
.png)

Over 60% of organizations now deploy data pipeline tools, with the market growing from $11.24B in 2024 to $13.68B in 2025. A data ingestion framework is a structured system that automates data extraction, validation, and transfer. It moves data from multiple sources into destinations like cloud lakes, warehouses, or real-time engines.
This guide explains what is a data ingestion framework, why it matters amid this boom, and how to apply it in high-demand environments. You’ll explore its structure, types, tools, and strategies to tackle data ingestion challenges effectively. This guide provides the tools and insights you need to excel in data ingestion and achieve your career goals.
Data ingestion frameworks differ based on how and where data needs to move—whether in scheduled batches to a data warehouse or in real time to stream processors. Architecture choices depend on factors like source system compatibility, processing frequency, and target environment. Knowing the core types and components helps you design pipelines that meet scale, speed, and reliability goals.
Let’s start with the basics: what is data ingestion framework?
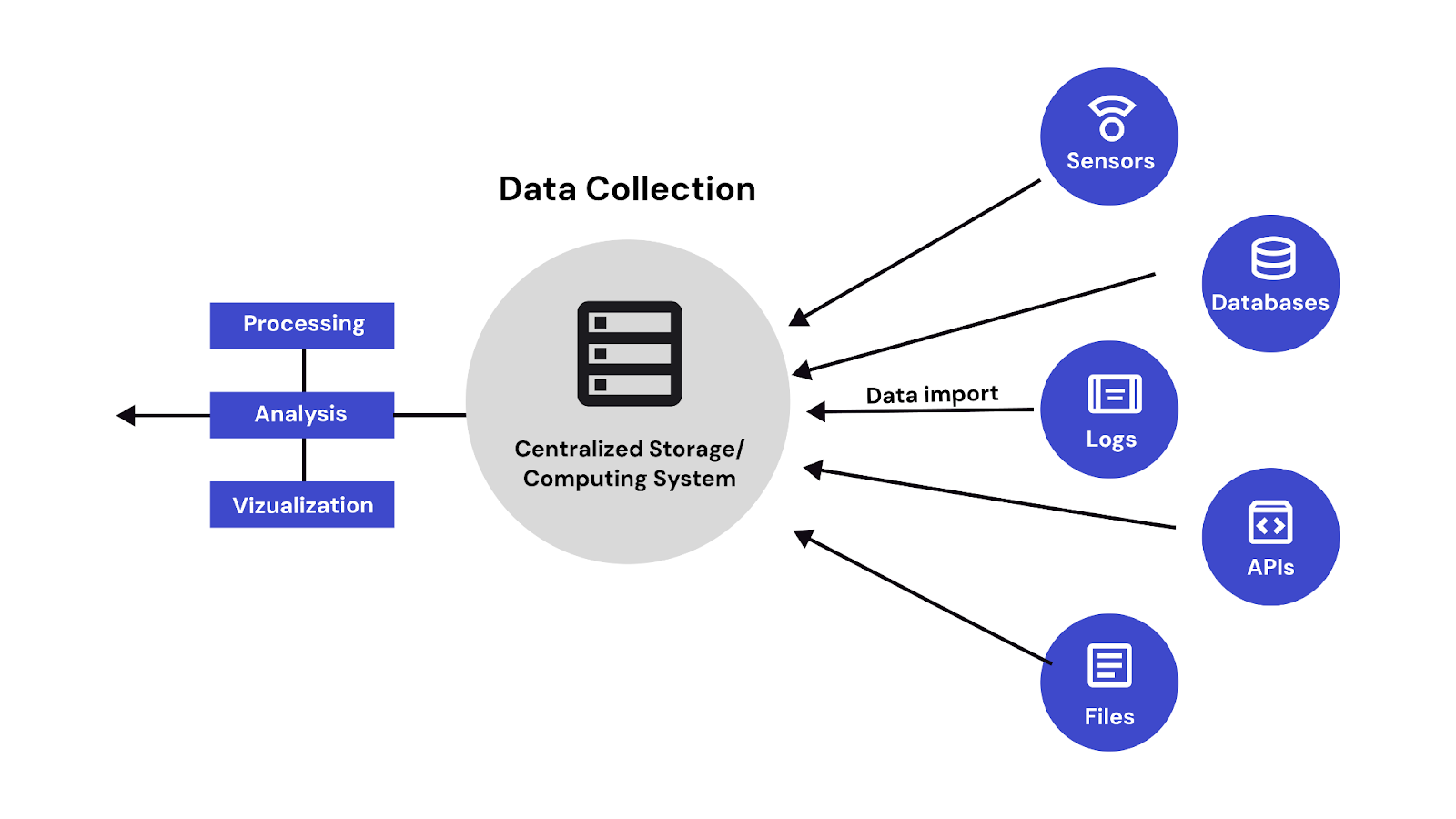
A data ingestion framework is a standardized system that automates the collection, formatting, and movement of data from multiple sources to storage or processing environments. It ensures consistency, fault tolerance, and scalability across ingestion workflows.
