


Businesses are undergoing a profound transformation in how they manage information. According to McKinsey & Company, by 2030, many organizations will reach a state of “data ubiquity,” where information is not just readily accessible but woven into systems, processes, and decision points to power automated actions under thoughtful human oversight.
However, scattered data and disconnected systems currently create significant roadblocks for many companies striving for this seamless integration. To enable your data to drive business growth and achieve such an advanced state, a reliable method for moving and preparing it is essential.
This comprehensive guide provides a practical approach to building powerful data pipelines, helping your organization achieve sustained success and make better, data-driven decisions.
A data pipeline is an automated system designed to move and transform data from various sources to a designated destination, making it ready for analysis, reporting, or operational use. It’s like the central nervous system of your data ecosystem, ensuring that valuable information flows seamlessly and reliably to where it's needed most for critical business functions.
For businesses, the goal is clear: make smart decisions and drive growth. But what happens when the data you need is messy, scattered, or arrives too late? That’s where robust data pipelines become indispensable:
While often used interchangeably, it's crucial to understand the relationship between data pipelines and ETL (Extract, Transform, Load) processes.
Data pipelines are the overarching term for any automated system that reliably moves and processes data from various sources to a destination. These pipelines orchestrate the entire journey, which can involve a range of steps like ingestion, cleaning, transformation, and routing.
ETL (Extract, Transform, Load) represents a traditional and widely used type of data pipeline. It strictly adheres to three sequential phases:
However, with the rise of cloud computing and scalable data warehouses, ELT (Extract, Load, Transform) has emerged as a powerful alternative within the data pipeline ecosystem. In an ELT process, raw data is first extracted from sources and immediately loaded into the destination (often a cloud data warehouse). The transformation then occurs within that powerful target system, building on its immense processing capabilities.
