Data fuels artificial intelligence, yet its preparation remains a significant hurdle. Data scientists often spend up to 80% of their valuable time cleaning, integrating, and preparing data, delaying crucial AI initiatives. This hidden bottleneck can derail even the most advanced algorithms, leading to frustrating outcomes.
In fact, studies show that a staggering 85% of AI projects fail, with poor data quality being the primary reason. Beyond technical issues, it translates directly to wasted resources and missed opportunities.
This guide will equip you with the knowledge of essential steps, techniques, and best practices for successful AI data preparation. Well-prepared data is the foundation that unlocks accurate insights, faster automation, and a strong return on investment for your AI.
Key Takeaways
Data preparation is foundational for AI success; poor data quality is a top reason AI projects fail.
It's a multi-stage process that involves collecting, cleaning, transforming, engineering, labeling, and validating data.
Challenges are common: Expect issues like incomplete data, inconsistencies, high volume, and data drift.
Best practices are key: Start early, automate, monitor continuously, and collaborate to overcome hurdles.
Specialized tools like QuartileX streamline the process: Automating complex steps to ensure high-quality, AI-ready data.
What Is Data Preparation for AI?
Data preparation for AI is the essential process of gathering, refining, and organizing raw data to make it suitable for use by artificial intelligence and machine learning systems. In its original state, data often comes from varied sources like customer records, sensor logs, or online transactions.
However, this raw information is rarely ready for AI right away. It might be incomplete, inconsistent, contain errors, or be scattered across different formats, making it impossible for algorithms to process effectively. Data preparation bridges this critical gap, transforming messy, disparate data into a structured, reliable, and high-quality resource.
Think of it like preparing ingredients for a gourmet meal. You wouldn’t start cooking with unwashed vegetables, mismatched spices, or spoiled meat. Similarly, AI needs clean, consistent, and well-structured data to perform at its best.
