


Did you know? Around 80–90% of newly generated enterprise data is unstructured, making effective management of data ingestion tools and data ingestion software more crucial than ever.
Data ingestion is a priority as you shift toward cloud-native and real-time applications. Massive volumes from IoT devices, APIs, and streaming demand reliable data ingestion tools to prevent bottlenecks and latency.
This guide shows you how to evaluate data ingestion software that aligns with current trends. You'll explore 15 top tools, practical use cases, and decision criteria to improve pipeline speed and scalability.
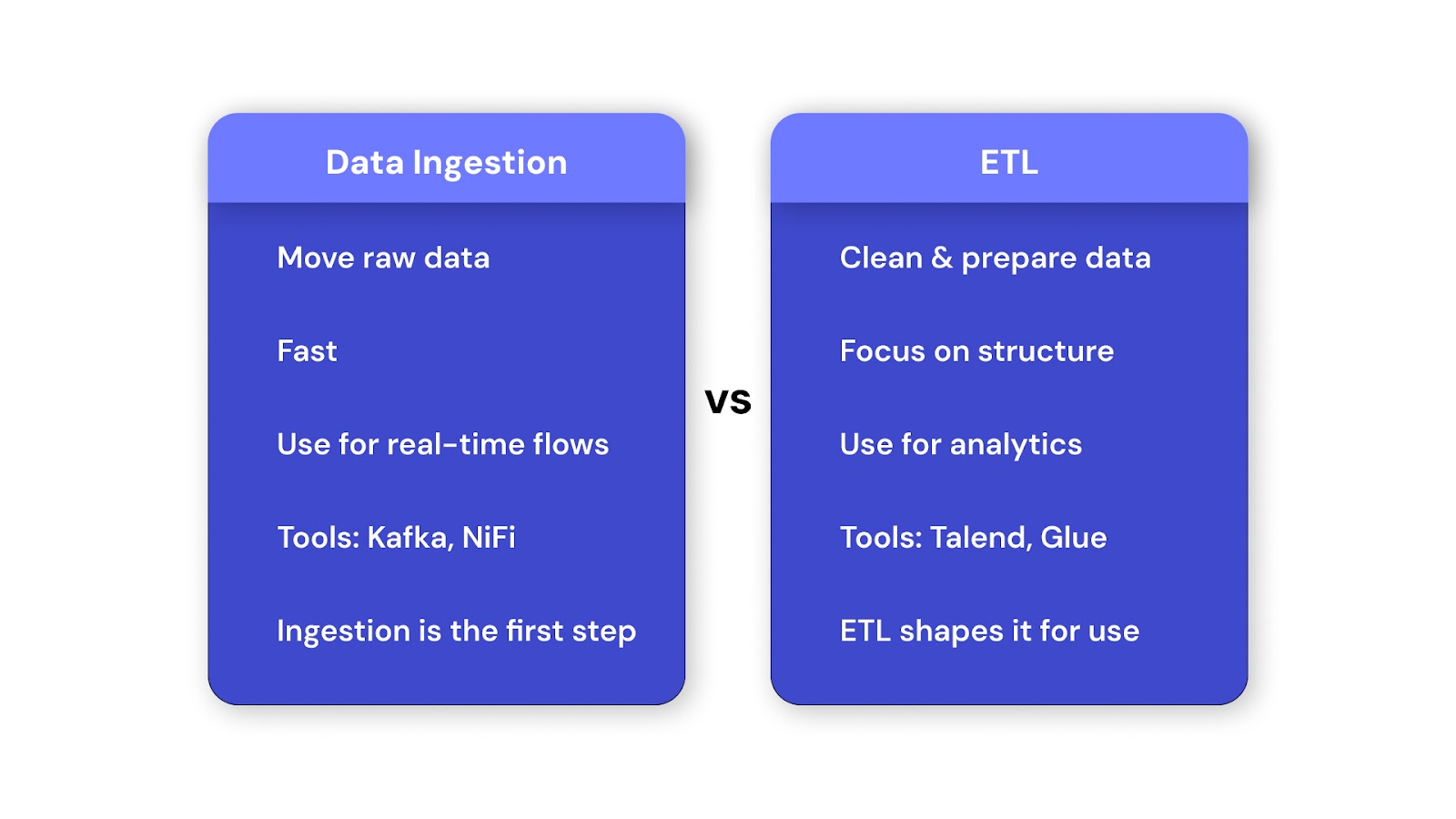
Data ingestion tools move raw data from multiple sources into storage or processing systems, handling both structured and unstructured formats. They enable fast, reliable data flow into lakes, warehouses, or streaming platforms, forming the first step in modern data pipelines.
Unlike ETL, which transforms and cleans data before loading, ingestion tools prioritize speed and transfer of raw data. In short, ingestion moves data quickly; ETL prepares it for analysis.
For a deeper understanding of the process of data ingestion, explore our guide on data ingestion.
Let’s now explore two primary approaches used by data ingestion tools: batch and streaming; and how they differ in function and use case.
Data ingestion software sits at the entry point of the modern data stack, pulling data from diverse sources like databases, APIs, logs, and IoT devices. It feeds this raw or semi-processed data into storage systems such as data lakes, warehouses, or real-time engines. This layer ensures consistent, automated data flow before any transformation, analysis, or machine learning takes place.
We’ll assess your current infrastructure and help you map a smarter, more cost-efficient path forward.
Request a Readiness Assessment →
The global data integration market is projected to reach $33.24 billion by 2030, growing at a 13.6% CAGR from 2025. This growth is driven by cloud adoption, real-time analytics, and the rise of API-first systems. Businesses now collect data from hundreds of sources, requiring tools that ensure speed, reliability, and scalability. The tools listed below are shaping how organizations manage data pipelines in 2025.