The key difference lies in the sequence of the "Transform" phase and the flexibility it offers. All ETL and ELT processes are forms of data pipelines, but data pipelines encompass a much broader range of data movement and processing methodologies. Understanding these distinctions is vital for choosing the most suitable data strategy for your organization's infrastructure and analytical needs.
Streamline your data pipelines and architecture with scalable, reliable engineering solutions designed for modern analytics.
See Data Engineering Services →
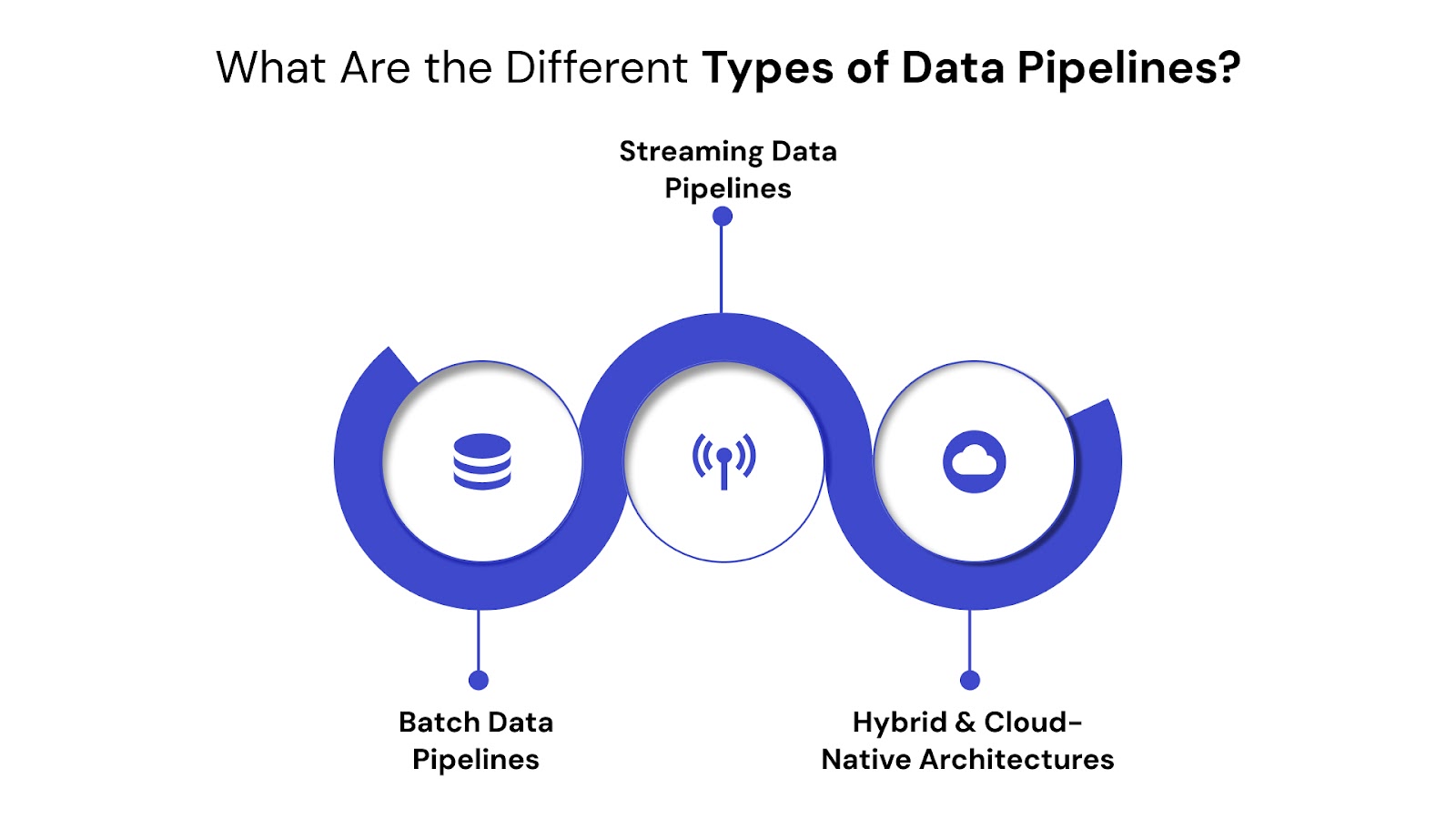
Selecting the appropriate data pipeline architecture is crucial for optimizing data flow and maximizing its value. Not all data needs are the same, and understanding the distinct types helps you build a system that serves your business objectives.
Batch pipelines collect and process data in large blocks (batches) at scheduled intervals. This method is ideal for scenarios where immediate insights aren't critical, but processing large volumes of historical or periodic data is essential.
Streaming pipelines process data continuously, as it is generated, allowing for near-instantaneous insights and actions. This method is vital for applications requiring real-time responsiveness.
Modern enterprises often adopt hybrid models, combining batch and streaming pipelines to meet diverse needs. Furthermore, building pipelines on cloud infrastructure (like AWS, Azure, GCP) provides unmatched scalability (handling fluctuating data volumes automatically), cost-efficiency (pay-as-you-go models), resilience, and faster time-to-market for new data initiatives.
These platforms offer managed services that reduce operational overhead, allowing your teams to focus on data innovation rather than infrastructure management.
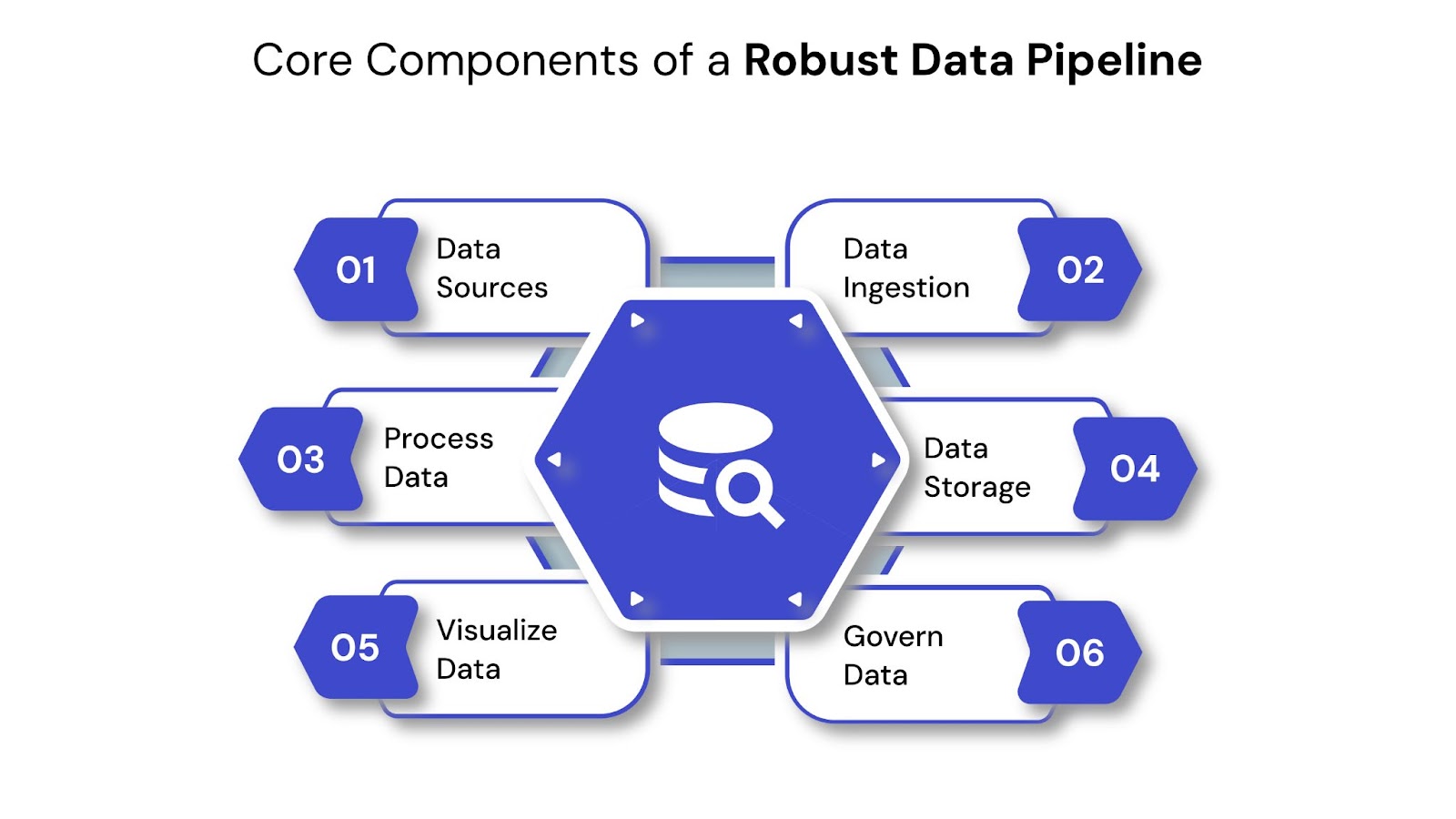
Building an effective data pipeline requires understanding its fundamental building blocks. Each component plays a vital role in ensuring data moves efficiently, is transformed accurately, and remains ready for consumption.