This involves not just collecting the right ingredients, but cleaning them, chopping them to the right size, combining them, and ensuring they meet the recipe’s (algorithm’s) exact requirements. The better your data preparation, the stronger and more insightful your AI results will be, leading to smarter decisions and greater value.
Why Is Data Preparation for AI Important?
Effective data preparation drives successful AI initiatives. It directly impacts your models' performance, speed to results, and the ultimate value your organization extracts. Neglecting this phase leads to flawed predictions and wasted effort. Prioritizing data preparation unlocks AI’s full potential.
Here’s why it's paramount:
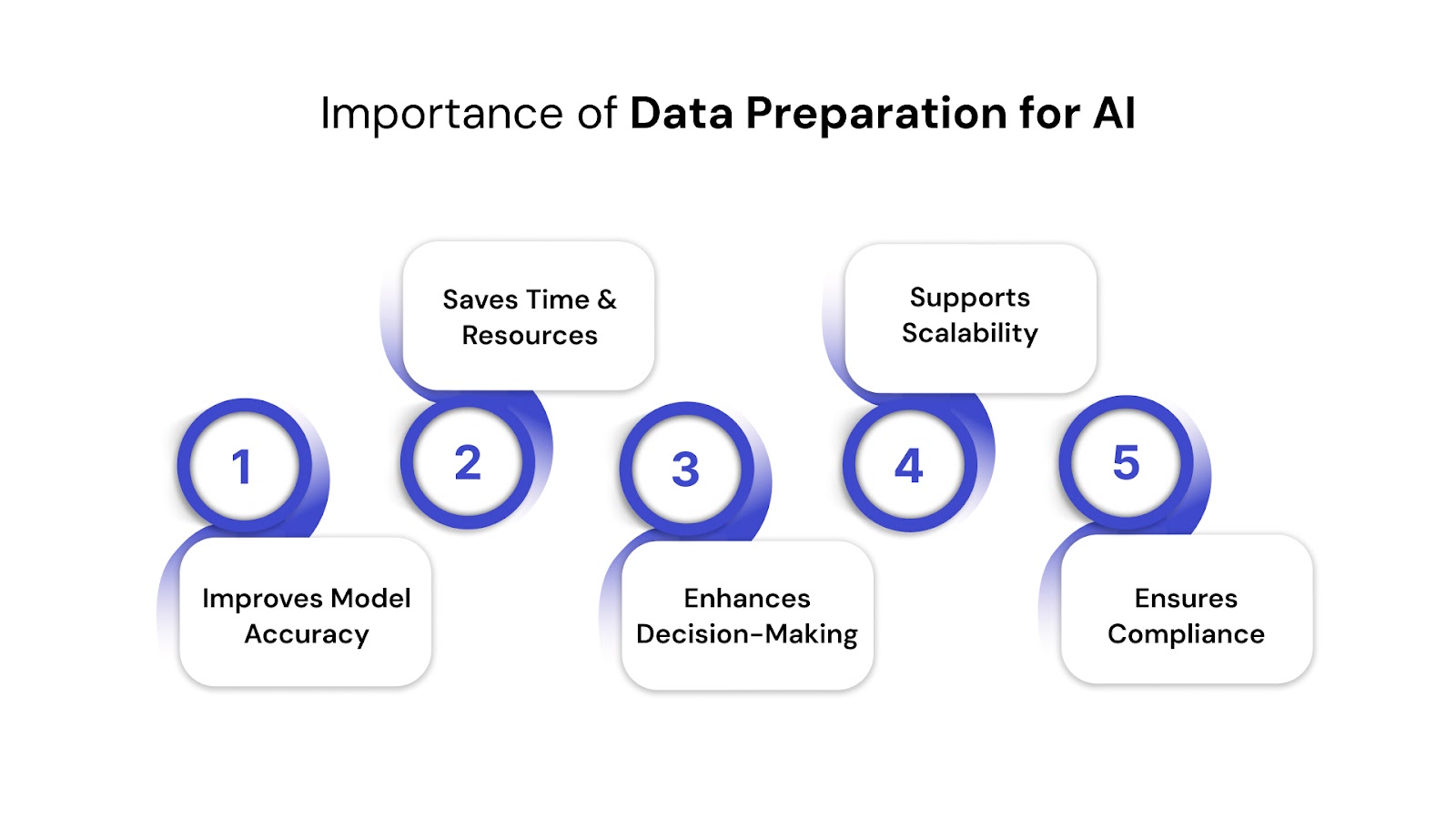
Improves Model Accuracy: AI learns from data. Errors or inconsistencies directly lead to unreliable outputs. Proper preparation ensures precise, representative data, boosting accuracy and trustworthiness.
Saves Time and Resources: Fixing bad data post-training is costly and slow. Upfront preparation prevents rework, allowing teams to focus on model optimization and business outcomes, not firefighting.
Enhances Decision-Making: Leaders rely on AI insights for strategy. Clean data ensures these insights reflect reality, not distortions. This enables confident, impactful business decisions.
Supports Scalability: Growing AI needs require a flexible foundation. Well-prepared, standardized data allows seamless scaling of solutions across new datasets and applications without recurring issues.
Reduces Risks and Ensures Compliance: Flawed data can lead to penalties and reputational damage, especially in regulated sectors. Proactive data preparation embeds quality and compliance checks, safeguarding your organization.
Understanding these profound benefits underscores why data preparation isn't optional for successful AI. Now, let's discover the practical, step-by-step workflow for achieving high-quality, AI-ready data.
Your Data Can Do More. Let’s Unlock Its Full Potential.
Whether you're modernizing legacy systems or scaling analytics, QuartileX helps you harness data for real growth.
Transforming raw information into a high-quality, AI-ready asset is a structured and critical process. By following these key steps, you can ensure your data is optimized for machine learning algorithms, leading to more robust and accurate AI models.
