


As organizations scale, data becomes increasingly fragmented, spread across CRMs, APIs, mobile apps, IoT devices, and third-party platforms. The result? Data silos, inconsistent reporting, and missed opportunities.
Data ingestion addresses this challenge by enabling businesses to systematically collect, prepare, and unify data from multiple sources into a centralized, analytics-ready system. Whether you’re dealing with customer data ingestion, building real-time applications, or integrating legacy systems, having a clear data ingestion strategy is essential.
In this guide, we cover what data ingestion means (and what it’s not), real-world examples, key ingestion types, step-by-step workflows, common challenges, proven techniques, and emerging trends shaping the future of data ingestion in big data.
TL;DR (Key Takeaways):
Data ingestion refers to the process of collecting, importing, and transporting data from various sources into a central destination, such as a data lake, data warehouse, or real-time analytics platform.
This process is the first step in a larger data pipeline, making sure data is accessible, usable, and ready for downstream use. Sources can include:
What is the purpose of data ingestion? It enables businesses to unify fragmented data into a single source of truth, which is essential for advanced analytics, reporting, and AI applications.
Optimize your data infrastructure with modern pipelines and architecture that enable faster analytics and smarter decisions at scale.
Future-Proof Your Data Stack →
Although sometimes used interchangeably, data ingestion is not the same as ETL (Extract, Transform, Load). Ingestion focuses primarily on the movement and collection of data, while ETL includes additional transformation steps for structuring and cleaning data.
A well-structured ingestion pipeline unlocks key benefits across the business:
Today, with big data ingestion playing a critical role in AI, cloud computing, and predictive analytics, businesses can no longer afford unreliable or delayed ingestion systems.
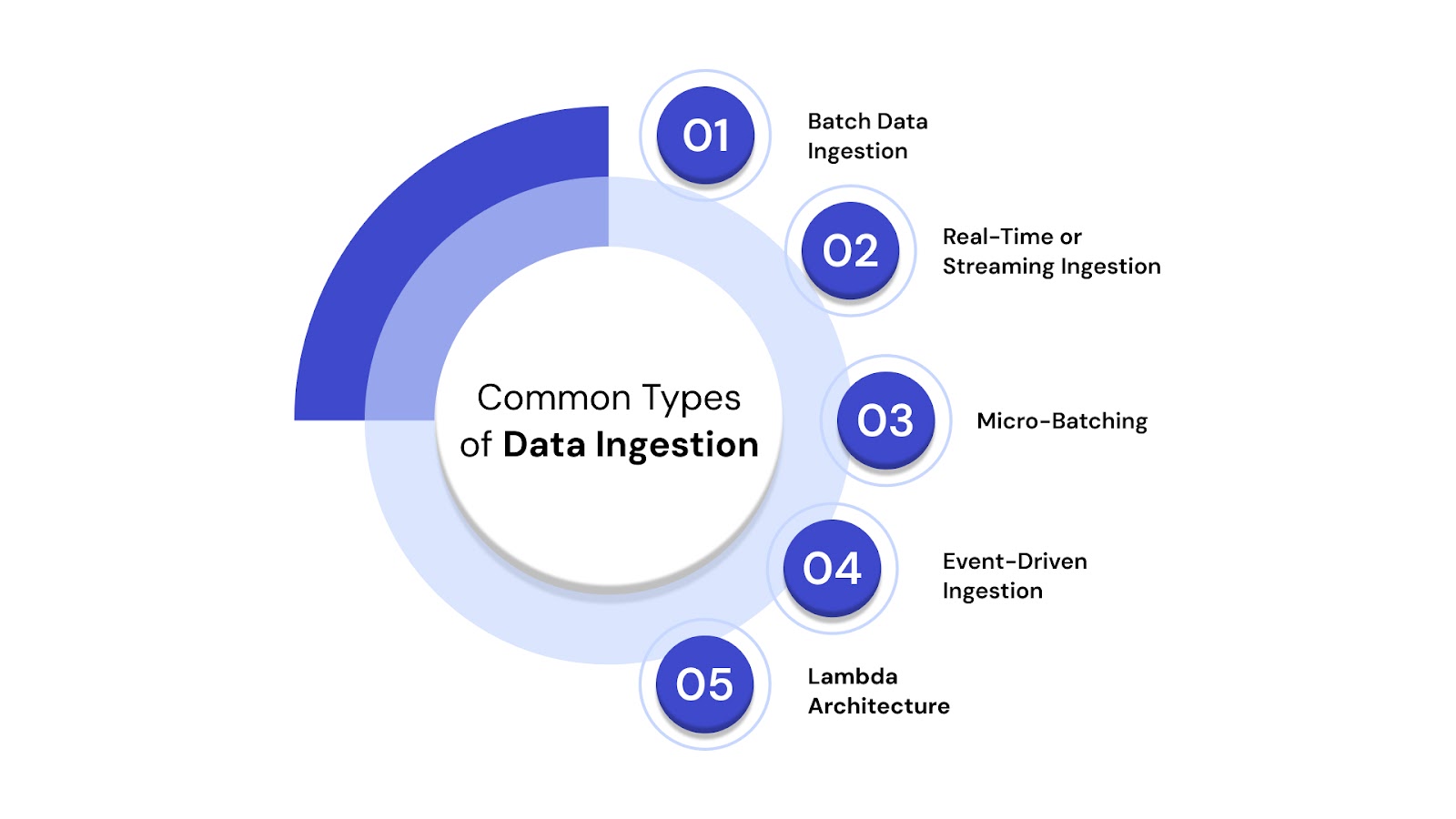
The data ingestion method you choose depends on your data velocity, volume, use cases, and infrastructure. Below are the most common types of ingestion:
Data is collected and transferred at scheduled intervals (hourly, daily, weekly). Ideal for scenarios where real-time insights are not required.
Example: Uploading daily website logs into a data warehouse every night.
Captures and moves data instantly as it's generated. Used in latency-sensitive applications like fraud detection, IoT monitoring, or live personalization.
Example: A financial firm ingests live transaction data to flag anomalies in real time.
A hybrid model where data is ingested in small batches at high frequency, balancing speed and resource efficiency.
Triggered by specific events (e.g., new file uploaded, sensor change detected). Common in IoT platforms and customer behavior tracking systems.
Combines batch and real-time pipelines, offering flexibility and fault tolerance by processing both historical and streaming data.
Want to explore how this applies in real-world implementations? Here you can read our deep dive into data pipeline architecture
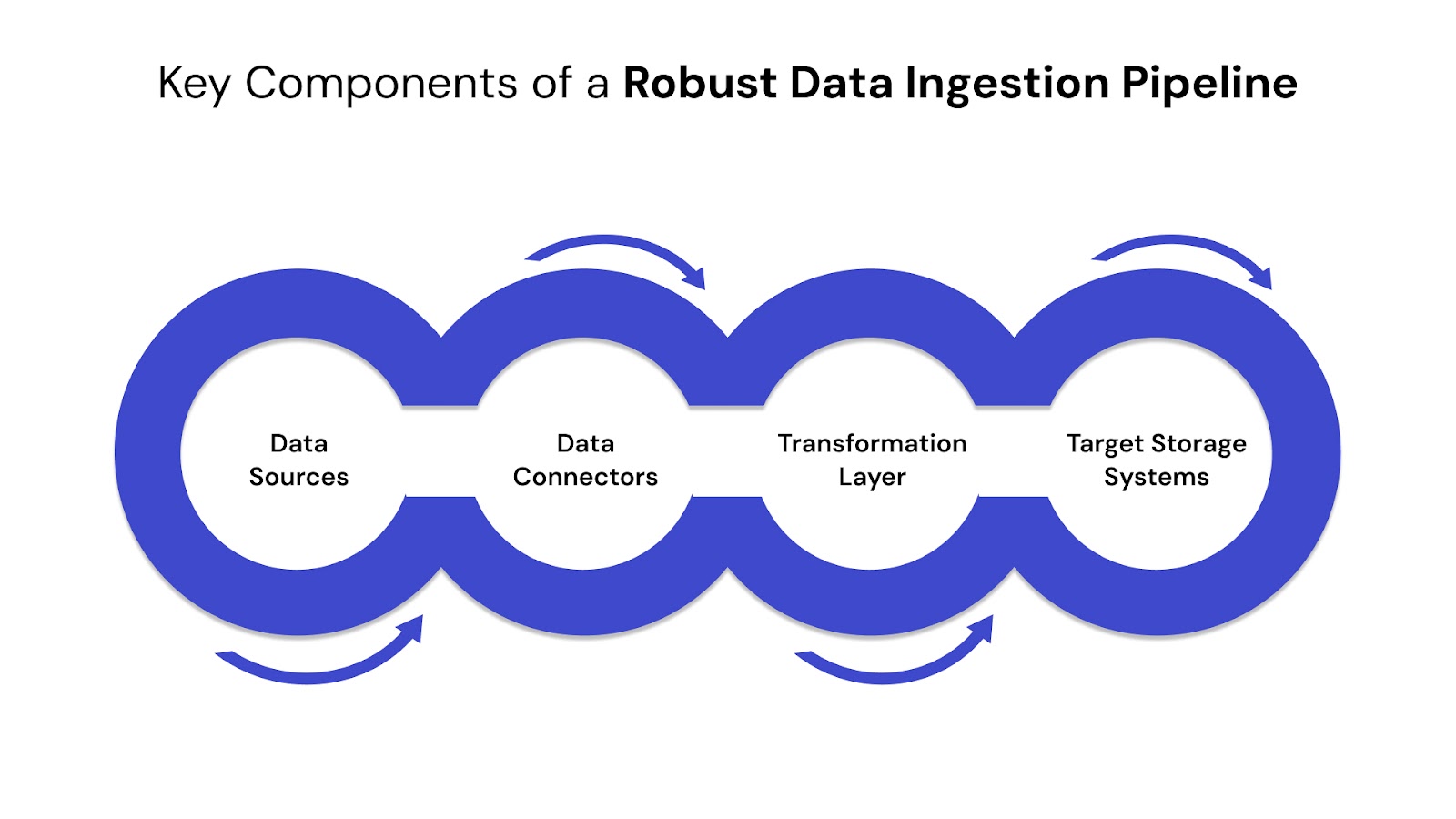
Building a scalable data ingestion system requires multiple moving parts to work in harmony. Below are the essential components that power successful ingestion data engineering systems:
These are the origins of raw data, such as CRM systems, transactional databases, web apps, IoT devices, APIs, or even flat files. They can be:
Connectors (also called agents or integrations) facilitate connectivity between the source and target systems. They enable smooth extraction from APIs, cloud platforms, file systems, or data streams.
Before ingestion, raw data often needs to be cleaned, enriched, or standardized. Transformation handles:
This can happen in an ETL or ELT flow, depending on your architecture.
Transformed data is loaded into repositories like:
At QuartileX, we build secure, scalable ingestion workflows that integrate seamlessly with your target systems. Learn more about our data engineering services and how we ensure high-performance pipelines.
Choosing the right ingestion technique depends on your data architecture, velocity needs, and system complexity. Below are the most popular methods:
The traditional batch-oriented process. Data is extracted from sources, cleaned/transformed, and loaded into a target system. Ideal for structured, historical data.
Ingests data as-is, then applies transformations within the destination system — suitable for cloud-native architectures with scalable compute.
Creates a unified, virtual layer across disparate data sources. Reduces physical data movement and is used when real-time access is needed without full ingestion.
Triggers data ingestion based on real-world events. Often implemented using technologies like Apache Kafka or AWS Lambda — perfect for IoT, clickstream data, and fraud detection.
Modern tools like Fivetran, Hevo, Stitch, and Airbyte automate much of the ingestion process, offering pre-built connectors and real-time sync capabilities. These support data ingestion automation and free up engineering resources.
At QuartileX, we help organizations choose and implement the right ingestion frameworks based on their goals, toolsets, and compliance needs.
Also read - Data Ingestion Framework: Key Components and Process Flows
Even with the right tools, data ingestion in big data environments can be complex. Common challenges include:
Diverse data sources mean different schemas, naming conventions, and data types, causing friction during ingestion.
When source data structures evolve without notice, ingestion pipelines may break unless proactively monitored.
Real-time ingestion systems must process large data volumes at low latency, which can strain infrastructure.
Ingesting customer data or sensitive information brings risk. Encryption, access controls, and compliance (e.g., GDPR, HIPAA) must be enforced at every stage.
Lack of visibility into ingestion workflows can lead to unnoticed failures or silent data loss.
Read our blog on Minimising Data Loss During Database Migration
To build ingestion pipelines that are secure, scalable, and reliable, follow these proven best practices:
Use ingestion tools or event-driven architectures to minimize manual intervention and human error.
Introduce quality gates and circuit breakers that pause ingestion when data fails validation, preventing bad data from polluting your systems.