This is where your data originates. A robust pipeline must connect to diverse sources across your enterprise and external systems. These can include internal transactional databases (like PostgreSQL, Oracle), enterprise applications (CRM such as Salesforce, ERP systems like SAP), IoT devices, website clickstreams, social media feeds, flat files (CSV, XML), or third-party APIs. Identifying and connecting to all relevant sources is the first critical step.
Once identified, data must be collected and brought into the pipeline. This component handles the actual process of reading data from the sources. Ingestion can occur in batches, involving scheduled transfers of large data volumes, or in real-time streams for a continuous flow of data. Tools designed for ingestion often provide connectors to various sources and manage the initial data collection.
After ingestion, data often needs cleaning, structuring, and enrichment to become truly useful. This is where raw data is refined. This stage involves tasks such as filtering irrelevant data, handling missing values, standardizing formats, joining data from multiple sources, aggregating information, and applying business rules.
The ultimate goal here is to transform raw data into a consistent, high-quality format suitable for analysis and downstream applications.
Processed data needs a place to reside, ready for access and analysis. The choice of storage depends heavily on the data's nature and its intended use cases.
Options typically include data lakes for raw or semi-structured data (like Amazon S3, Azure Data Lake Storage), data warehouses for structured, transformed data optimized for analytics (such as Snowflake, Google BigQuery, Amazon Redshift), or specialized databases tailored for specific needs.
This is the final destination, where the processed data is used to generate insights and drive action. Data is typically delivered to business intelligence (BI) dashboards, reporting tools, analytical applications, or even directly to other operational systems. This stage ensures the data becomes actionable for decision-makers and end-users across the organization.
Crucial for any enterprise-grade pipeline, this component ensures data is managed responsibly, securely, and compliantly throughout its lifecycle.
