
.jpg)

Data pipeline testing tools, methods, and best practices help catch data quality issues before they reach dashboards, reports, or machine learning models. As teams adopt cloud-native data stacks and automate pipelines with tools like dbt, Airflow, and Snowflake, testing ensures each stage performs as expected.
A recent Monte Carlo survey found that 31% of companies face revenue impact from poor data quality. This guide shows how to test data pipelines and build systems you can trust in production.
Testing is not optional in modern data systems. It is the only way to ensure that every stage of a data pipeline, from ingestion to transformation, works as expected under real workloads. Without consistent testing, flawed data can silently flow into business-critical reports, decisions, and applications.
Poorly tested pipelines introduce risks that directly affect business operations. When inaccurate data enters dashboards, teams make decisions based on false signals. This can trigger regulatory penalties in finance or misdiagnoses in healthcare.
Failures like these erode trust in dashboards, forecasts, and models, often forcing organizations to halt analytics projects altogether.
Looking to understand the full lifecycle behind what you're testing? Explore how data pipelines are built, managed, and optimized from end to end.
Data pipelines can fail at multiple points. These failures may not be immediately visible but often cause major downstream damage.
Common failure points include:
Example: A retail company added a new payment type in its source database. Due to lack of schema testing, the ETL job dropped those records. Sales dashboards underreported revenue by 12% for a full quarter before the issue was caught.
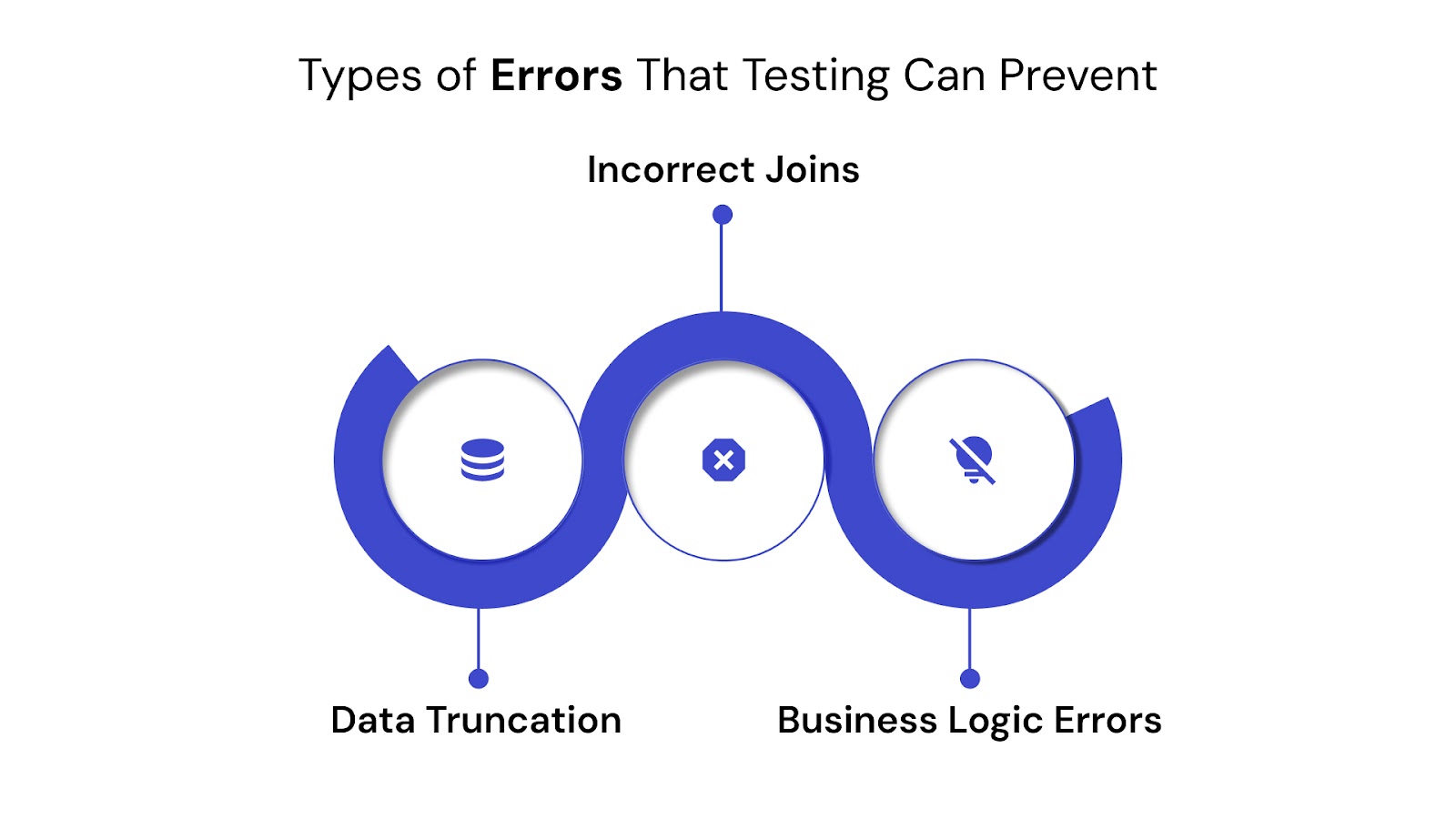
Structured testing practices are designed to catch known failure patterns early.
Build interactive dashboards and visual systems that translate complex data into clear, actionable insight — when and where it matters most.
Design Smarter Dashboards →
Using tools like Great Expectations or dbt tests can automate many of these validations. Proactive testing avoids extensive downstream rework, keeps pipeline logic maintainable, and prevents decision paralysis caused by unreliable metrics.
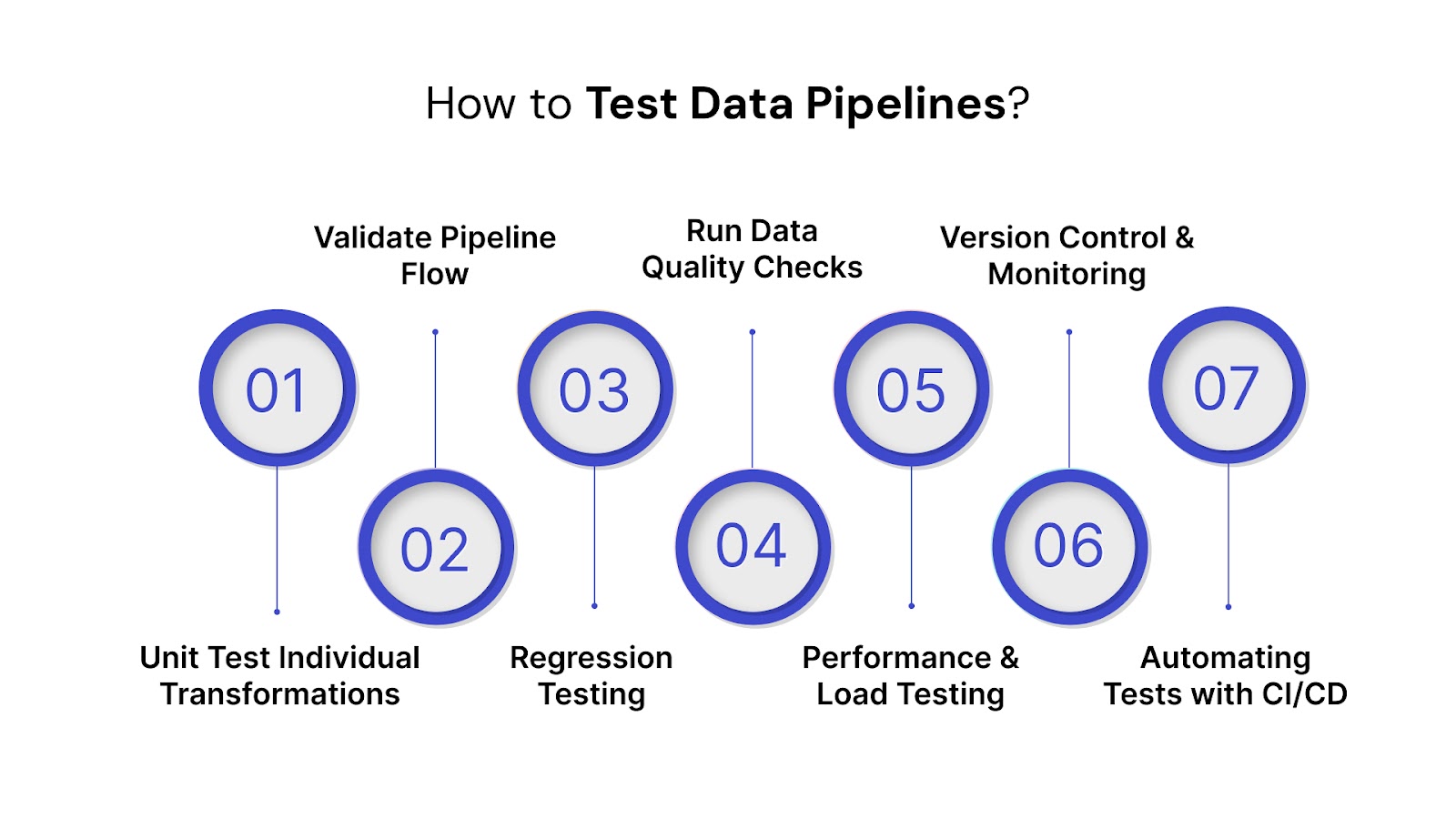
Testing a data pipeline requires more than basic checks. Each component: transformation logic, data flow, and performance, needs its own method of validation. This section breaks down the key test types and how to implement them in production-grade workflows.
Unit testing focuses on verifying small, isolated components of your pipeline logic, such as transformation functions or SQL scripts. These tests ensure specific operations behave as expected for known inputs.
Integration tests verify the interaction between multiple pipeline components—from source ingestion to final output. End-to-end tests validate the complete pipeline execution across systems.
Curious how these tests fit into a real pipeline setup? Learn how to build a reliable data pipeline from the ground up, step by step.
Regression testing ensures that new code or config changes do not introduce errors in previously working components. This is crucial in fast-moving data teams where deployments happen frequently.
Data quality checks detect issues such as unexpected nulls, duplicates, or invalid values. These checks validate the trustworthiness of your pipeline outputs.
Load testing verifies that your pipeline performs well under realistic data volumes. This is vital for batch pipelines with SLA commitments or streaming systems handling bursts.
Versioning your test cases and test data ensures reproducibility and controlled updates. It also enables safe rollbacks and test traceability.
Automated tests catch issues before bad code reaches production. Integrating testing into your CI/CD pipeline ensures every update is validated in staging.
Optimize your data infrastructure with modern pipelines and architecture that enable faster analytics and smarter decisions at scale.
