DoorDash orchestrates real-time delivery optimization across 4,000+ cities using Prefect's failure handling capabilities.
Temporal provides a platform for building scalable and reliable distributed applications, with strong support for long-running workflows and microservices orchestration.
Best use case: Building reliable distributed applications and microservices with complex business logic requiring durable execution and state management.
Key Features:
Strengths vs Limitations:
Real-world case study: Uber processes 15M+ daily ride requests using Temporal for payment processing and driver matching workflows. Coinbase manages cryptocurrency trading operations across 100+ countries using Temporal's durable execution for financial compliance.
Once your security, compliance, and monitoring needs are covered, it's time to focus on selecting an orchestration tool that aligns with your workflows and long-term goals.
Optimize your data infrastructure with modern pipelines and architecture that enable faster analytics and smarter decisions at scale.
Future-Proof Your Data Stack →
Choosing the right orchestration tool goes beyond brand names or popularity. The best tool aligns with your systems, scales with your data, and fits into your team’s working style. A tool that lacks compatibility or flexibility can delay deployments, increase bugs, and affect pipeline stability.
Before finalizing any tool, review your architecture, workflow patterns, team capacity, and long-term data goals. This approach helps avoid technical debt and ensures your pipelines remain reliable as they grow.
Your orchestration tool plays a critical role in data pipeline efficiency. Choose one that fits your current setup and supports your growth ahead.
Choosing the right orchestration tool is essential for building workflows that are reliable, scalable, and easy to manage. Whether you're running nightly batch jobs or managing real-time event-driven pipelines, the right tool ensures better visibility, faster execution, and fewer failures.
This guide covered key orchestration platforms for 2025. From open-source engines like Apache Airflow to managed platforms like Prefect Cloud and Azure Data Factory, each tool serves different needs based on your infrastructure, team structure, and workload type.
If your team is struggling with slow task execution, missed dependencies, or complex pipeline failures, QuartileX can help. We offer orchestration-first solutions tailored to your ecosystem, combining tool selection with implementation support.
Data Orchestration with QuartileX
At QuartileX, we help teams bring structure and stability to their data workflows using tools built for orchestration.
Here’s how we support your data pipelines:
Our goal is to build orchestration layers that reduce manual intervention and support continuous, error-free data delivery. Whether you're migrating from cron jobs or scaling your current workflows, we help you build systems that are future-ready.
Ready to bring order to your workflows? Talk to the orchestration experts at QuartileX to streamline your data operations.
Build high-performance pipelines that keep your data flowing reliably — from ingestion to insight.
Build with Data Engineering →
While most teams rely on a primary orchestration platform, some may use others for specialized use cases. For instance, Airflow may manage complex batch workflows, while Prefect handles lightweight event-based tasks.
Open-source tools like Airflow and Dagster offer flexibility and community support but need setup and maintenance. Managed platforms like Prefect Cloud or Azure Data Factory reduce overhead and provide built-in scalability.
Most orchestration tools are designed for batch or scheduled workflows. Real-time use cases are better handled by tools like Kafka or Flink. However, orchestration tools can trigger or monitor real-time systems as part of broader pipelines.
Basic Python knowledge, familiarity with scheduling concepts, and understanding of your data stack are important. For open-source tools, skills in DevOps or Kubernetes can also help manage infrastructure.
Not always. Tools like AWS Step Functions or Azure Logic Apps can act as workflow managers within cloud ecosystems. You can integrate orchestration tools like Airflow with these services for more control and visibility.
Most tools provide task-level logs, alerts, and dashboards. Features like retries, failure tracking, and SLA miss alerts help keep pipelines stable in production.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