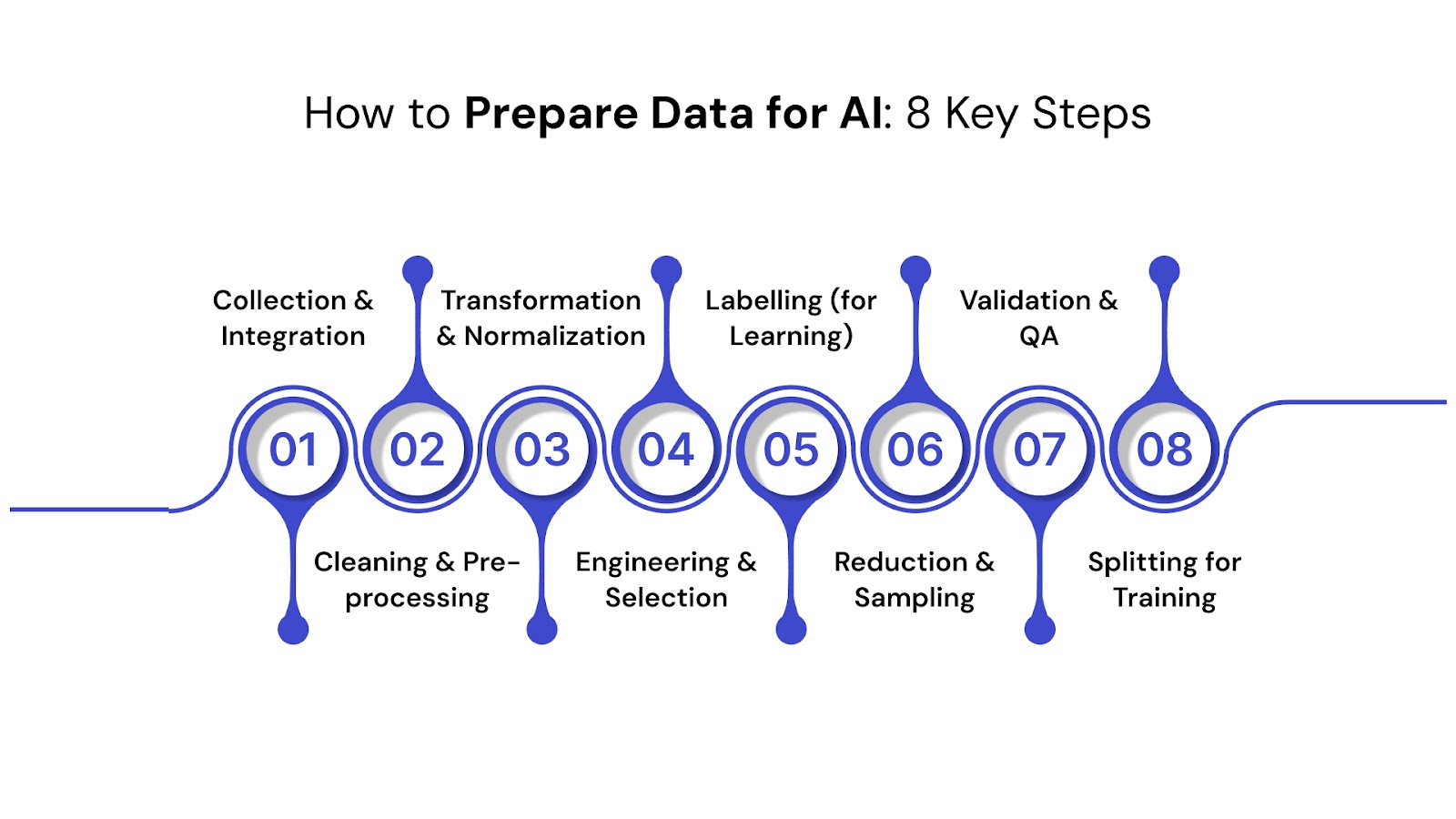
1. Data Collection and Integration
This initial phase involves identifying, sourcing, and consolidating all relevant raw data from various disparate systems into a unified repository. It’s about bringing together all the pieces of your data puzzle, ensuring data from different sources can be combined and analyzed coherently.
Identify Sources: Pinpoint all internal (CRMs, ERPs, IoT devices, logs) and external (public datasets, APIs, third-party vendors) data sources relevant to your AI objective.
Choose Storage: Select a suitable storage solution (data lake, data warehouse, cloud storage) capable of handling varied data types and volumes.
Implement Integration Strategies: Use ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) pipelines to merge datasets, reconcile schemas, and handle different data formats efficiently.
Practical Example: A streaming service aiming to recommend content might collect user viewing history from their internal database, ratings from a user feedback system, and demographic data from a third-party API. Integration involves merging these distinct data streams into a single, comprehensive user profile.
2. Data Cleaning and Pre-processing
This critical step involves identifying and rectifying errors, inconsistencies, and anomalies within your raw, integrated data. It focuses on purifying the dataset by removing "noise" and making it fit for analysis.
Handle Missing Values: Identify gaps (nulls, blanks). You can use imputation (filling with mean, median, mode, or more advanced methods) or deletion (removing rows/columns with excessive missing data, being careful not to lose valuable information).
Remove Duplicates: Detect and eliminate identical entries that can skew model learning and inflate dataset size.
Correct Errors: Fix typos, incorrect entries, and structural errors (e.g., "St." vs. "Street"). This often involves data standardization across fields.