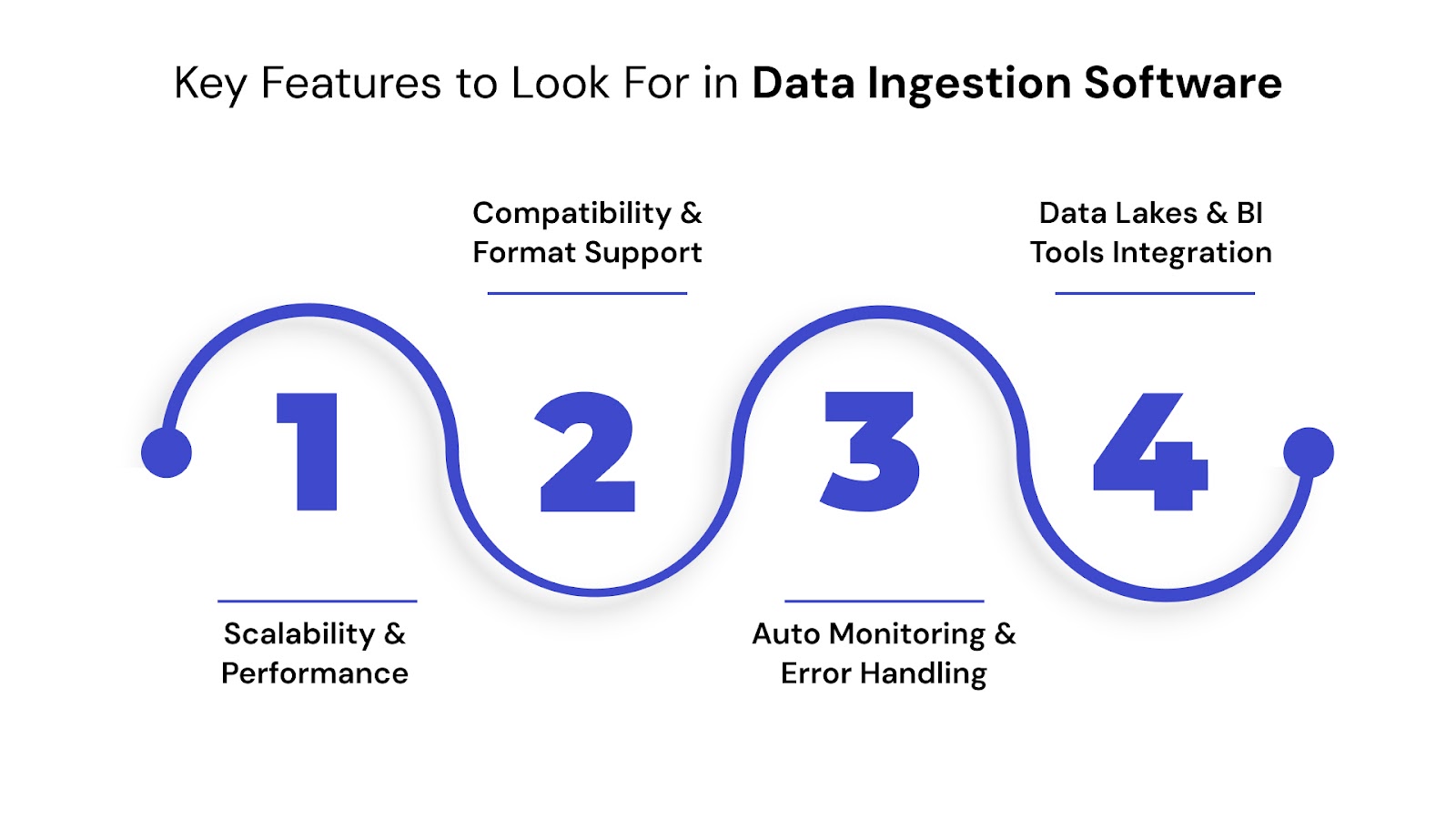
Now, let’s look at the key features that define great data ingestion tools and data ingestion software.
Key Features to Look For in Data Ingestion Software
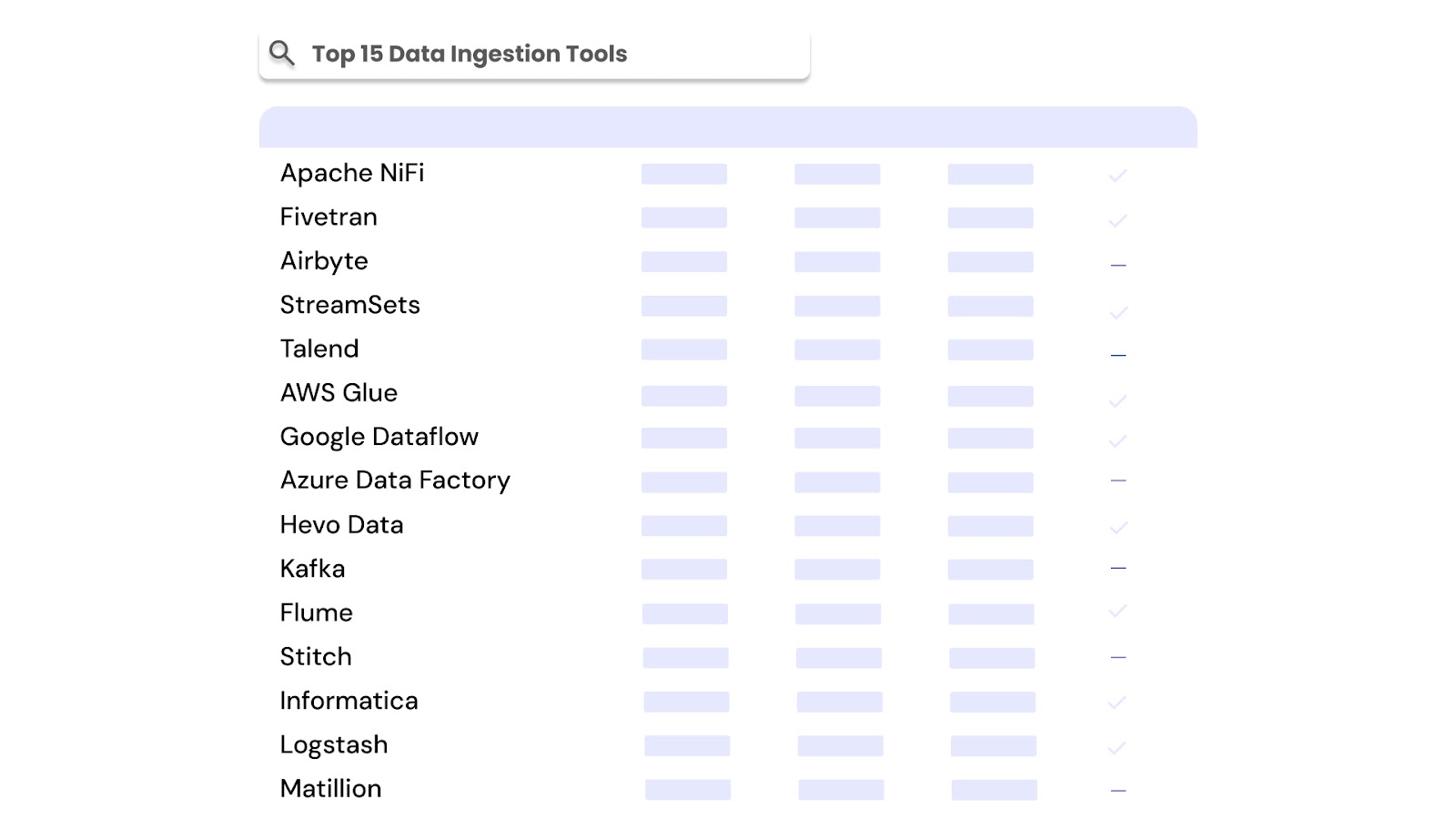
Now, let’s take a look at each of the top data ingestion tools one by one.
Apache NiFi is a robust, open-source data ingestion tool designed for automating the flow of data between systems. It supports both batch and streaming ingestion, with a visual interface to build, monitor, and manage real-time pipelines. As one of the leading data ingestion tools in Hadoop ecosystems, it’s widely used for big data ingestion from distributed sources.
Best use case
Ideal for organizations that need secure, real-time data ingestion solutions from edge devices, APIs, databases, or cloud services into Hadoop or data lakes.