This involves defining clear data quality standards, implementing robust access controls, encrypting sensitive data, ensuring adherence to regulations (like GDPR, HIPAA), and meticulously tracking data lineage (where data came from and how it was transformed). Establishing continuous monitoring and alerting for data issues or security breaches is also a key part of this ongoing process.
To discover the specific tools that power each stage, explore our comprehensive guide on Top Data Pipeline Tools.
Build high-performance pipelines that keep your data flowing reliably — from ingestion to insight.
Build with Data Engineering →
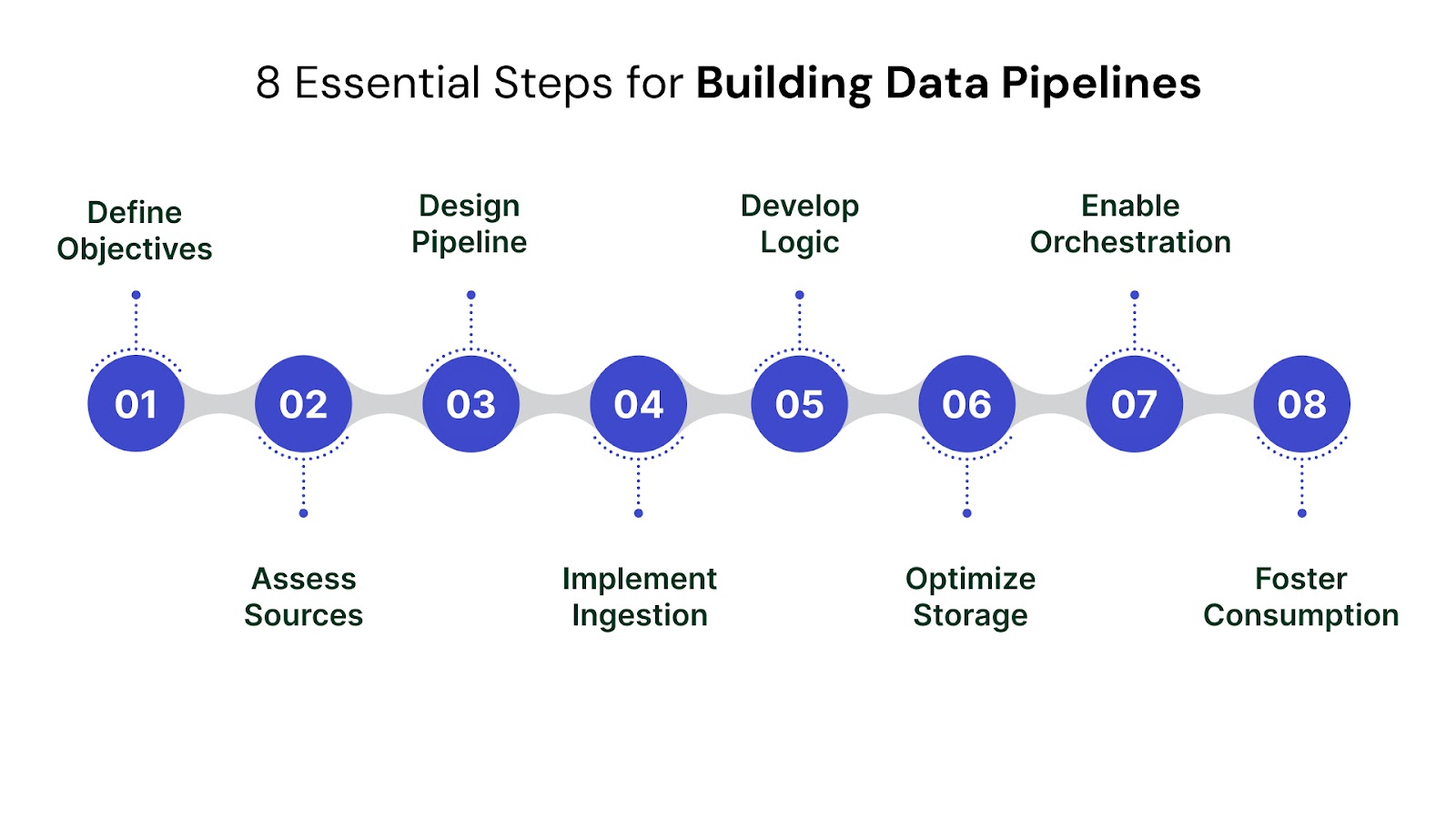
Building a robust data pipeline is a strategic investment that transforms raw data into a powerful asset. This isn't just a technical task; it's a phased journey that requires careful planning, execution, and continuous optimization.