Address Outliers: Identify and decide how to handle extreme values that deviate significantly from the rest of the data. You might remove them (if genuine errors), transform them (e.g., log transformation), or cap/floor them to a reasonable range.
Practical Example: In a dataset of website user registrations, cleaning would involve filling in missing city names using available ZIP codes, removing duplicate user profiles, correcting misspelled email domains like "gamil.com" to "gmail.com," and identifying unusually high "age" values (e.g., 200) as errors.
3. Data Transformation and Normalization
This step converts your cleaned data into a format that AI algorithms can efficiently process and learn from. It involves changing the scale, structure, or type of data to suit specific model requirements.
Normalization/Scaling: Adjust numerical features to a standard range (e.g., 0 to 1) or distribution (e.g., mean 0, variance 1). Common techniques include Min-Max Scaling and Standardization (Z-score normalization).
Encoding Categorical Data: Convert text-based categories (e.g., "Economy," "Business," "First Class") into numerical representations that algorithms can understand. Techniques include One-Hot Encoding (creates new binary columns for each category) and Label Encoding (assigns a unique integer to each category).
Discretization/Binning: Convert continuous numerical data into discrete bins or intervals (e.g., dividing "salary" into ranges like "$30k-50k," "$50k-70k").
Aggregation: Summarize data points into a single value (e.g., summing daily sales figures into weekly totals for trend analysis).
Practical Example: For a model predicting customer loan default, numerical features like "Income" and "Loan Amount" would be normalized to prevent the higher values from dominating. Categorical features like "Loan Type" (e.g., "Personal," "Auto," "Mortgage") would be One-Hot Encoded into separate binary columns.
4. Feature Engineering and Selection
Feature engineering is the creative process of deriving new, more impactful input features from existing raw data to boost model performance. Complementing this, feature selection involves choosing the most relevant subset of these features.
Feature Creation: Combine existing features (e.g., Age and Years of Education to create Education_per_Age), extract components from complex features (e.g., Hour_of_Day from a Timestamp), or apply mathematical transformations.
Interaction Features: Create features that capture the combined effect of two or more independent variables (e.g., multiplying Clicks by Time_on_Page to get an "Engagement Score").
Polynomial Features: Create higher-order terms from existing numerical features (e.g., Income^2) to capture non-linear relationships.
Feature Selection Methods:
Filter methods: Use statistical tests (e.g., correlation, chi-squared) to rank features by their relationship to the target variable.
Wrapper methods: Use a machine learning model to evaluate subsets of features by training and testing.
Embedded methods: Feature selection is built into the model training process itself (e.g., L1 regularization in linear models).
Practical Example: From a retail dataset with "Last Purchase Date" and "Customer Registration Date," you could engineer a new feature called "Customer Lifespan (days)" or "Days Since Last Purchase." For a vast e-commerce dataset with hundreds of product attributes, feature selection might remove attributes like "Product Color Code" if it proves irrelevant to predicting sales.
The depth of your feature engineering directly impacts a model's capabilities. This becomes especially critical when designing advanced systems; learn more about the intricate components of Gen AI Agent Architecture.
5. Data Labeling (for Supervised Learning)
This step involves attaching meaningful tags, categories, or attributes to raw data. This process is fundamental for supervised learning models, where the AI learns from examples that are already "correctly answered" or pre-classified.
