


Did you know? Unstructured data now accounts for up to 90% of enterprise data. Managing it efficiently starts with choosing the right data engineering tools.
With businesses adopting cloud-native platforms and real-time analytics, there's a growing need for tools that can handle massive data volumes from IoT devices, APIs, logs, and user-generated sources. Modern data engineering tools help reduce latency, prevent pipeline failures, and maintain high data quality across systems.
This guide introduces you to the top data engineering tools of 2025. You'll explore tools across ingestion, processing, storage, orchestration, governance, and visualization, along with their key features, best use cases, strengths, and limitations.
TL;DR
If you're handling massive analytics workloads or real-time insights from streaming sources, aligning your data engineering stack with these tools ensures performance, reliability, and scale.
Data engineering tools manage the movement, processing, transformation, and quality of data across different stages of a modern pipeline. They handle raw, structured, and unstructured data from diverse sources and move it through systems such as data lakes, warehouses, and real-time engines.
The role of these tools is to automate the heavy lifting in data pipelines enabling storage, processing, scheduling, monitoring, and visualization with reliability and speed.
Data engineering tools are not limited to ETL alone. They span broader workflows including streaming pipelines, quality testing, governance, and orchestration.
The tools listed below cover all key stages of the data pipeline, including ingestion, processing, storage, orchestration, and governance.

The data engineering market is expected to cross 105.59 billion dollars by 2033, driven by the shift to cloud platforms, real-time systems, and large-scale analytics. As businesses collect data from hundreds of sources, selecting the right tools becomes essential for efficiency, speed, and scalability.
Let’s now explore how data engineering is structured across key functional areas, starting with data ingestion tools.
Data ingestion is where everything starts, and getting it wrong means everything downstream suffers. You need tools that can handle different data sources, manage varying volumes, and keep everything flowing smoothly.
Let's look at three tools that have proven themselves in this space.
Redpanda eliminates Kafka's operational complexity while maintaining API compatibility. Written in C++ instead of Java, it achieves 10x better performance with 6x lower P99 latency.
Best use case: Best suited for low-latency, high-throughput streaming in financial services, fraud detection, or IoT. Ideal for teams needing Kafka compatibility without operational overhead
Key Features:
Want an easier way to connect your data across platforms? Explore our blog on top tools and solutions for modern data integration. It's your go-to guide for bringing all your data together.
Kafka Connect processes millions of records per second across 100+ connector types, serving as the integration layer between Kafka and external systems with exactly-once delivery guarantees.
Best use case: Organizations needing reliable, high-throughput data movement between Kafka clusters and databases, cloud services, or file systems for real-time analytics pipelines.
Key Features:
Strengths vs Limitations
Debezium streams database changes with microsecond-level latency, supporting 8 major databases with exactly-once delivery guarantees and handling 100,000+ transactions per second per connector.
Best use case: Real-time data synchronization between operational databases and analytical systems, event sourcing architectures, and microservices data consistency patterns.
Key Features:
Strengths vs Limitations
Now that we've covered getting data in, let's talk about what happens next: processing all that information into something useful.
Done with data ingestion? Now explore our 2025 guide on Ultimate Guide on Data Migration Tools, Resources, and Strategy to build smarter and more efficient pipelines.
Once you have data flowing in, you need to transform it, clean it, and prepare it for analysis. This is where the real magic happens, and choosing the right processing tools can make or break your data pipeline's performance.
Here are key tools that handle data transformation at scale with speed and precision.
Apache Spark's unified engine handles 100TB+ datasets across batch and streaming with catalyst optimizer achieving 10x performance gains through code generation and columnar processing.
Best use case: Large-scale ETL workloads, real-time analytics, and iterative machine learning pipelines on petabyte-scale data in distributed environments.
Key Features:
Strengths vs Limitations
Apache Flink processes millions of events per second with sub-second latency through true streaming architecture, supporting complex event processing with stateful computations and exactly-once guarantees.
Best use case: Mission-critical real-time applications requiring low-latency processing like fraud detection, algorithmic trading, IoT analytics, and real-time recommendation systems.