Think of a data ingestion framework like a metro rail system:
Unlike individual ingestion tools, which handle isolated tasks, a framework integrates connectors, validation, monitoring, and delivery into a cohesive pipeline.
Curious about what's next in data ingestion? Read our in-depth guide on Data Ingestion: Challenges, Best Practices, & Future Trends to stay ahead of scaling issues and evolving tech.
Now that you know what a data ingestion framework is and how it works, let’s look at the main architectural models used to build them.
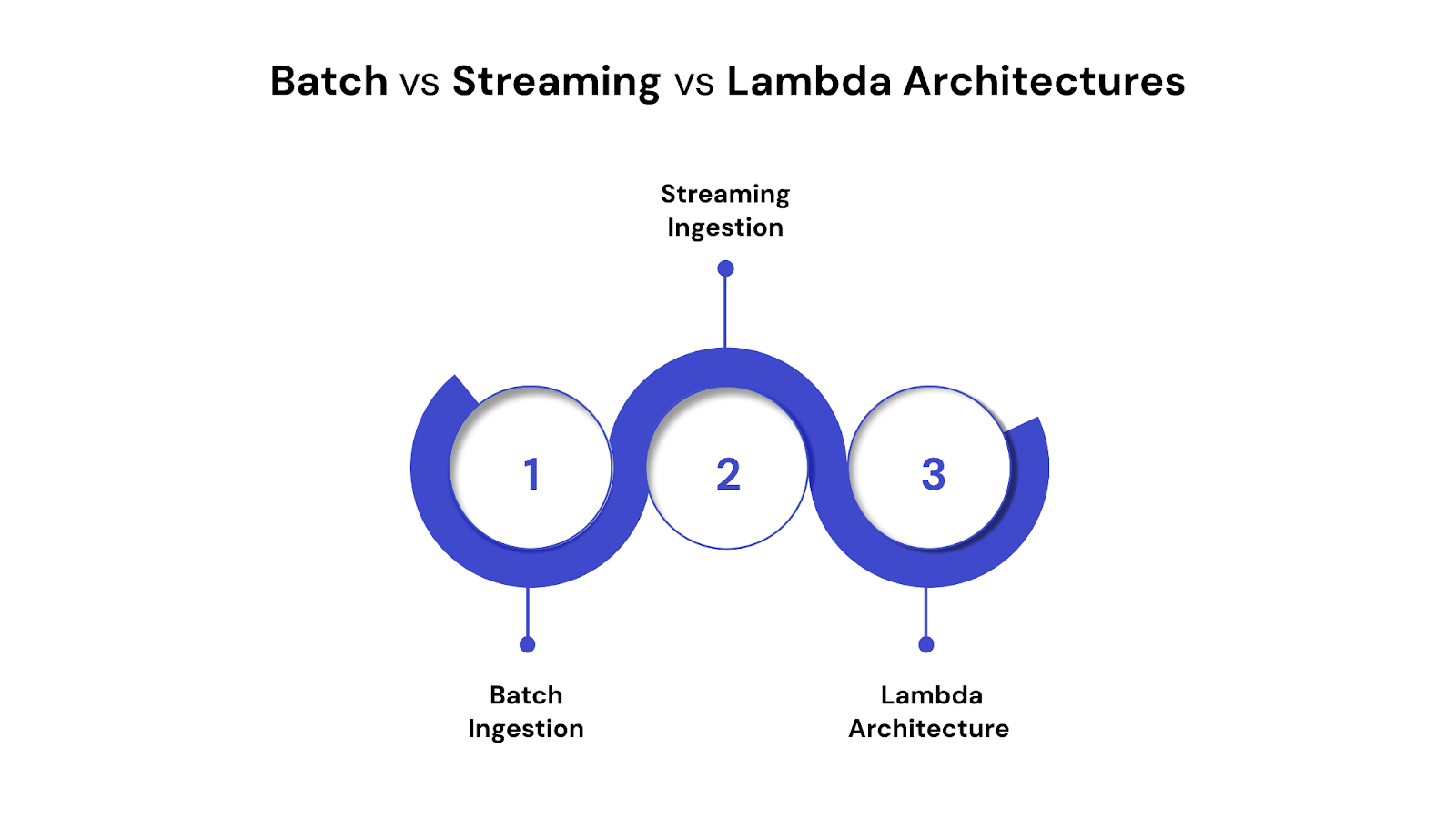
Data ingestion frameworks use different architectural models based on latency needs, system complexity, and processing goals. The three most common approaches are batch, streaming, and lambda architectures—each with distinct advantages and trade-offs.
1. Batch Ingestion
Batch processing collects and processes data in fixed-size chunks at scheduled intervals (e.g., hourly or daily).
Use Case: Loading sales data from POS systems into a data warehouse every night.
2. Streaming Ingestion
Streaming processes data continuously as it arrives, often in real time or near-real time.
Use Case: Monitoring transaction fraud or user activity in live apps.
3. Lambda Architecture
Lambda combines both batch and streaming layers to support real-time views with historical completeness.