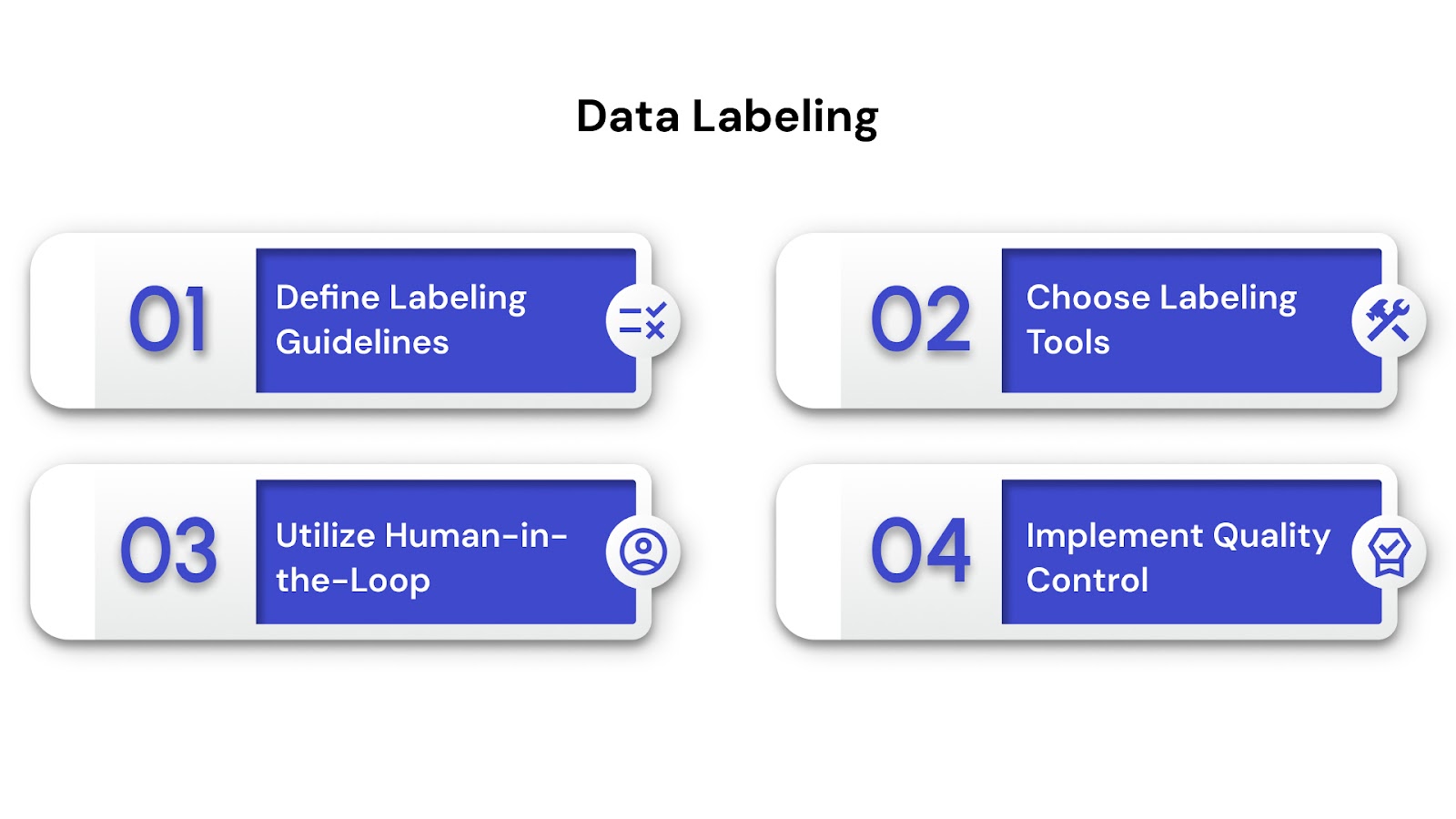
Define Labeling Guidelines: Establish clear, unambiguous rules and criteria for annotation to ensure consistency across annotators, especially if multiple people are involved.
Choose Labeling Tools: Utilize specialized software tailored for different data types (e.g., image annotation tools for drawing bounding boxes, text annotation tools for sentiment analysis or named entity recognition).
Utilize Human-in-the-Loop: Human annotators are often crucial for accurate labeling, with AI potentially assisting (e.g., pre-labeling suggestions) or validating their work to improve efficiency and consistency.
Implement Quality Control: Establish processes to review labeled data for accuracy and consistency, such as inter-annotator agreement checks or consensus mechanisms.
Practical Example: For an AI model designed to automate customer support, raw customer email inquiries would be labeled with categories like "Billing Inquiry," "Technical Support," or "Product Feature Request." For a facial recognition system, images of faces would be labeled with identities or emotions.
6. Data Reduction and Sampling
This step aims to optimize your dataset by reducing its volume or dimensionality while retaining its most critical information. This helps mitigate the computational expense of large datasets and addresses the "curse of dimensionality," which can make models less efficient and prone to overfitting.
Dimensionality Reduction: Reduce the number of features by transforming the data into a lower-dimensional space. Techniques include Principal Component Analysis (PCA), which identifies the most important components (linear combinations of original features), or t-SNE for visualization.
Numerosity Reduction: Reduce the number of data points. Techniques include sampling (taking a representative subset of data, e.g., random sampling or stratified sampling to maintain class proportions) and data aggregation.
Data Compression: While less common for direct AI model input, encoding data in a more compact form can sometimes be part of storage optimization.