Key Features:
Strengths vs Limitations
dbt transforms terabytes of data using SQL with 300+ built-in functions, supporting incremental models that process only changed data and reducing transformation time by 80%.
Best use case: Analytics teams needing to transform raw data into business-ready datasets using SQL, with software engineering practices like version control, testing, and documentation.
Key Features:
Strengths vs Limitations
With processing covered, let's move on to where all this transformed data needs to live: storage solutions that can handle modern data workloads.
Storage might seem boring, but it's the foundation everything else builds on. Get this wrong, and you'll feel it in performance, costs, and team productivity. Modern storage solutions need to be flexible, scalable, and fast.
Let’s look at top storage tools.
Amazon Redshift handles petabyte-scale analytics with columnar storage and massively parallel processing, serving 500+ concurrent queries with sub-second response times for structured data warehousing.
Best use case: Enterprises with large-scale structured data requiring traditional BI reporting, complex SQL analytics, and integration with existing AWS infrastructure for cost-effective data warehousing.
Key Features:
Strengths vs Limitations
Snowflake's multi-cluster shared data architecture enables automatic scaling to 10,000+ concurrent users while maintaining sub-second query performance through micro-partitioning.
Best use case: Suitable for organizations that need fast, scalable analytics with high user concurrency and cross-cloud data sharing in a fully managed setup.
Key Features:
Strengths vs Limitations
Reduce risk and downtime with secure, efficient database migration services backed by technical expertise and proven frameworks.
Plan Your Migration →
Data lakehouses represent the next evolution in data storage, combining the flexibility of data lakes with the performance of warehouses.
Best use case: Recommended for teams handling both structured and unstructured data who want the flexibility of data lakes along with the performance benefits of warehouses.
Key Features:
Strengths vs Limitations
Storage is just part of the equation. You also need to orchestrate all these moving parts, which brings us to workflow management tools.
Not sure which data engineering tool to choose? Explore essential insights in our complete guide on data pipeline tools.
Data pipelines rarely run in isolation. You need tools that can coordinate different processes, handle dependencies, and keep everything running smoothly. Good orchestration tools are the conductors of your data orchestra.
Now, let’s explore the top data orchestration tools used across the data engineering workflow.
Apache Airflow orchestrates 10,000+ daily tasks across distributed clusters with directed acyclic graphs (DAGs) providing dependency management and automatic retries.
Best use case: Ideal for teams running complex, time-based workflows with interdependent tasks that require visibility, retries, and custom scheduling.
Key Features:
Strengths vs Limitations
Migrate from legacy systems to modern infrastructure with zero disruption, complete security, and full business continuity.
Start Your Migration Plan →
Apache Kafka processes 1 trillion messages daily at LinkedIn scale, serving as the backbone for event-driven architectures with durable storage and horizontal scaling across thousands of nodes.
Best use case: High-throughput event streaming platforms requiring durable message storage, real-time data pipelines, and event-driven microservices architectures with millisecond latency requirements.
Key Features:
Strengths vs Limitations
Having reliable orchestration is crucial, but you also need to ensure your data quality doesn't degrade as it flows through these systems.
Data quality issues can destroy trust in your entire data platform. You need tools that help you catch problems early and maintain confidence in your data products.
The below tools help you detect issues early and maintain reliable, trustworthy data.
Great Expectations validates billions of records daily with 50+ built-in expectations, automatically generating documentation and providing 99.9% data quality coverage through comprehensive testing frameworks.
Best use case: Data teams requiring automated data quality validation, comprehensive documentation, and collaborative workflows to maintain trust in data pipelines and prevent downstream analytical errors.
Key Features:
Strengths vs Limitations
Want to build a strong data foundation? Explore our guide on the steps and Essentials to Prepare Data for AI.
DataOps and MLOps integration enables continuous deployment of data products with automated testing, reducing time-to-production by 70% while maintaining 99.5% system reliability through collaborative workflows.
Best use case: Cross-functional teams developing data products and ML models requiring automated testing, continuous deployment, and collaborative workflows between data engineers, scientists, and ML engineers.
Key Features:
Strengths vs Limitations
Quality and governance set the foundation for trust, but ultimately, you need to present your data in ways that drive business decisions.