Avoid directly querying ingestion pipelines for analytics. Use buffer zones or data lakes to separate processing workloads.
Build high-performance pipelines that keep your data flowing reliably — from ingestion to insight.
Build with Data Engineering →
Track every stage of the pipeline, from source connectivity to load completion, with centralized logging and alerts.
Use distributed processing, message queues, or micro-batching to improve ingestion speeds for large datasets.
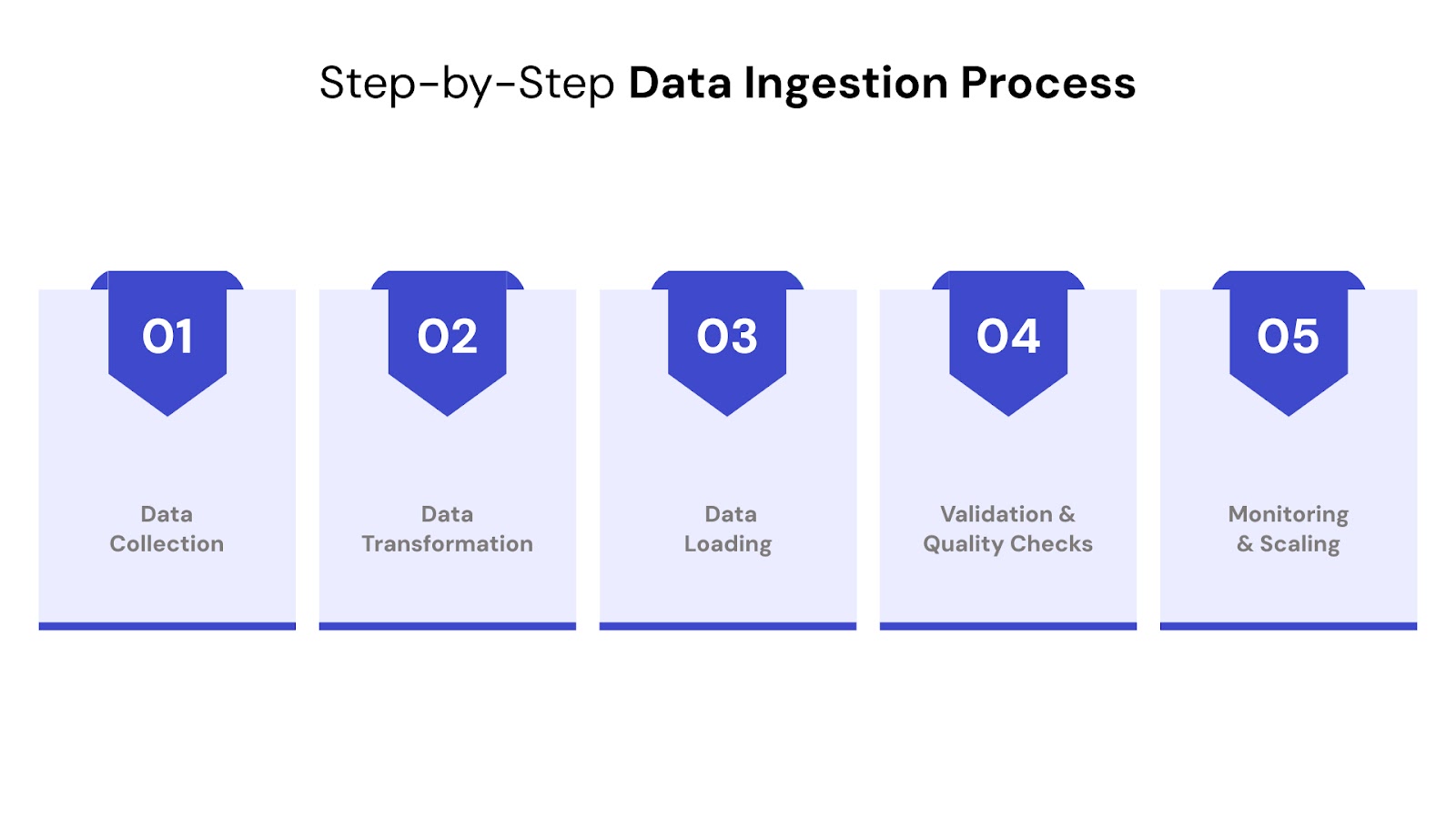
Whether you're handling big data ingestion, machine learning pipelines, or customer analytics workflows, the core process follows a structured path. Here's how a typical ingestion system operates:
Identify and extract data from structured (e.g., SQL, CSV), semi-structured (e.g., JSON, XML), and unstructured sources (e.g., emails, audio, social posts). This could also include data from SaaS applications, sensors, or APIs.