Practical Example: If you have thousands of unique customer purchase behaviors recorded as separate features, dimensionality reduction could consolidate these into a few key "purchase preference" components. For a vast dataset of hourly sensor readings from thousands of machines, sampling might involve selecting every 100th reading to train a preliminary predictive maintenance model faster.
7. Data Validation and Quality Assurance
This critical step ensures your prepared data adheres to predefined quality standards, rules, and formats before it's fed into the AI model. Data validation is a continuous process that verifies accuracy, completeness, consistency, and validity, serving as your final line of defense for data integrity.
Schema Validation: Ensure data conforms to the expected structure, including data types, column names, and constraints (e.g., a "date" column must contain actual dates).
Range and Format Checks: Verify that values fall within expected ranges (e.g., age between 0-120) and follow correct formats (e.g., valid email addresses, specific product codes).
Consistency Checks: Cross-reference data points to ensure logical consistency (e.g., an order delivery date must be after its order placement date).
Uniqueness Checks: Verify that primary keys or identifiers are unique within the dataset (e.g., customer IDs).
Data Quality Rules: Implement business-specific rules that reflect domain knowledge (e.g., "customer must have at least one valid address").
Automated Tools: Utilize specialized data quality tools or custom scripts to automate validation checks throughout your data pipeline, flagging or quarantining non-compliant data.
Practical Example: Before training an AI model on financial transactions, data validation would automatically check that all transaction amounts are positive, dates are in a consistent YYYY-MM-DD format, and every transaction has a unique ID. It would also flag any entries where the "account balance" doesn't logically follow from previous transactions.
8. Data Splitting: Preparing for Model Training and Evaluation
This final step in data preparation involves dividing your high-quality, prepared dataset into distinct subsets: training, validation, and test. This is essential for accurately evaluating your model's performance and ensuring it generalizes well to unseen data, preventing issues like overfitting or biased performance assessment.
Training Set: This is the largest portion (e.g., 70-80%) used to teach the model patterns and relationships. The AI "learns" from this data.
Validation Set: A smaller portion (e.g., 10-15%) used during model development to fine-tune hyperparameters and make architectural decisions. It helps compare different model configurations and prevent overfitting during iterative development.
Test Set: An independent, unseen portion (e.g., 10-15%) used only once at the very end to evaluate the final, chosen model's performance on new data. This provides an unbiased measure of its real-world accuracy and generalization ability.
Stratified Sampling: For classification problems, use stratified sampling to ensure that the proportion of target classes (e.g., "fraudulent" vs. "non-fraudulent" transactions) is maintained across all splits, preventing class imbalance issues.
Practical Example: For a model predicting customer satisfaction (satisfied/dissatisfied), the prepared customer survey data would be split. 70% would go into the training set to teach the model. 15% would form the validation set to compare different machine learning algorithms (e.g., Logistic Regression vs. Random Forest) and tune their settings. The final 15% would be the test set, used just once to report the model's performance on brand-new customer surveys.
Smarter Growth Starts with Advanced AI
Automate processes, improve predictions, and drive innovation with scalable AI and machine learning solutions tailored to your business.
Even with a structured workflow, the journey to perfectly prepared AI data often presents significant roadblocks. Understanding these common challenges is the first step toward building robust and reliable data pipelines for your AI initiatives.
Incomplete Data: Data is frequently missing values (gaps) in critical fields, which can distort analysis, compromise model accuracy, and lead to biased insights.
Inconsistent Formats: When data is gathered from various sources, it often arrives with mismatched formats for dates, currencies, units of measurement, or text spellings, making unification and processing difficult.
High Volume Data: The sheer scale of big data can overwhelm computational resources, slow down processing performance, and significantly increase storage and operational costs.
Poor Quality (Noise and Outliers): Datasets often contain noisy (irrelevant, erroneous, or corrupted) entries or extreme outliers that can muddle patterns, skew statistical analysis, and lead to incorrect model training.
Data Drift: The underlying statistical properties and relationships within your data can change over time. This "data drift" can cause an AI model's performance to degrade significantly after deployment, as the real-world data no longer matches what it was trained on.
Addressing these challenges is critical for any organization aiming to maximize the potential and reliability of its AI investments.
Best Practices for Effective AI Data Preparation
Overcoming the common challenges in data preparation requires more than just technical steps; it demands a strategic approach and adherence to best practices. Implementing these guidelines throughout your data pipeline ensures high-quality data, leading to more robust and reliable AI models.