Strengths vs Limitations
Apache NiFi is completely free and open source. However, data ingestion companies like Cloudera offer enterprise-grade support, monitoring, and scaling features built on top of NiFi.
Looking to simplify how your data flows across systems? Check out our blog on the top tools and solutions for modern data integration: it’s your complete guide to unifying your data landscape.
Fivetran is a cloud-native, fully managed data ingestion software built to automate data integration for analytics and reporting. It continuously syncs data from over 300 sources, including SaaS platforms, databases, and file systems, into destinations like Snowflake, BigQuery, Redshift, and Databricks. As a leading data ingestion platform, it eliminates the need for custom scripts, offering zero-maintenance data ingestion solutions with built-in schema handling.
Best use case
Best suited for businesses that need fast, reliable, and low-maintenance ingestion from cloud services and databases into modern data warehouses.
Strengths vs Limitations
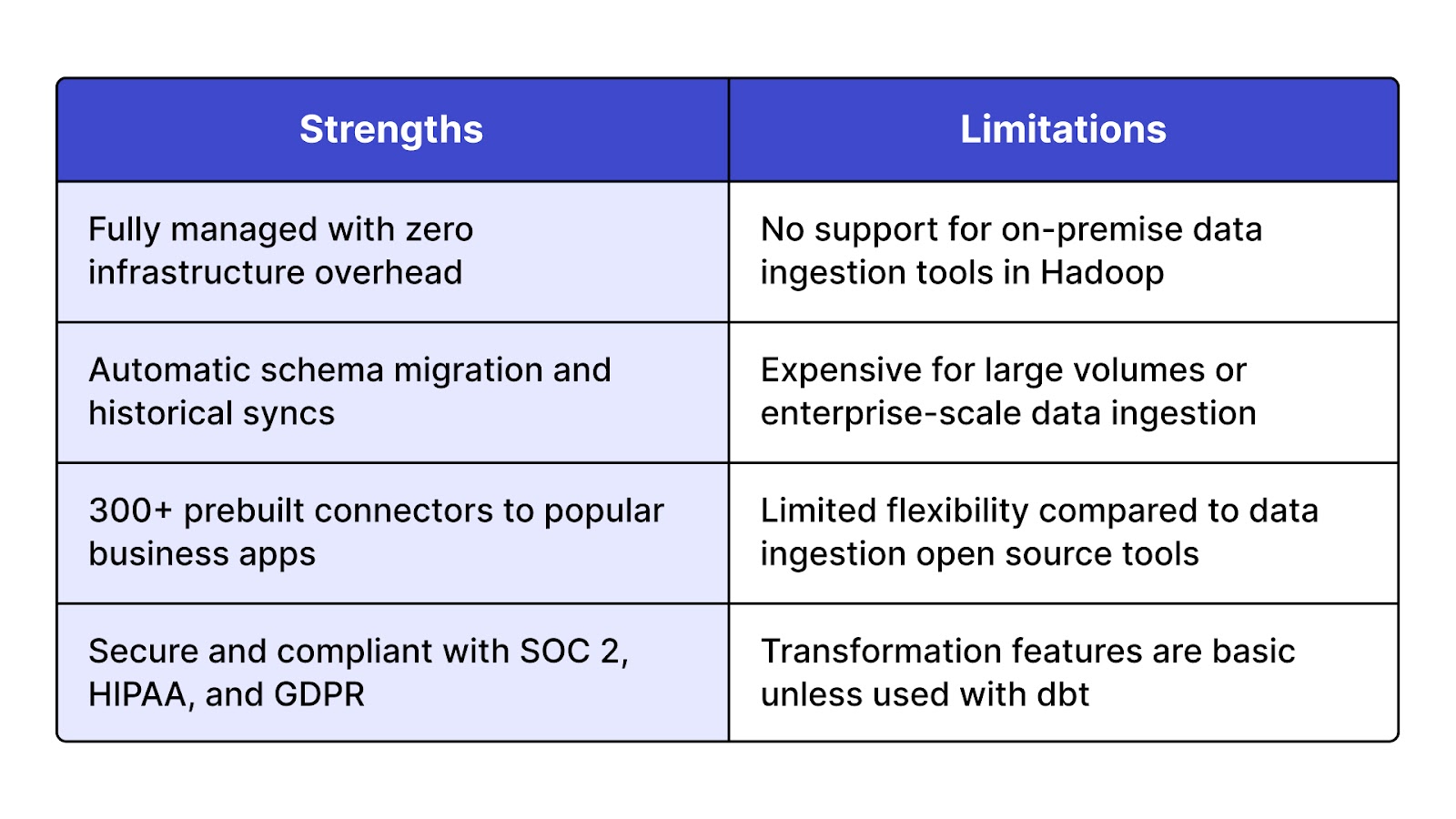
Fivetran offers a 14-day free trial. Pricing is usage-based and scales with the volume of data processed, making it better suited for mid-to-large scale operations. It's commonly adopted by data ingestion companies that prioritize ease of use and time-to-value.
Confused which data pipeline tool to pick? Discover crucial insights from our guide on data pipeline tools!
Airbyte is a modern, open-source data ingestion tool that enables teams to build, deploy, and manage custom data connectors quickly. It supports batch ingestion and is designed to sync data from hundreds of sources into major destinations like Snowflake, BigQuery, Redshift, and data lakes. As one of the fastest-growing data ingestion tools open source, it helps engineering teams adopt flexible, modular data ingestion solutions without being tied to vendor limitations.
Best use case
Ideal for startups and data teams that need to build or customize connectors or prefer self-hosted data ingestion software with community-driven updates.
Strengths vs Limitations
Airbyte offers a free, open-source version suitable for self-hosted deployments. It also provides a paid Cloud version with managed hosting, SLAs, and support. This hybrid approach makes it appealing to both independent developers and scaling data ingestion companies.
StreamSets is an intelligent, enterprise-grade data ingestion platform designed to build and manage resilient, data-rich pipelines across hybrid and multi-cloud environments. It supports both batch and streaming ingestion and provides rich monitoring, schema drift handling, and low-code design. Recognized among the top big data ingestion tools, StreamSets is widely used by data engineering teams for managing high-volume pipelines in real time.
Best use case
StreamSets is ideal for large organizations needing robust, scalable data ingestion solutions across varied systems including data ingestion tools in Hadoop, cloud storage, and data lakes.