Future-Proof Your Data Stack →
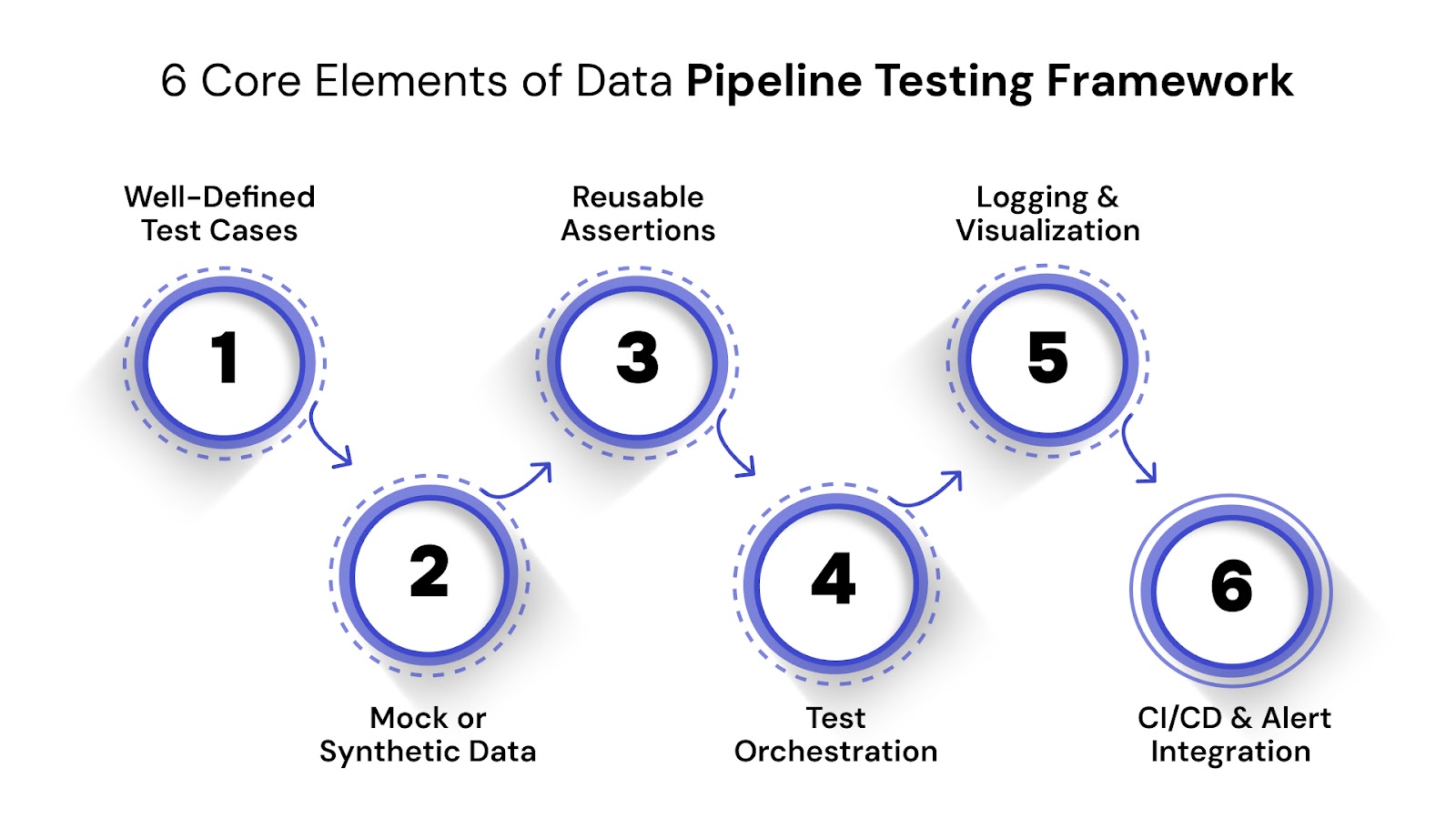
A reliable data pipeline testing framework is built with clear test cases, reusable logic, and automated execution. These components ensure your pipelines behave as expected across environments and data conditions. Below are the foundational pieces every framework should include.
Test cases provide structure to your validation process. They define what needs to be checked, under what conditions, and what outputs are expected.
Want a focused breakdown of testing strategies? Check out this detailed guide on tools, testing approaches, and key steps to strengthen your pipelines.
Mock data allows pipelines to be tested safely and repeatedly across edge cases.
Assertions define what success or failure looks like for each test.
Tests need to run consistently across dev, staging, and production environments.
Logging enables traceability and quick resolution of failures.
Automation ensures issues are caught before they affect production.