Clean, enrich, and normalize data to align with the required schema. This stage is essential to remove duplicates, fix formatting errors, and apply business logic.
The processed data is loaded into target systems — typically a data warehouse, data lake, or operational store. The choice depends on downstream use cases like real-time reporting, BI, or AI model training.
Data is verified against schema requirements and quality rules. Errors are logged, flagged, or rerouted for manual review, ensuring data ingestion quality and pipeline integrity.
After the initial setup, the ingestion system must be monitored for performance, drift, and bottlenecks. Automation tools and observability platforms help with self-healing, real-time alerts, and adaptive scaling.
Need help setting this up? QuartileX specializes in building custom ingestion pipelines designed for resilience, scalability, and data accuracy. Explore our data engineering capabilities here.
Understanding how leading businesses use ingestion systems can help illustrate the value it brings:
A retail brand uses real-time ingestion to track clickstreams, cart abandonment, and purchase data across its web and mobile platforms. This fuels dynamic pricing, inventory management, and personalized recommendations.
Banks ingest live data from payment systems, trading platforms, and fraud detection tools. Using event-driven ingestion, they detect anomalies and trigger alerts within seconds.
Hospitals use data ingestion in machine learning models by collecting vitals from connected devices (e.g., heart monitors). Data is streamed, transformed, and used for early diagnosis alerts.
B2B platforms collect telemetry and usage data through APIs and logs. They ingest this data into a data lakehouse architecture, enabling real-time dashboards for product and support teams.
For more on how intelligent ingestion supports broader governance and analytics goals, read our blog on Data Quality in Governance.
As businesses move toward faster, smarter data ecosystems, data ingestion technologies are evolving rapidly. Here are key trends to watch:
With more workloads moving to the cloud, ingestion is becoming more elastic and scalable. Tools like AWS Glue, Google Dataflow, and Azure Synapse support pay-as-you-go ingestion frameworks.
Data ingestion in AI will go beyond traditional rules. Machine learning models will automate anomaly detection, schema mapping, and even transformation logic, improving efficiency and reducing human error.
Ingestion pipelines are starting to handle diverse formats — from text and images to video and sensor data — in a unified architecture. This supports advanced use cases like generative AI, conversational intelligence, and predictive maintenance.
For use cases like autonomous vehicles or smart manufacturing, ingestion systems are being built at the edge — closer to the data source — reducing latency and enabling faster decision-making.
At QuartileX, we understand that data ingestion isn’t just a backend process — it’s the backbone of your analytics, reporting, and AI initiatives. Here’s how we help:
To learn more, book a free consultation with our engineering team and let’s talk about how to improve your data ingestion system for long-term success.
Whether you’re building a new analytics platform, launching ML initiatives, or migrating to the cloud, effective data ingestion is non-negotiable. Without it, data remains siloed, inconsistent, or unusable.
By understanding the purpose of data ingestion, selecting the right architecture, and implementing best practices, businesses can ensure their pipelines are not only efficient but also future-proof.
Need help building a high-performance data ingestion strategy?
Let QuartileX handle the complexity while you focus on making data-driven decisions.
Streamline your data pipelines and architecture with scalable, reliable engineering solutions designed for modern analytics.
See Data Engineering Services →
Data ingestion refers to the process of collecting, transporting, and loading data from various sources into a centralized system like a data warehouse or data lake. It’s a critical part of modern data engineering as it enables unified access to structured and unstructured data for analytics, machine learning, and decision-making.
The primary data ingestion types include:
While data ingestion focuses on moving data from multiple sources to a central destination, ETL (Extract, Transform, Load) involves not just ingesting, but also transforming and cleaning the data before loading it. ETL is a specific technique within the broader data ingestion process.
Handling large data ingestion in big data environments involves scalable tools like Apache Kafka, Apache NiFi, or cloud-native services (e.g., AWS Kinesis, Google Dataflow). Strategies like micro-batching, parallel processing, and automation help manage volume, velocity, and variety efficiently.
Challenges include:
Popular tools for automated data ingestion include:
You can explore a complete list of modern tools in this blog on data ingestion tools to choose the right one for your use case.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