Strengths vs Limitations
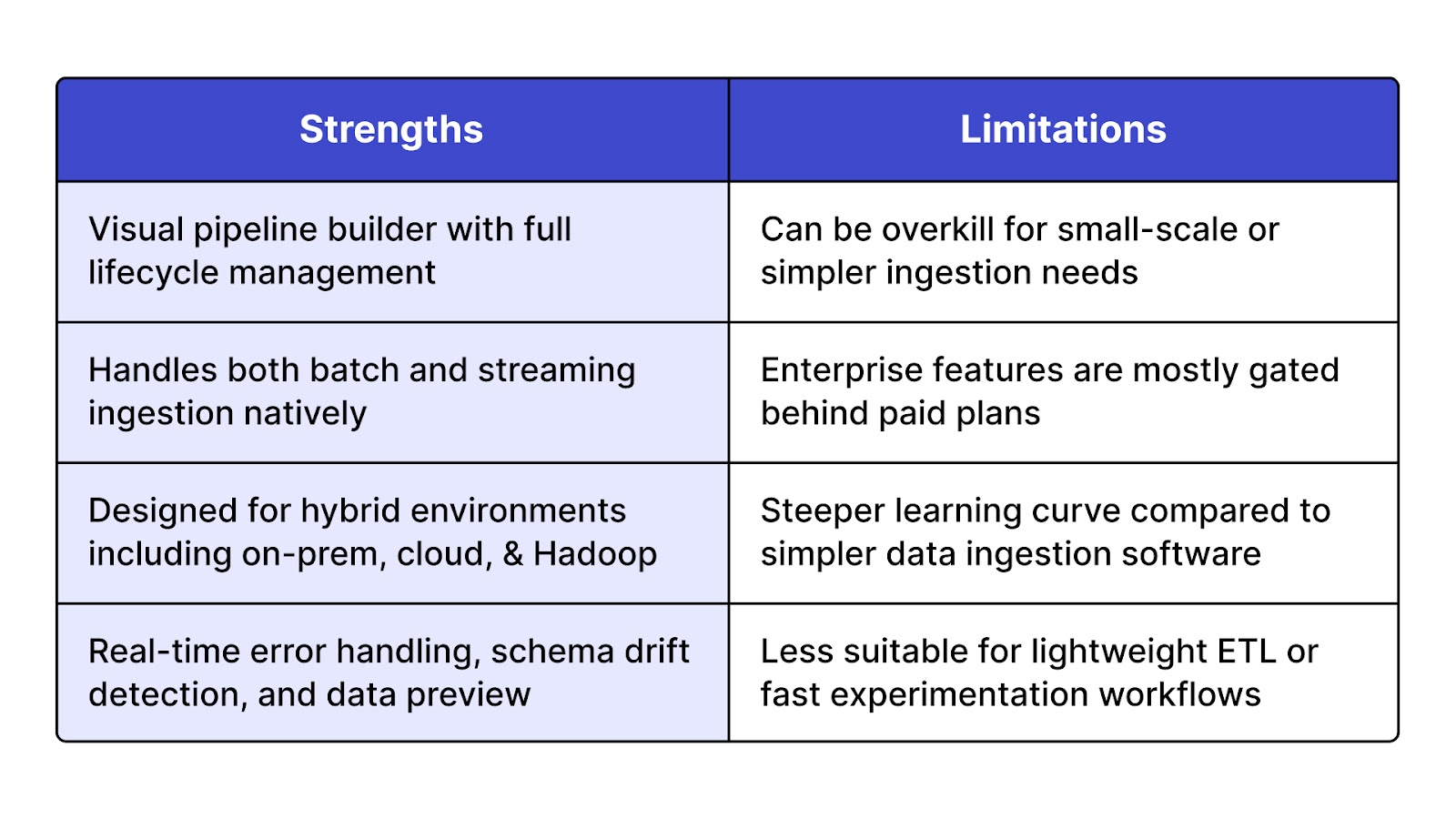
treamSets offers a free version called Data Collector Engine for local development and testing. However, production-grade deployments and advanced features are available only through enterprise licenses, making it better suited for mid to large-scale data ingestion companies.
Migrate from legacy systems to modern infrastructure with zero disruption, complete security, and full business continuity.
Start Your Migration Plan →
Talend is a widely adopted data ingestion tool that combines powerful ETL, ELT, and data integration features in one unified data ingestion platform. It enables users to extract data from various sources, perform transformations, and load it into databases, cloud warehouses, or Hadoop ecosystems. Talend supports both batch and streaming workflows, making it a strong player among enterprise-grade data ingestion solutions.
Best use case
Best for teams that need scalable and secure data ingestion software with built-in data quality, governance, and transformation capabilities—especially in hybrid or big data environments.
Strengths vs Limitations
Talend offers Talend Open Studio, a free and open-source edition that supports basic ETL and data ingestion open source workflows. For advanced automation, monitoring, cloud connectors, and enterprise-grade support, users must opt for Talend Data Fabric, the paid solution.
AWS Glue is a fully managed, serverless data ingestion platform designed to automate the discovery, preparation, and movement of data across AWS services. It supports both batch and near real-time ingestion and is widely used for building ETL and ELT pipelines in cloud environments. As part of AWS’s broader big data ingestion tools offering, Glue integrates deeply with S3, Redshift, RDS, Athena, and more.
Best use case
Ideal for organizations already in the AWS ecosystem that need scalable data ingestion solutions without managing infrastructure. It's especially effective for building automated data lakes and lakehouses.
Strengths vs Limitations
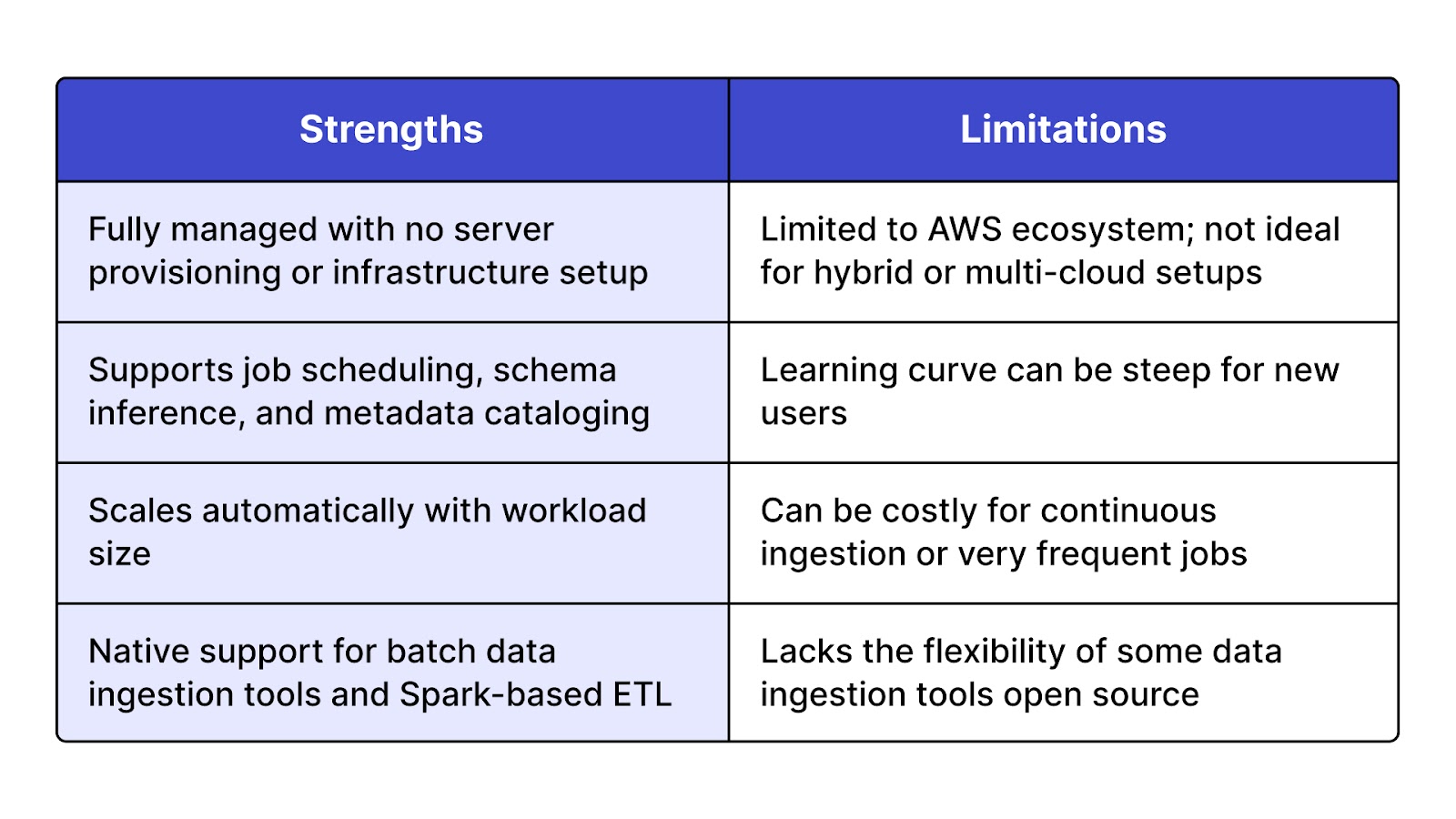
AWS Glue offers a pay-as-you-go pricing model based on data processing units (DPUs). While there’s no traditional “free tier,” users can take advantage of AWS’s Free Tier if they’re new to the platform. It is not open source, but it’s favored by many data ingestion companies for its tight integration with other AWS services and enterprise scalability.