Use Case: An analytics dashboard that shows current user behavior alongside historical trends.
Batch vs Streaming vs Lambda
Want to understand how ingestion fits into the bigger picture? Check out our blog on Data Pipelines Explained: Everything You Need to Know for a complete view of how data moves, transforms, and powers insights.
To build a reliable and scalable data ingestion framework, it’s essential to understand the core components that make up its architecture. These elements work together to ensure consistent data flow, fault tolerance, and processing efficiency.
Key Components of a Data Ingestion Framework
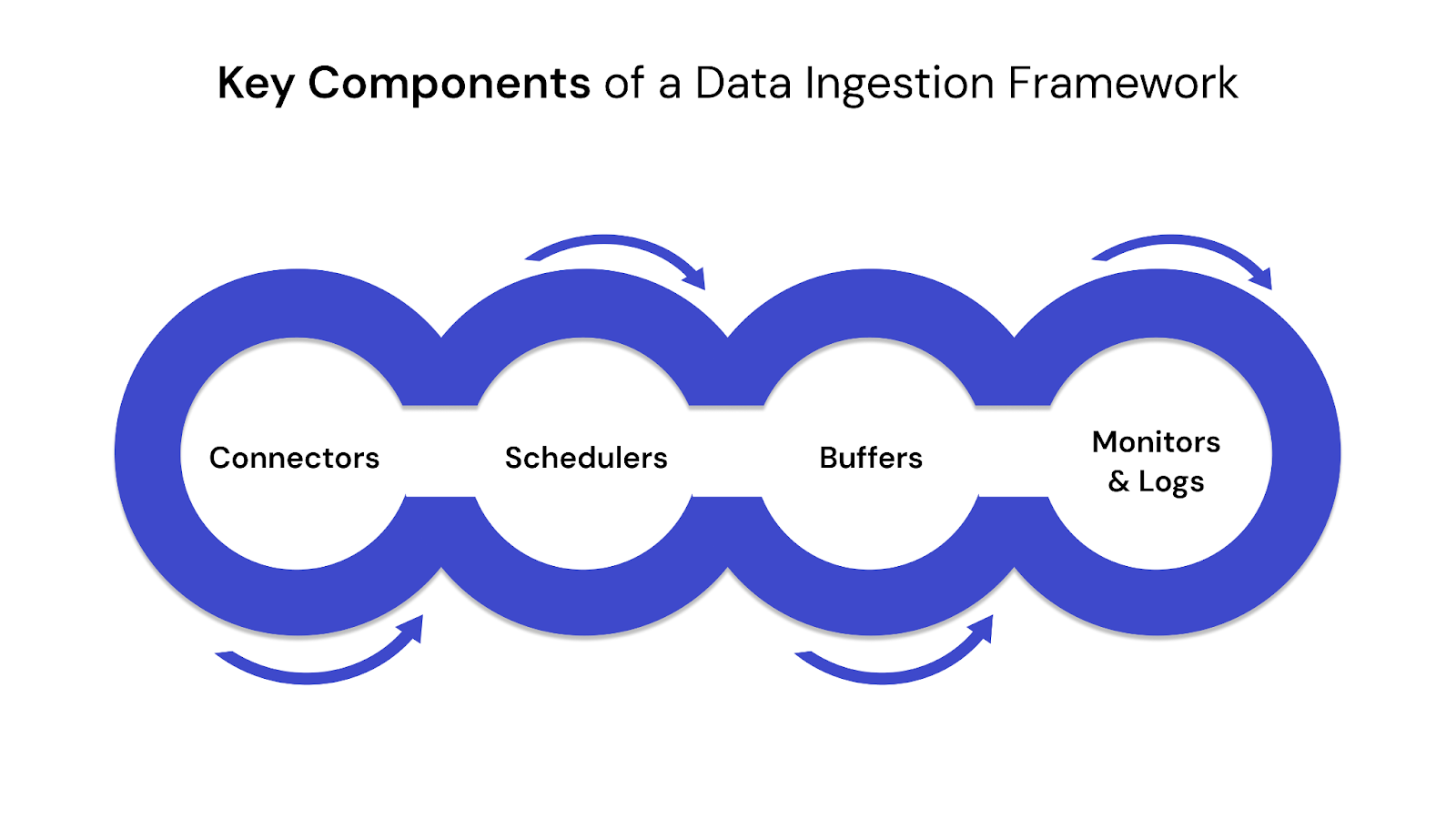
1. Connectors
Interface modules that link source systems (e.g., APIs, databases, sensors) with the ingestion pipeline.
2. Schedulers
Manage when and how often data is pulled or pushed into the system.
3. Buffers
Temporarily hold data during transfer between components to prevent loss or overload.
4. Monitors & Logs
Track pipeline health, detect failures, and record events for debugging or audits.
Modern data ecosystems depend on seamless and scalable ingestion to support analytics, automation, and AI workloads. As businesses shift to cloud-native architectures and real-time decision-making, the volume, variety, and velocity of data have grown exponentially. A data ingestion framework ensures that this data flows efficiently from diverse sources into centralized platforms—without bottlenecks or quality issues.
By standardizing ingestion workflows, these frameworks help organizations maintain performance, scale operations, and ensure that data is accurate, complete, and ready for downstream use.
Benefits of Using Data Ingestion Frameworks
Optimize your data infrastructure with modern pipelines and architecture that enable faster analytics and smarter decisions at scale.
Future-Proof Your Data Stack →
A wide range of tools and frameworks support data ingestion today, each with its own strengths, integrations, and trade-offs. Selecting the right tool depends on your project’s data volume, latency requirements, team skillset, and integration ecosystem. Factors like tool maturity, cloud compatibility, community support, and extensibility often influence the decision.
The table below compares commonly used ingestion tools based on their strengths, ideal use cases, and practical considerations:
Tip: Consider not just features, but also ecosystem alignment. For example, Kafka pairs well with real-time analytics stacks, while Fivetran suits fast BI onboarding.
Looking for the right tools to build smarter pipelines? Explore our blog on Data Ingestion Tools: Fueling Smarter Data Pipelines to compare top solutions and pick the best fit for your data stack.