Selecting the right testing tool depends on your data stack, pipeline complexity, and team workflow. While some tools offer rich assertions for SQL pipelines, others are optimized for large-scale distributed systems. This section outlines top open-source and cloud-native options, key features to evaluate, and how to make the right call for your team.
Open-source tools are widely adopted for their flexibility, community support, and extensibility. They’re ideal for teams using SQL-based pipelines, Python-based transformations, or open orchestration systems.
Each tool varies in extensibility, test authoring style (SQL, YAML, code), and integration scope. Great Expectations and dbt offer strong documentation and active communities, while Deequ suits big data teams using Apache Spark.
Cloud-native tools simplify setup and scaling by integrating directly into your cloud ecosystem. They reduce infrastructure overhead and are ideal for teams already committed to a specific platform.
These tools are easy to integrate into cloud-native workflows but often come with limitations like platform lock-in and less flexible test authoring. Cross-cloud testing becomes challenging if your stack is hybrid or evolving.
Want to explore the best tools powering your pipelines? Dive into this ultimate guide to top data pipeline tools for 2025.
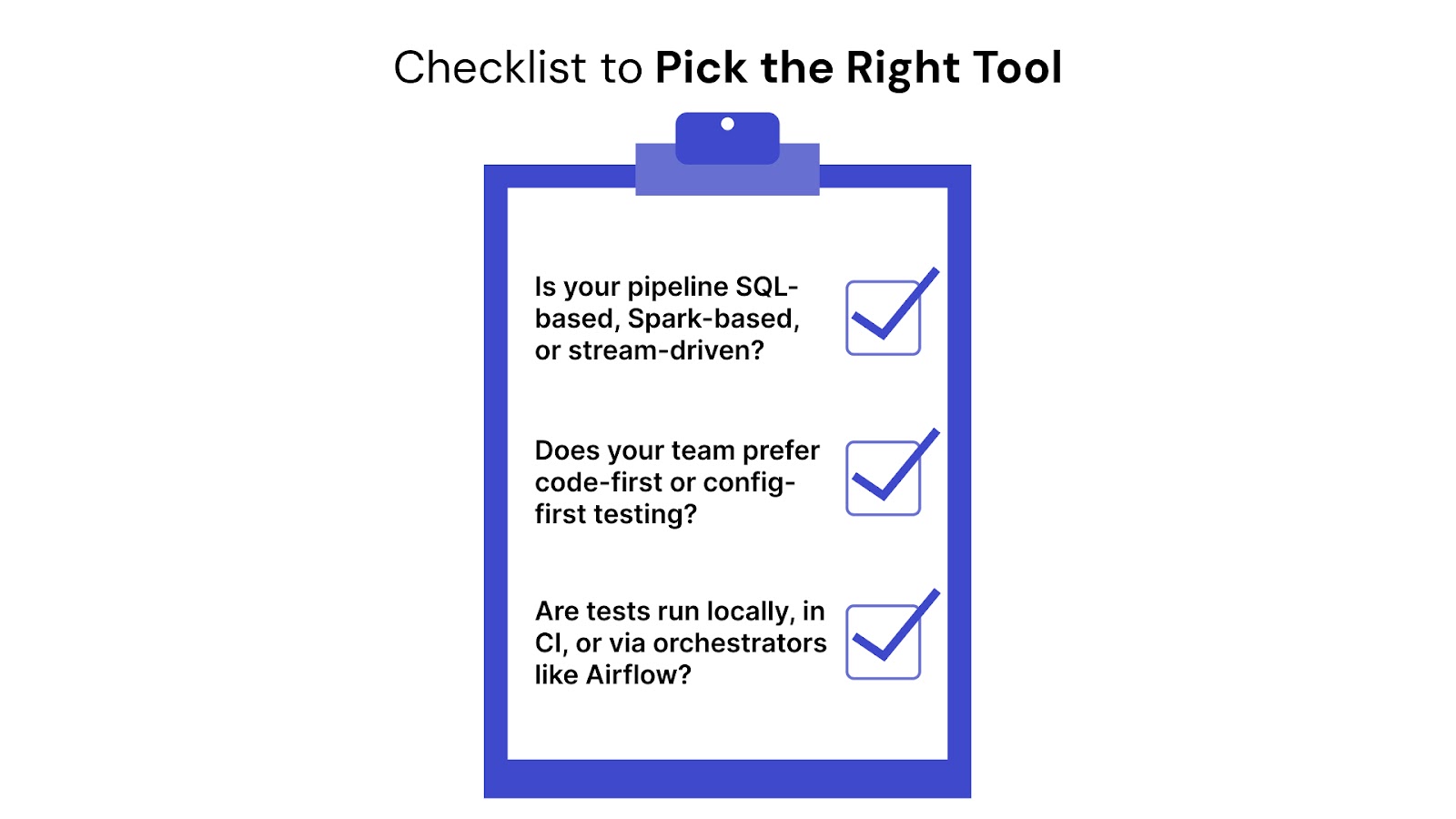
Before choosing a tool, check for critical capabilities that align with your pipeline structure and testing goals.