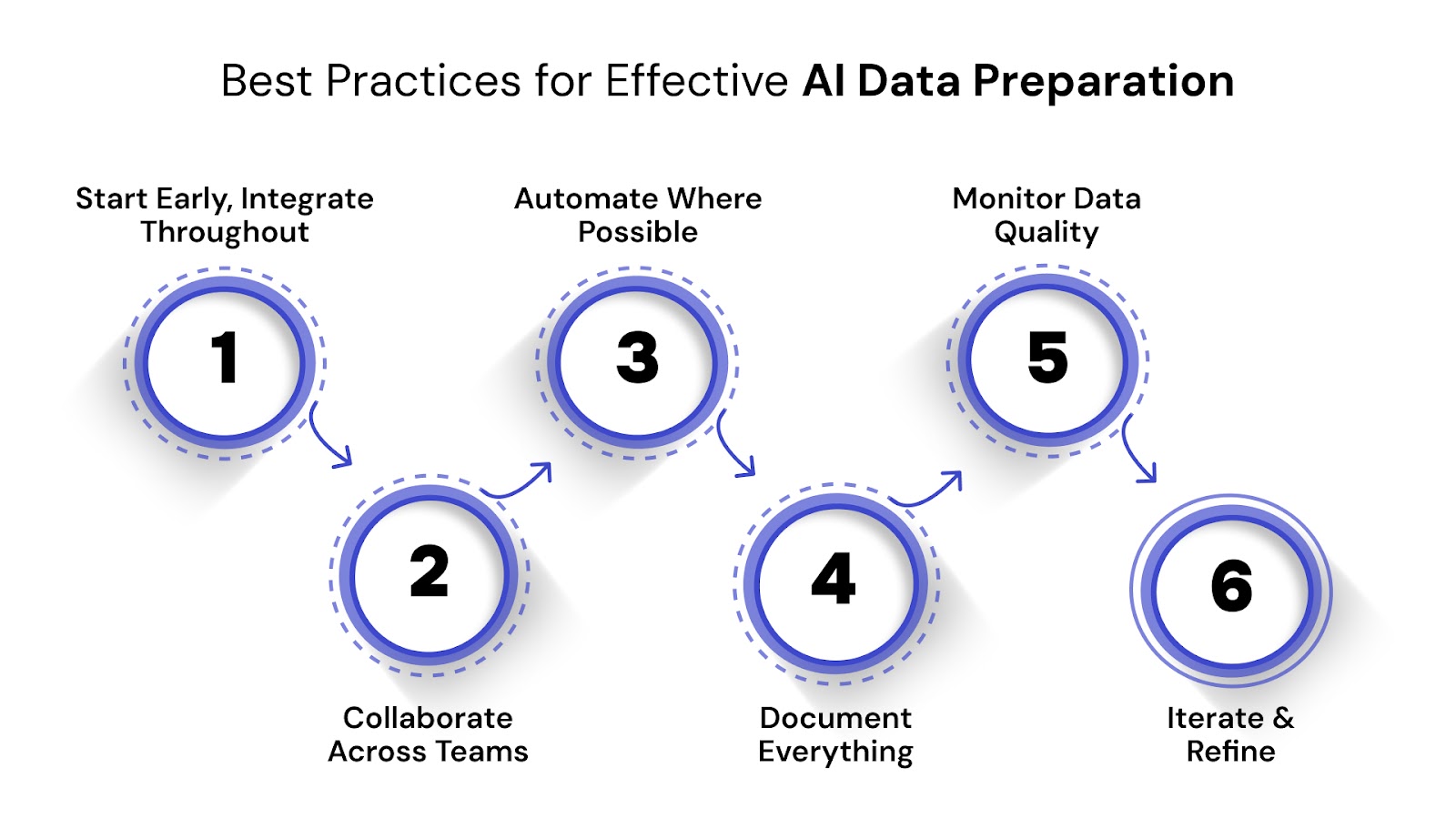
Start Early and Integrate Throughout: Don't treat data preparation as a separate, isolated task. Integrate it into the beginning of your AI project lifecycle, from problem definition and data strategy. Proactive preparation prevents costly rework later on.
Collaborate Across Teams: Data preparation isn't solely a data scientist's job. Foster collaboration between data engineers, data scientists, domain experts, and business stakeholders. Each perspective offers unique insights into data meaning, quality, and relevance.