All the processing and storage in the world doesn't matter if people can't understand and act on your data. Visualization tools are where data engineering meets business impact.
Let’s now look at the top tools that bring data to life through dashboards and reports:
Tableau processes 10TB+ datasets with in-memory analytics, supporting 1000+ concurrent users through server clustering while providing drag-and-drop visualization creation for business users.
Best use case: Organizations requiring self-service analytics for business users, complex interactive dashboards, and exploratory data analysis with minimal technical training requirements.
Key Features:
Strengths vs Limitations
From cloud readiness to AI integration, we’ll help you design a strategy that’s aligned with your goals — and built to scale.
Talk to a QuartileX Expert →
Looker’s LookML modeling layer ensures consistent business logic across 1000+ reports, supporting embedded analytics with white-label capabilities and API-first architecture for custom integrations.
Best use case: Organizations needing consistent business metrics across all reports, embedded analytics capabilities, and developer-friendly platforms where SQL proficiency exists within the team.
Key Features:
Strengths vs Limitations
These visualization tools help you present your data effectively, but how to choose the best one, let’s explore it next.
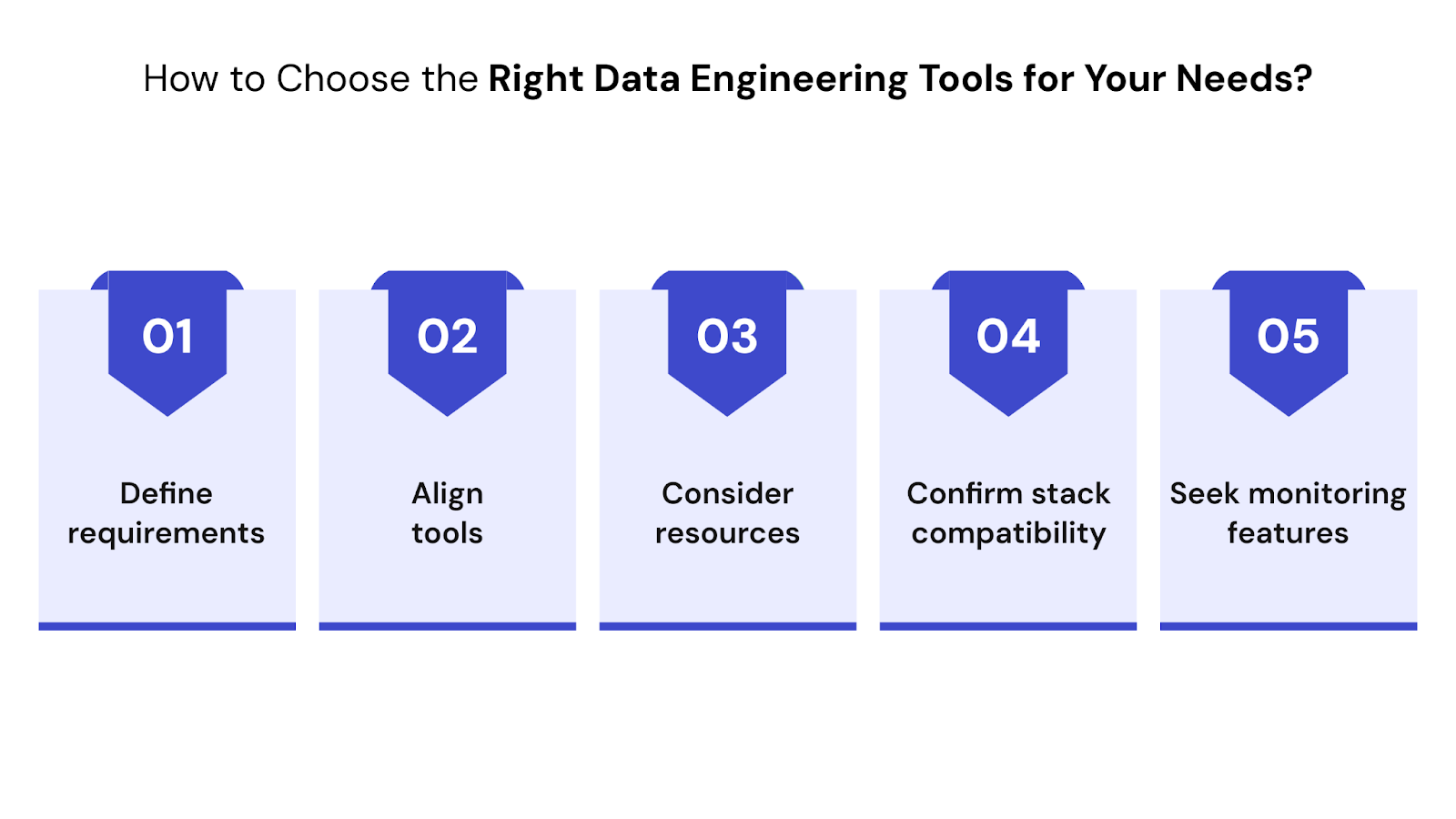
Selecting the right data engineering tools goes beyond features or popularity. The decision depends on how your systems scale, how fast your team can deploy changes, and how well tools fit into your broader tech ecosystem. A mismatch can slow down workflows, increase costs, and impact data reliability.