Google Dataflow is a fully managed, unified data ingestion platform for both stream and batch data processing. It’s built on Apache Beam and tightly integrated with other Google Cloud services like BigQuery, Pub/Sub, and Cloud Storage. This data ingestion software is designed for building scalable pipelines that can handle massive volumes of structured and unstructured data with real-time or scheduled processing.
Best use case
Best for companies running on Google Cloud that require powerful, event-driven data ingestion solutions for real-time analytics, fraud detection, and data lake ingestion.
Strengths vs Limitations
Google Dataflow offers a usage-based pricing model with no upfront costs. There's a limited free tier each month for new and lightweight workloads. It's not open source, but its reliance on Apache Beam provides some flexibility in portability and design for developers used to Apache data ingestion models.
For a deeper understanding of establishing this crucial data foundation, explore our guide on Steps and Essentials to Prepare Data for AI.
Azure Data Factory is a cloud-based data ingestion platform offered by Microsoft Azure. It enables users to build and manage ETL and ELT pipelines that move data from on-premises and cloud sources into Azure services such as Synapse, Data Lake, and Blob Storage. As a flexible data ingestion tool, it supports over 100 native connectors and can ingest both structured and unstructured data, making it one of the top choices for data ingestion solutions in enterprise cloud environments.
Best use case
Ideal for companies already using Microsoft Azure that require seamless batch data ingestion tools or hybrid data movement across cloud and on-prem infrastructure.
Strengths vs Limitations
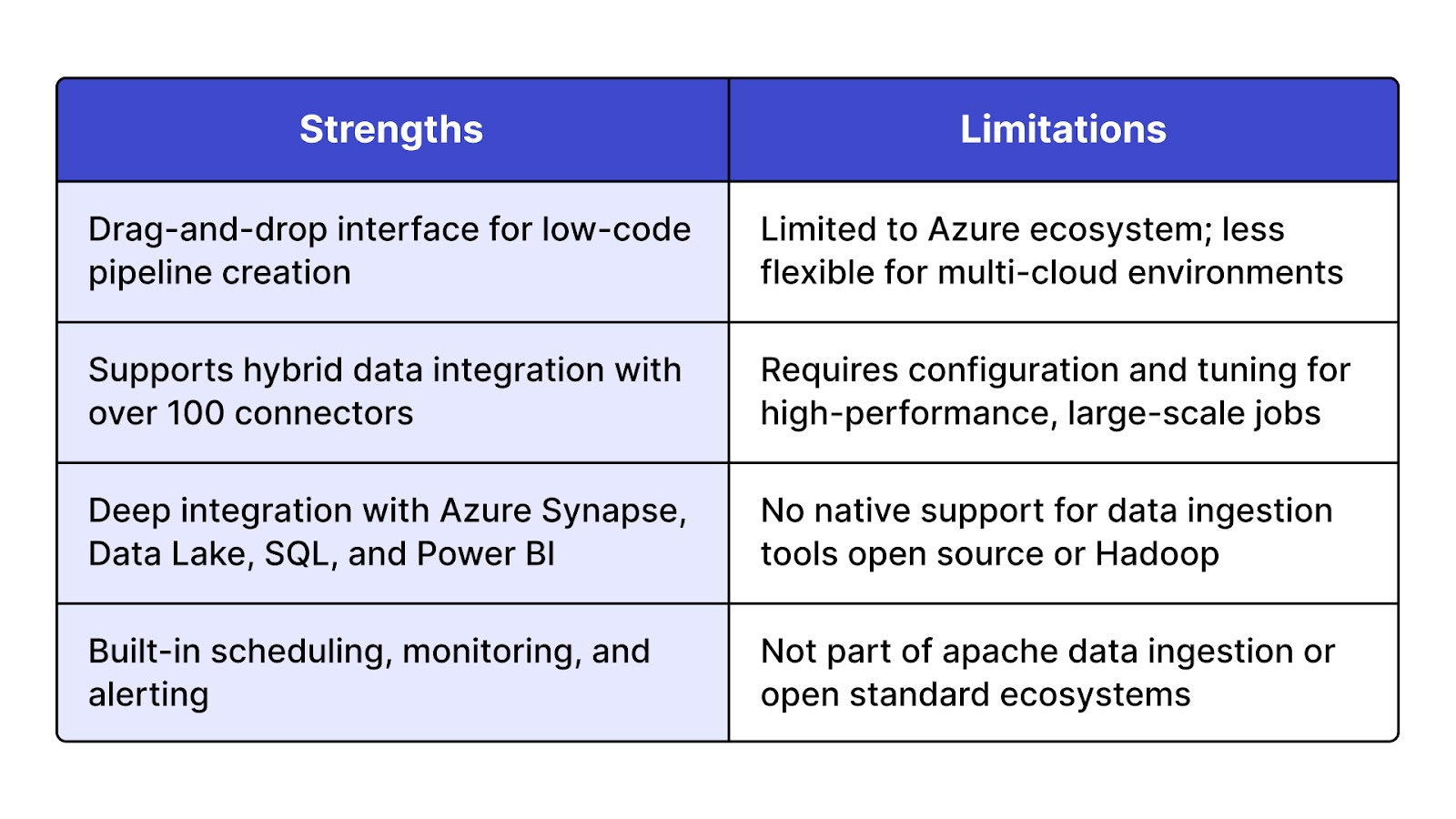
Azure Data Factory offers pay-per-use pricing based on pipeline activity and compute usage. There is no open-source edition, but pricing is flexible enough for both small-scale and enterprise deployments. Many data ingestion companies favor it for its scalability, ease of use, and native Azure integration.