Automate Where Possible: Manual data preparation is slow, error-prone, and unsustainable at scale. Utilize automation tools and scripting for repetitive tasks like data cleaning, validation, transformation, and pipeline orchestration. This boosts efficiency and consistency.
Document Everything: Maintain thorough documentation of your data sources, schemas, cleaning rules, transformation logic, feature engineering decisions, and validation processes. Clear data lineage ensures transparency, reproducibility, and easier troubleshooting.
Continuously Monitor Data Quality: Data quality isn't a one-time achievement; it's an ongoing process. Implement continuous monitoring systems to detect anomalies, data drift, schema changes, and deviations from expected distributions. Proactive alerts help maintain data integrity over time.
Iterate and Refine: Data preparation is rarely perfect on the first attempt. Embrace an iterative approach. As you train and evaluate your AI models, you'll gain new insights into data quality issues or opportunities for better feature engineering. Use these learnings to refine and improve your data preparation process continuously.
By meticulously applying these best practices, organizations can transform data preparation from a hurdle into a strategic accelerator, building robust data foundations that empower their AI initiatives.
While data preparation presents significant challenges, specialized solutions can streamline this complex yet crucial phase. QuartileX provides a comprehensive platform designed to elevate your data preparation efforts, ensuring your AI initiatives are built on the strongest possible foundation.
QuartileX offers advanced features specifically tailored to address the nuances of AI data preparation:
Automated Cleaning and Transformation: Intelligently identifies and corrects errors, handles missing values, and standardizes formats, automating tedious manual tasks.
End-to-End Pipeline Engineering: Facilitates the design and deployment of robust, scalable data pipelines that seamlessly integrate diverse data sources and automate data flow.
Smart Data Validation and Monitoring: Implements continuous quality checks and real-time monitoring to detect anomalies and data drift, ensuring ongoing data integrity.
Scalable Feature Engineering Frameworks: Provides tools and environments to efficiently create, manage, and select powerful features, optimizing data for superior model performance.
Secure and Compliant Data Governance: Ensures that all data preparation activities adhere to industry standards and regulatory requirements, safeguarding sensitive information.
With QuartileX, you gain the efficiency and reliability needed to transform your raw data into a powerful asset, significantly accelerating your journey to AI success.
Still Evaluating Your Data Priorities? Let’s Simplify That.
We’ll assess your current infrastructure and help you map a smarter, more cost-efficient path forward.
Data preparation is the cornerstone of successful AI implementation. The quality of your data directly dictates the accuracy, reliability, and ultimately, the business value derived from your AI models. Don't let incomplete, inconsistent, or unoptimized data hold back your AI ambitions. Instead, embrace best practices and utilize intelligent solutions to ensure your models are built on a foundation of pristine, high-quality data.
Ready to transform your data into your strongest AI asset? Explore QuartileX's advanced data preparation services today and discover how intelligent automation can accelerate your path to unparalleled AI success.
Frequently Asked Questions (FAQs)
1. What is the main goal of data preparation in AI?
The main goal is to transform raw, messy data into a clean, consistent, and structured format that AI algorithms can efficiently process and learn from, ensuring accurate and reliable model performance.
2. How long does data preparation typically take for AI projects?
Data preparation is often the most time-consuming phase in AI projects, frequently consuming 50% to 80% of a data scientist's project time due to its iterative and meticulous nature.
3. What are the key stages involved in data preparation for AI?
The key stages include data collection & integration, cleaning & pre-processing, transformation & normalization, feature engineering & selection, data labeling, data reduction & sampling, data validation, and data splitting.
4. Is data cleaning the same as data preparation?
No. Data cleaning is a crucial component of data preparation, focusing on identifying and correcting errors, inconsistencies, and missing values. Data preparation is a broader process that includes cleaning, along with integration, transformation, feature engineering, and more.
5. What happens if data is not properly prepared for AI?
Poorly prepared data can lead to inaccurate model predictions, biased outcomes, increased development time, wasted resources, and ultimately, a high likelihood of AI project failure. ("Garbage in, garbage out" applies directly.)
6. Are there specific tools for AI data preparation?
Yes, a range of tools exists from programming libraries (e.g., Python's Pandas, NumPy, Scikit-learn) to specialized platforms (e.g., Alteryx, Trifacta, Talend) and cloud services (e.g., AWS Glue, Azure Data Factory, Google Cloud Dataflow). QuartileX also offers comprehensive solutions in this area.
Let’s Solve Your Data Challenges
From cloud to AI — we’ll help build the right roadmap.

.jpg)