Here’s a clear, actionable blueprint for businesses looking to establish reliable data pipelines:
Before writing a single line of code or choosing any tool, clarify why you're building this pipeline. What business problems will it solve? What decisions will it enable?
Questions to Ask:
Actions:
Understand where your data resides and its current state. Data quality at the source directly impacts the pipeline's output.
Questions to Ask:
Actions:
Based on your objectives and source assessment, design the overall structure of your pipeline. This involves selecting the right architecture (batch, streaming, or hybrid) and defining the flow.
Questions to Ask:
Actions:
This step focuses on actually getting data from your sources into the pipeline.
Questions to Ask:
Actions:
Transform raw, ingested data into a clean, consistent, and usable format. This is where data gains its analytical value.
Questions to Ask:
Actions:
Determine where your processed data will reside, ensuring it's accessible and optimized for its intended use.
Questions to Ask:
Actions:
Automate, manage, and oversee your pipeline to ensure its smooth and continuous operation.
Questions to Ask:
Actions:
For a detailed look into ensuring the accuracy and reliability of your pipelines, read our in-depth Guide to Data Pipeline Testing Tools, Approaches, and Steps.
The ultimate goal is to make data accessible and valuable to end-users. Pipelines are not static; they evolve.
Questions to Ask:
Actions:
By meticulously implementing this blueprint, businesses can move beyond basic data management, establishing strategic pipelines that consistently deliver reliable, high-value data to power critical operations and future innovation.

Even with a solid blueprint, building and maintaining enterprise-grade data pipelines comes with its share of complexities. Understanding these common challenges and their strategic solutions is crucial for long-term success.
Handling these complexities requires not just technical acumen, but also a strategic vision for data, turning potential roadblocks into opportunities for growth.
While the blueprint provides clarity, executing it effectively requires specialized expertise and a deep understanding of enterprise-grade challenges. QuartileX partners with businesses like yours to design, implement, and optimize data pipelines that are functional and future-ready.
Here's how QuartileX makes a difference:
Choosing the right partner transforms data pipeline development from a complex technical hurdle into a strategic advantage, propelling your enterprise towards data-driven excellence.
No templates, no shortcuts — just tailored solutions built around your business, goals, and team.
Get Started with a Free Consultation →
Building effective and scalable data pipelines is no longer an option, but a fundamental necessity for businesses aiming to succeed and lead in a data-driven world. By strategically defining objectives, meticulously assessing data, designing for resilience, and implementing each step with precision, your organization can transform raw data into its most valuable asset.
Embrace this blueprint, empower your teams with clean, accessible data, and watch your business move forward with confidence and clarity.
Ready to transform your data into a powerful engine for growth? Connect with QuartileX today for a consultation on building your future-ready data pipelines.
While all ETL (Extract, Transform, Load) processes are a type of data pipeline, data pipelines are a broader concept. ETL specifically means data is transformed before loading into a destination, typically in batches. A data pipeline encompasses any automated flow of data, including real-time streaming, ELT (Extract, Load, Transform), or even simple data movement without complex transformations.
Manual processes and simple scripts are prone to human error, are difficult to scale with growing data volumes, lack robust error handling, and become unsustainable for timely insights. Data pipelines automate these tasks, ensuring data accuracy, consistency, and availability at scale, which is crucial for data-driven decision-making in enterprises.
Data quality is critical. It's ensured by implementing validation rules at the ingestion stage, applying cleansing and transformation logic during processing, and setting up continuous monitoring with alerts for anomalies. Establishing clear data governance policies and data ownership also plays a vital role.
Building in-house offers control but requires significant investment in specialized talent, infrastructure, and ongoing maintenance. Partnering with external experts provides access to proven methodologies, cutting-edge technologies, and deep industry experience, accelerating implementation, optimizing costs, and mitigating risks, especially for complex or strategic pipelines.
Data pipelines provide a continuous supply of clean, structured, and timely data, which is the essential fuel for advanced analytics, machine learning models, and complex business intelligence. By ensuring data readiness, pipelines enable businesses to quickly adopt and benefit from future analytical innovations.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