From cloud readiness to AI integration, we’ll help you design a strategy that’s aligned with your goals — and built to scale.
Talk to a QuartileX Expert →
Hevo Data is a no-code, cloud-based data ingestion platform that enables seamless movement of data from 150+ sources into data warehouses such as Snowflake, Redshift, and BigQuery. This fully managed data ingestion software is designed to automate the entire ETL and ELT process, with real-time syncing, zero-maintenance connectors, and built-in data transformation capabilities. It is optimized for fast deployment and ease of use, making it a popular choice for modern analytics teams.
Best use case
Best for fast-growing teams that want real-time data ingestion solutions with minimal setup and no code, especially for marketing, sales, and product analytics workflows.
Strengths vs Limitations
Hevo offers a 14-day free trial with access to its full feature set. Pricing is tiered based on event volume, starting with a Starter Plan suitable for small teams and growing to Enterprise-level packages. While it’s not open source, it’s favored by many new-age data ingestion companies for its ease of use and real-time capabilities.
Apache Kafka is a distributed streaming data ingestion platform developed by the Apache Software Foundation. It allows users to publish, subscribe to, store, and process streams of records in real time. Kafka acts as both a messaging system and a durable log, making it one of the most powerful data ingestion tools open source for handling large-scale, real-time data movement across services, apps, and databases.
Best use case
Best for large organizations and data ingestion companies that require low-latency, high-throughput data ingestion solutions for applications such as log aggregation, event sourcing, fraud detection, and IoT streaming.
Strengths vs Limitations
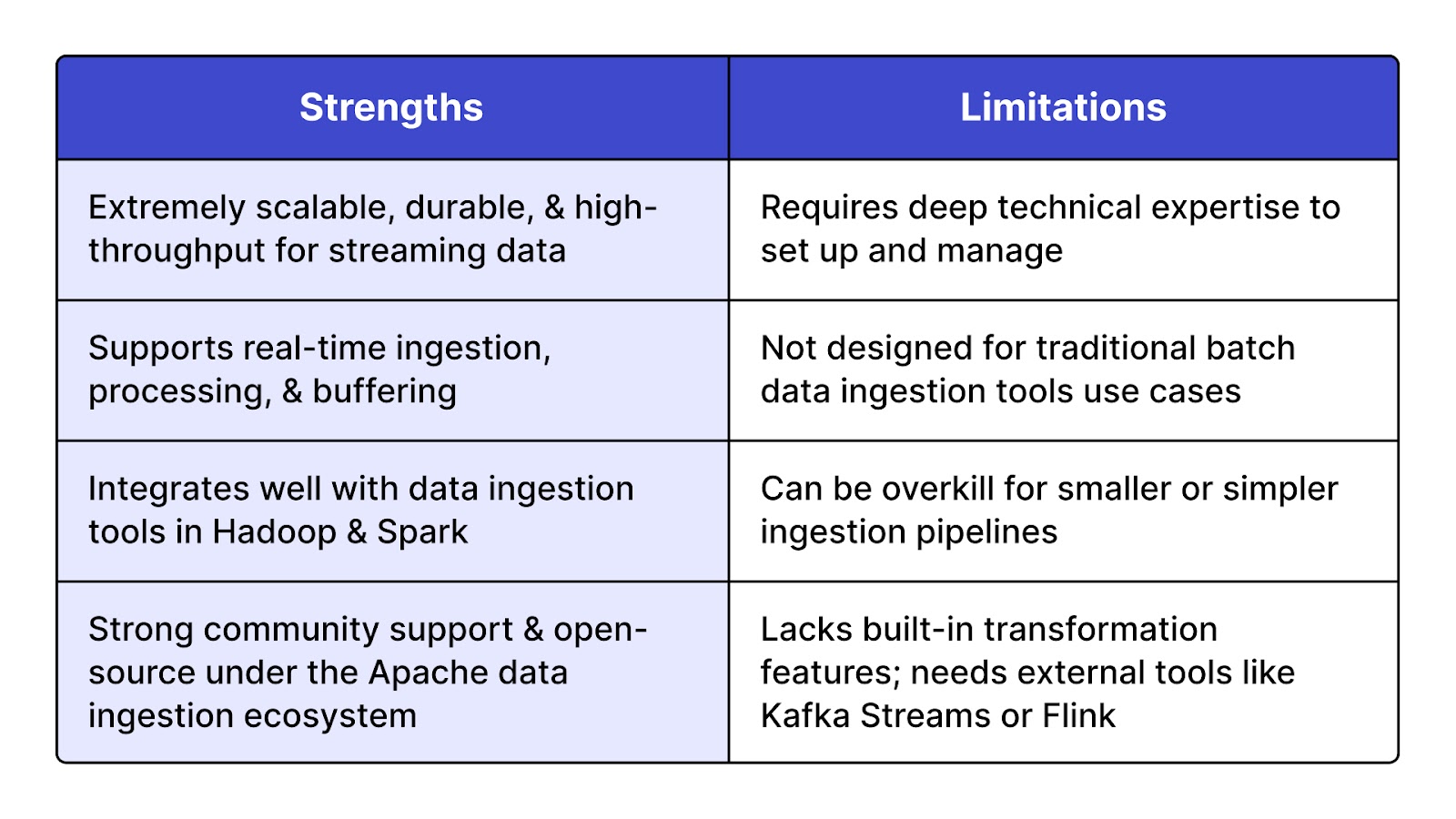
Kafka is completely free and open source, maintained under the Apache 2.0 license. However, commercial versions like Confluent Kafka offer additional enterprise features such as managed services, security enhancements, and UI tools. This makes it suitable for production deployments by large big data ingestion tools users.
Apache Flume is a distributed, reliable, and highly available data ingestion tool designed for efficiently collecting, aggregating, and transporting large volumes of log data. Primarily used within Hadoop-based data ingestion platforms, Flume is optimized to move streaming logs and event data into HDFS and HBase. It is part of the broader Apache data ingestion ecosystem and one of the classic data ingestion tools in Hadoop environments.
Best use case
Best for organizations that need to move high volumes of log or event data from web servers and applications into Hadoop-based storage for analytics.
Strengths vs Limitations
Apache Flume is completely open source and free to use under the Apache License 2.0. Many data ingestion companies use it as part of their big data ingestion tools stack in on-premise Hadoop environments. It does not offer any paid enterprise version but can be supported via third-party services like Cloudera.
Reduce risk and downtime with secure, efficient database migration services backed by technical expertise and proven frameworks.
Plan Your Migration →
Stitch is a cloud-first data ingestion software that enables rapid, no-code data replication from over 140 sources into data warehouses like Snowflake, Redshift, BigQuery, and Azure Synapse. It’s a simple, reliable data ingestion platform focused on ELT (Extract, Load, Transform) and offers automated scheduling, schema handling, and secure pipelines. Stitch is built on top of Singer, an open standard for data extraction, which aligns it loosely with the data ingestion open source community.