Before selecting any tool, step back and consider your technical setup, team structure, data goals, and existing tools. This approach helps you avoid rework and build scalable, future-ready pipelines.
Here’s what to focus on:
With the right tools in place, your pipelines are set for success. Now, let’s look at what’s ahead for data engineering in 2025.
[ Image CTA 21]
According to Gartner, 75% of organizations will adopt operational AI and data engineering platforms by 2025 to support real-time decision-making and business automation.
As data volumes continue to grow and architectures become more complex, engineering teams are shifting from reactive pipeline management to proactive, intelligent automation.
Here’s what’s shaping the future of data engineering:
These trends are driving faster delivery cycles, improved data reliability, and tighter alignment between business and engineering goals.
Choosing the right data engineering tools is key to building efficient, high-performing pipelines. From ingestion and transformation to orchestration and reporting, each layer depends on reliable software that fits your technical requirements.
This guide walked you through essential tools for 2025. Whether you're handling batch reports or real-time analytics, the right stack ensures smooth operations, faster data access, and better outcomes for your business.
If your team is facing integration gaps, slow processing, or unclear workflows, QuartileX can help. We offer tool-agnostic solutions built around your needs, combining proven platforms with hands-on support.
Data Engineering with QuartileX
At QuartileX, we help businesses streamline their data workflows using the right engineering tools at every layer of the pipeline.
Here’s how we support your data engineering efforts:
QuartileX works with some of the most reliable data engineering tools to simplify infrastructure and improve system performance. From real-time processing with Spark to flexible warehousing with Snowflake, our team helps you select and implement tools that align with your data goals
Ready to strengthen your data infrastructure? Connect with the QuartileX data engineering team to build pipelines that work at scale and adapt to what’s next.
[ Image CTA: 23]
Q: What’s the difference between data engineering and data science tools?
Data engineering tools build and manage pipelines to collect, transform, and store data. Data science tools focus on analyzing that data. Spark and Airflow support engineering tasks, while scikit-learn and TensorFlow are used for modeling and analysis.
Q: Should I choose open-source or managed data engineering tools?
Open-source tools like Spark and Kafka offer flexibility but need setup and maintenance. Managed tools like Snowflake or Databricks reduce overhead and are better for teams without deep engineering support.
Q: Can I use more than one data engineering tool in a pipeline?
Yes, modern pipelines often use multiple tools together. For example, Kafka for ingestion, Spark for processing, and Airflow for orchestration. Just ensure compatibility and proper monitoring.
Q: What types of processing do these tools support?
They support batch (Spark, Hadoop), real-time (Flink, Kafka), ETL/ELT (dbt), orchestration (Airflow), and quality checks (Great Expectations). Some tools specialize, while others like Databricks handle multiple types.
Q: Are batch and real-time tools interchangeable?
No. Batch tools work in scheduled runs, suited for reports. Real-time tools handle continuous data with low latency, ideal for fraud detection or IoT. Choose based on speed needs and use case.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