While off-the-shelf tools cover most needs, some situations call for a custom ingestion framework:
Move your databases to modern platforms with zero downtime, optimized performance, and complete peace of mind.
Upgrade Your Data Systems →
Build vs Buy: Key Trade-offs
Decision-Making Checklist
Before choosing a path, ask:
While data ingestion frameworks offer automation, scalability, and reliability, they are not immune to challenges—especially during deployment, scaling, and ongoing governance. Real-world systems often face issues related to inconsistent data sources, infrastructure limitations, and regulatory obligations. Addressing these challenges early helps prevent pipeline failures, data corruption, and compliance gaps.
Ingestion frameworks must manage high data volume, fast data velocity, and wide data variety, often simultaneously. These “3 Vs” can lead to reliability and performance issues when not properly addressed.
Key Problems:
Practical Solutions:
Ensure compliance, transparency, and security across your data lifecycle with expert governance frameworks tailored to your needs.
Improve Data Governance →
Data ingestion pipelines often handle sensitive information—especially in regulated sectors like finance, healthcare, and government. Ensuring data integrity, privacy, and auditability is critical throughout the ingestion process.
Key Risks:
Best Practices:
Many data ingestion issues can be avoided with thoughtful design and robust operational practices. Whether you're handling terabytes of batch data or streaming events in real time, a well-architected framework ensures consistency, performance, and resilience. This section focuses on key strategies to make your ingestion pipeline scalable, fault-tolerant, and aligned with downstream systems.
To handle growth and failures gracefully, your ingestion framework must be built with resilience in mind.
Key Practices:
Even if ingestion works smoothly, poor downstream integration can introduce data loss, latency, or format mismatches.
Challenges & Solutions:
Tool Compatibility Tips:
Ready to build your own data pipeline? Read our guide on Steps to Build a Data Pipeline from Scratch for a clear, actionable roadmap from design to deployment.

A well-structured data ingestion framework ensures seamless data flow, scalability, and reliability. QuartileX specializes in designing robust ingestion solutions that handle diverse data sources while maintaining high performance and data integrity.
We offer:
Plan for future data growth with scalable architectures.
No templates, no shortcuts — just tailored solutions built around your business, goals, and team.
Get Started with a Free Consultation →
A well-designed data ingestion framework is essential for building scalable, secure, and high-performance data systems. Choosing the right approach depends on your specific data sources, latency requirements, and system architecture. Understanding what is data ingestion framework and how its components, types, and tools function allows you to make informed decisions that align with both technical and business goals.
To avoid common data ingestion challenges, prioritize frameworks that are modular, support monitoring, and can adapt as your workloads grow. Start small with a trusted, well-documented tool, monitor key metrics, and scale based on real usage data.
Ready to optimize your data ingestion strategy? Connect with our data experts today to explore tailored solutions that drive better insights and business growth.
A: A data ingestion framework is a scalable, reusable system that automates how data is collected, validated, and delivered to target platforms. Unlike ad hoc ETL scripts, frameworks offer fault tolerance, monitoring, and support for real-time or batch pipelines. They’re ideal for large-scale systems where data quality, uptime, and performance matter.
A: Use a data ingestion framework when your project needs high customization, control over performance, or support for legacy systems. Frameworks are also preferred when tool licensing costs are high or specific ingestion patterns aren’t supported by off-the-shelf solutions. They give more flexibility but require internal engineering resources.
A: Key data ingestion challenges include data duplication, loss due to failure, inconsistent formats, and integration latency. These can be mitigated using checkpointing, schema validation, retry logic, and transformation layers. Monitoring tools also help detect bottlenecks early and maintain pipeline health.
A: Choose batch for scheduled, high-volume transfers with relaxed latency. Opt for streaming when real-time data (like logs or transactions) is critical. Lambda architectures combine both and are best when you need immediate insights plus historical accuracy—though they’re more complex to maintain.
A: Build your data ingestion framework with modular components, retry mechanisms, buffer queues, and monitoring systems. Use autoscaling in cloud setups and integrate schema registries for managing change. Align the ingestion flow with downstream systems to avoid backpressure and data sync issues.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