Best use case
Best for small to mid-sized data teams that want quick, low-maintenance data ingestion solutions for centralizing SaaS, database, or cloud application data into analytical environments.
Strengths vs Limitations
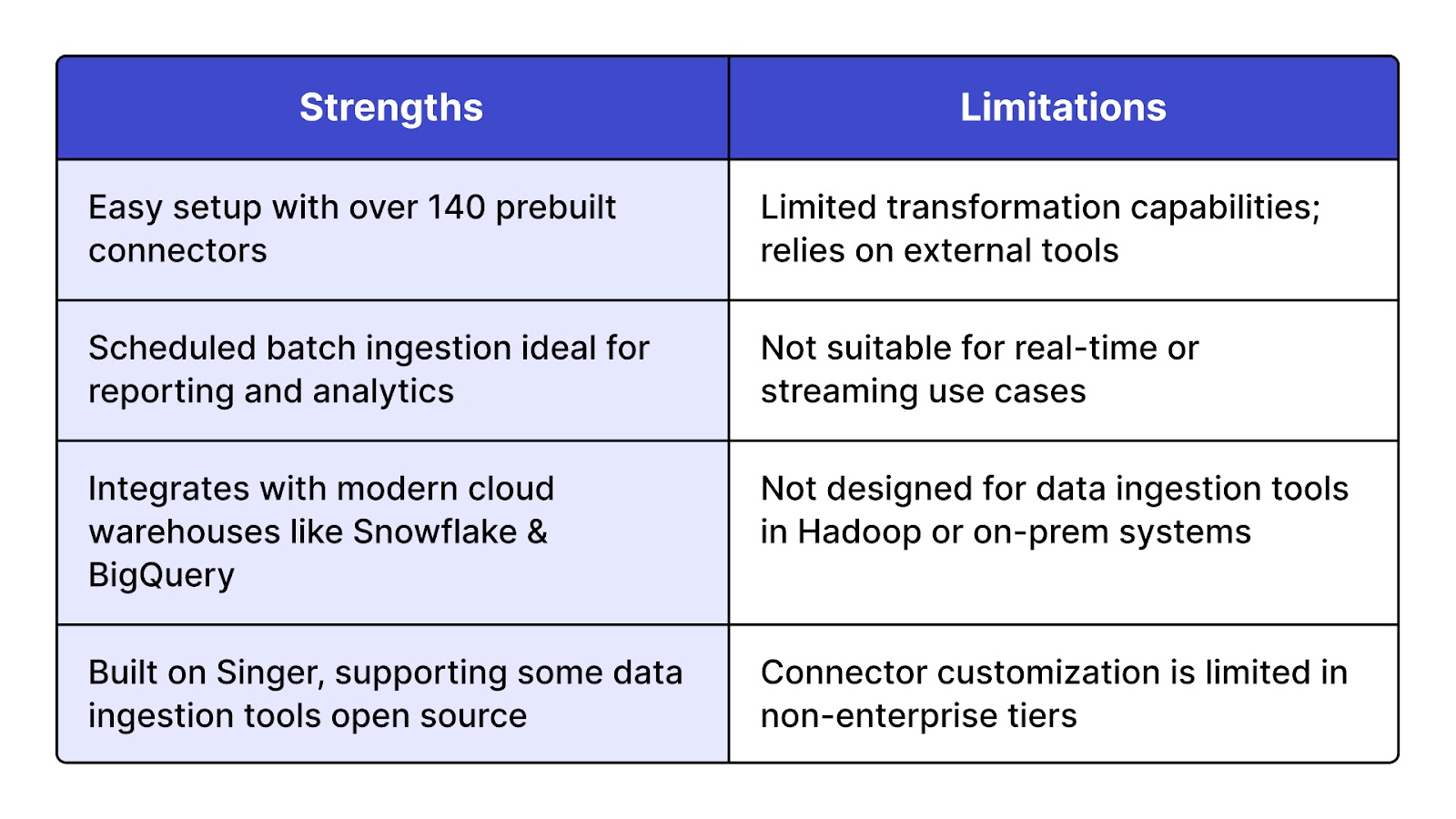
Stitch offers a 14-day free trial, after which pricing is based on row volume and features. It has both Standard and Enterprise tiers, with the latter offering advanced features like API access and priority support. While it’s not part of the apache data ingestion ecosystem, it’s widely used by data ingestion companies that need speed and simplicity.
Informatica is a powerful, enterprise-grade data ingestion platform that supports a broad range of data integration, ETL, and data governance needs. It enables businesses to ingest, cleanse, transform, and deliver data across cloud, on-premises, and hybrid environments. Often used by large data ingestion companies, Informatica supports both real-time and batch data ingestion tools workflows and integrates with major cloud services, databases, and big data ingestion tools like Hadoop and Spark.
Best use case
Best for large enterprises with complex data architectures needing comprehensive data ingestion solutions, strong governance, and integration across multiple ecosystems, including data ingestion tools in Hadoop.
Strengths vs Limitations
Informatica offers free trials of its cloud services and data integration tools, but the full platform is licensed and enterprise-priced. It’s one of the most feature-rich and secure data ingestion software platforms in the market, but also one of the most expensive. Pricing varies based on usage, deployment, and enterprise requirements.
What happens after ingestion? Explore our 2025 Ultimate Guide on Data Migration Tools, Resources, and Strategy: the perfect next step after mastering data ingestion tools for smarter pipelines.
Logstash is a flexible, open-source data ingestion tool that collects, parses, and enriches data from various sources before pushing it into destinations like Elasticsearch, Kafka, or databases. As part of the Elastic Stack (formerly ELK), it excels at processing logs and metrics in real-time. Widely adopted across data ingestion companies, it supports a wide range of inputs, filters, and outputs, making it a strong choice among data ingestion tools open source.
Best use case
Ideal for real-time data ingestion solutions involving logs, metrics, event data, and observability pipelines, especially when used alongside Elasticsearch and Kibana for monitoring and analysis.