Tool selection should match your team’s workflow, infrastructure, and skill level. A structured evaluation process avoids poor long-term fit.
Looking to scale your pipelines next? Discover how to build and design data flows that grow with your needs in this in-depth guide.
QuartileX helps organizations streamline and strengthen their data pipeline testing with a focused suite of tools designed for reliability, scalability, and governance. Built with modern data environments in mind, QuartileX supports both batch and streaming pipelines, offering flexible integration and automation capabilities that fit seamlessly into existing workflows.
Key features include:
No templates, no shortcuts — just tailored solutions built around your business, goals, and team.
Get Started with a Free Consultation →
QuartileX is particularly well-suited for teams seeking to enforce high data quality standards while maintaining agility in complex, fast-moving environments. Whether you're scaling existing pipelines or implementing testing for the first time, QuartileX provides the operational visibility and control needed to manage data at scale, without adding unnecessary overhead.
Testing ensures your data pipelines are accurate, consistent, and production-ready. Use the right tools, automate key test types, and embed testing into your development lifecycle. Focus on early detection to avoid costly cleanup and delays. Clean pipelines drive faster insights and more reliable decision-making.
Many teams still rely on manual checks or incomplete test coverage, leading to avoidable errors and system failures. QuartileX helps data teams build robust, scalable testing frameworks tailored to their pipelines and stacks. We support everything from test strategy to automation across cloud-native and hybrid systems.
We’ll assess your current infrastructure and help you map a smarter, more cost-efficient path forward.
Request a Readiness Assessment →
Get in touch with our data experts to audit your pipeline health, improve test reliability, and build a future-proof testing strategy.
A: Data pipeline testing verifies the accuracy, completeness, and performance of data workflows across ETL stages. It ensures that broken logic, schema mismatches, or bad data do not propagate to dashboards or models. This prevents costly business errors and builds trust in analytics systems.
A: Great Expectations and dbt tests are two of the most popular data pipeline testing tools for SQL workflows. They allow teams to define expectations and assertions directly in transformation logic. Both offer strong documentation and are easy to integrate with CI/CD systems.
A: Start by evaluating your stack—whether it's SQL, Spark, or streaming—and your team's preference for code-first or config-driven tools. Run short POCs with tools like Soda Core, Apache Deequ, or dbt tests to assess fit, flexibility, and automation support.
A: Use a layered approach that includes unit tests for logic, integration tests for pipeline flow, and regression tests after changes. Automate testing with GitHub Actions or Airflow hooks to catch issues early. Monitoring tools and alerting systems help maintain stability in production.
A: Some tools like Apache Deequ and Soda Core support both batch and streaming pipelines, depending on how they're configured. For streaming systems, ensure the tool supports event-time validation and real-time assertions. Always review documentation for compatibility with your orchestration layer.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