Strengths vs Limitations
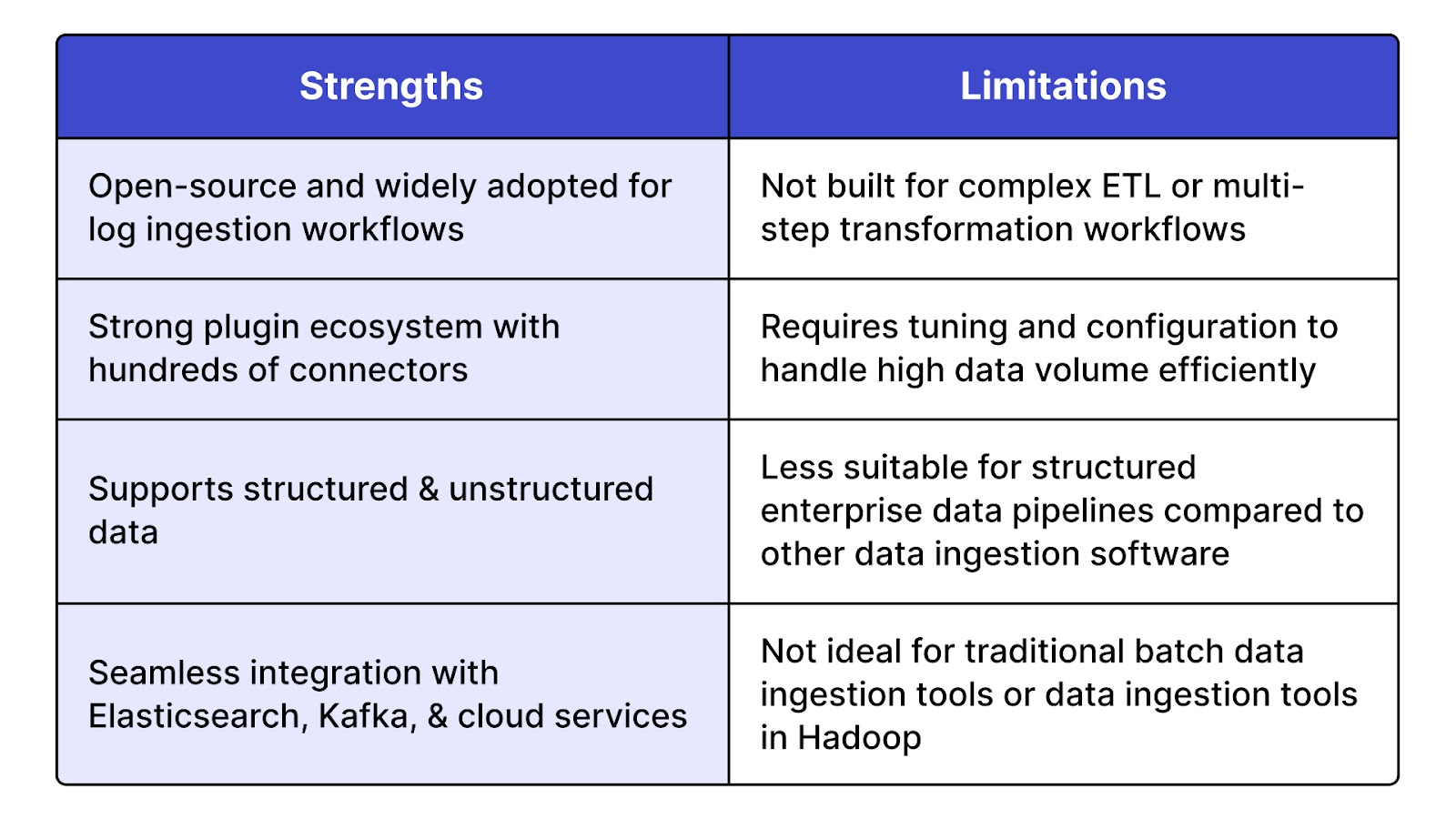
Matillion is a cloud-native data ingestion platform built to support ETL and ELT pipelines into cloud data warehouses like Snowflake, Amazon Redshift, Azure Synapse, and Google BigQuery. It enables fast ingestion and transformation of data from a wide array of SaaS applications, APIs, and databases. Matillion is a no-code/low-code data ingestion software with an intuitive UI, ideal for data teams looking to orchestrate and automate ingestion workflows without heavy engineering overhead.
Best use case
Ideal for mid to large-scale teams working with cloud warehouses who need streamlined data ingestion solutions with integrated transformation and scheduling capabilities.
Strengths vs Limitations
Matillion offers a free trial with limited capacity and functionality. Full usage is subscription-based and priced depending on compute time and deployment (on AWS, Azure, or GCP). While not open source, Matillion is trusted by leading data ingestion companies for its scalability and native cloud integration.
Whether you're modernizing legacy systems or scaling analytics, QuartileX helps you harness data for real growth.
See Cloud Services →
Choosing the right data ingestion software directly impacts the speed, reliability, and accuracy of your data pipelines. Poor tool selection can lead to data loss, bottlenecks, and increased engineering overhead. With growing data from APIs, IoT, and apps, scalable and secure ingestion is now a baseline requirement. The right solution ensures compatibility with your sources, supports your data volume, and aligns with your processing needs.
At QuartileX, we offer advanced solutions for data ingestion and transform fragmented data into real business insights that drive long-term success.

Here’s how we streamline your data ingestion:
Did you know that QuartileX leverages data ingestion tools like Fivetran and Hevo to streamline your data pipeline? Take a closer look at our data engineering services to upscale your data infrastructures for long-term success.
Choosing the right data ingestion tools ensures your pipelines are fast, reliable, and scalable from the start. The tools listed in this guide serve a range of use cases—from batch ingestion for reporting to real-time streaming for IoT. Use this list to align your tech stack with your data goals, infrastructure, and team capabilities. Always prioritize tools that meet your performance, cost, and integration requirements.
Many teams still struggle with fragmented pipelines, vendor lock-ins, or inefficient ingestion practices. QuartileX solves this by delivering tailored data ingestion solutions using industry-trusted tools like Fivetran, Hevo, and Kafka. From ingestion to insight, our team helps you build resilient, scalable architectures that power business intelligence.
Want to future-proof your data workflows? Get in touch with our data experts at QuartileX to optimize your ingestion pipelines for long-term success.
A: A data ingestion tool focuses on collecting and moving raw data from various sources to storage or processing systems. ETL platforms go a step further by transforming and cleaning that data before loading it into analytics-ready destinations. Some tools like Talend and AWS Glue combine both functions, while others like Kafka and NiFi are built specifically for ingestion. Choosing between them depends on whether transformation is a priority or if raw data movement is your main goal.
A: Open-source tools like Airbyte, Kafka, or NiFi offer flexibility and no licensing costs, but they require setup, maintenance, and in-house expertise. Managed tools like Fivetran, Hevo, and Stitch provide low-code interfaces, automated updates, and support, making them ideal for small teams or fast deployment. If your team lacks engineering resources, a managed solution reduces operational overhead. For custom pipelines or cost control, open-source platforms give you more control.
A: Yes, many organizations combine tools based on use case, latency, and infrastructure. For example, Kafka may handle real-time events while Fivetran manages scheduled SaaS syncs. Integration flexibility is key—choose tools that support common formats (like JSON, CSV, or Parquet) and connect well with your storage or processing layers. Just ensure your pipeline is monitored closely to manage dependencies and avoid data duplication.
A: Modern data ingestion software supports sources like APIs, SaaS tools (Salesforce, Shopify), databases (MySQL, PostgreSQL), log files, flat files, IoT devices, and cloud storage. Tools like StreamSets, Talend, and Azure Data Factory offer over 100 connectors, while open-source options like NiFi allow building custom source processors. Always check the connector list and source compatibility before selecting a tool.
A: No, batch and streaming tools serve different purposes. Batch data ingestion tools (like Fivetran or Stitch) move data at scheduled intervals and are suited for dashboards or periodic reporting. Streaming tools (like Kafka, Dataflow, and NiFi) process data continuously, enabling real-time use cases like fraud detection or live analytics. Some platforms support both modes, but each should be used based on the nature of your data and business needs.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


