
.png)

Managing data becomes more complex as companies expand. Teams work in silos, systems don’t always connect, and it becomes harder to get a complete and reliable view of the business. The challenge is no longer about collecting data, but about using it effectively across the organization.
This is where data mesh vs data fabric comes into play. Both offer solutions to modern data problems, but in different ways. Data fabric focuses on integrating systems and ensuring consistent access to data. Data mesh focuses on decentralizing ownership so that individual teams can manage and share their data more effectively.
In this guide, you’ll explore how each model works, what problems they solve, and how to choose the right fit for your data strategy.
TL;DR — Key Takeaways
If you are deciding between data mesh vs data fabric, start by identifying your main challenge. For system complexity, go with fabric. For scaling team-level data delivery, mesh is the better fit.
Data mesh is a decentralized data architecture that shifts ownership from a central data team to individual business domains. Each team manages its data as a product, ensuring it is clean, documented, and available to others in the organization.
This model is gaining traction. The global data mesh market is expected to grow from $1.9 billion in 2024 to $4 billion by 2030. Businesses are adopting it to improve agility, reduce bottlenecks, and scale data operations more efficiently.
Unlike traditional centralized models, data mesh aligns data responsibilities with those who generate and use the data daily.
To grasp how this works in real scenarios, let’s look at the core principles behind it.
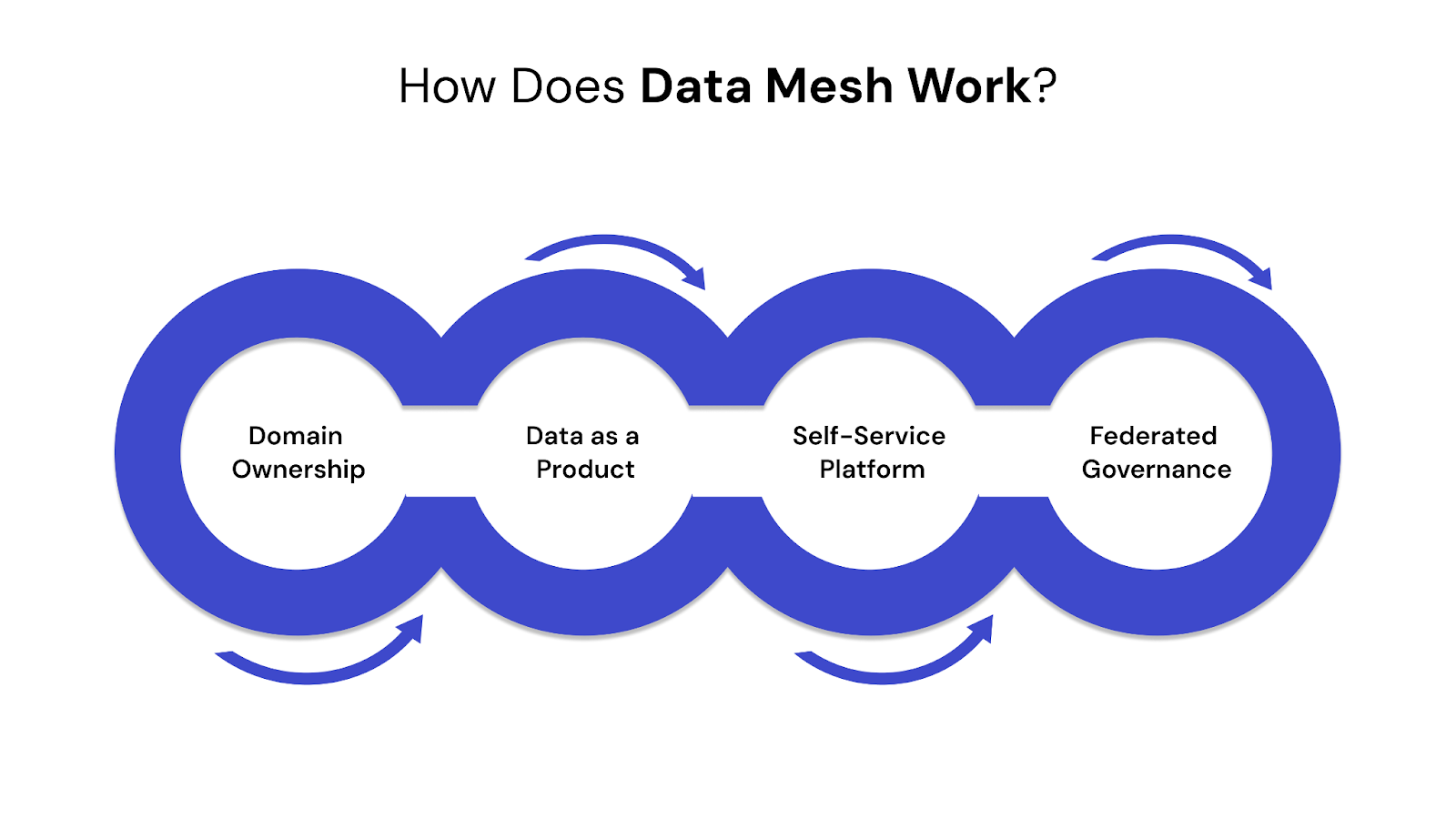
Data mesh changes how organizations manage data by distributing ownership across teams. Instead of a central data team handling everything, each department is responsible for its own data.
This model relies on four core principles that allow teams to build, share, and govern data independently while still aligning with company-wide standards.
Data mesh operates through four main principles:
This setup allows teams to work independently while still following company-wide standards.
To explore how to lay the right foundation for decentralized control and unified access, check out our guide on Steps and Essentials to Prepare Data for AI.
Data mesh offers more speed, flexibility, and local accountability, but it also introduces new challenges. It works best when teams have the skills to manage data effectively and when governance is strong.
Here's a quick look at the main benefits and trade-offs of this approach.
Pros
Cons
While data mesh is not tied to one tech stack, it typically uses tools that support decentralized ownership:
A central platform team sets up and maintains these tools, so each domain team can build and manage their own pipelines confidently.
If you're planning to structure raw or processed data for analytics and machine learning, The Ultimate Guide to Data Engineering Tools in 2025 is a helpful next read.
Data mesh helps organizations move faster by letting teams manage their own data without relying on a central team. When the people closest to the data control it, quality improves, and delays are reduced.
For example, a product team might:
This approach shortens feedback loops and allows decisions to be made with trusted, up-to-date data.
Example Scenario
A telecom company uses data mesh to distribute ownership across departments. The operations team manages its network performance data, while customer support manages complaint data. Each team builds pipelines and serves their data to the analytics platform without waiting for the central IT team.
Now let’s explore the alternative approach i.e., data fabric.
Data fabric is a unified architecture that connects data from different systems and locations into one accessible layer. It integrates storage, metadata, and data management tools to make data available across the organization.
The data fabric market is expected to grow from $3.1 billion in 2025 to more than $12.5 billion by 2035. This growth reflects the need for integrated and well-governed data access in large, complex enterprises.
Data fabric is more focused on technology and automation. It works well when you need to access and manage data across cloud, on-premise, and hybrid systems.
To understand its full potential, let’s walk through how data fabric functions.
Data mesh shifts the responsibility of managing data to the people who generate and use it. Instead of relying on a central team, it gives each department control over its own data, processes, and pipelines.
This setup allows teams to move faster, manage data, take ownership of quality, and design data in ways that serve their specific goals.
For this model to work, it follows four main principles:
This allows users to find and use data without knowing where or how it is stored.
Data mesh offers more agility and team-level control but also demands a higher level of data maturity across the organization. Below are the main advantages and trade-offs to consider:
Pros
Cons
Data fabric relies on a unified technology layer that automates access, integration, and governance:
These tools work together to create a connected layer that supports real-time data access across cloud, on-premise, and hybrid systems.
Optimize your data infrastructure with modern pipelines and architecture that enable faster analytics and smarter decisions at scale.
Future-Proof Your Data Stack →
Data fabric makes it easier for businesses to use data from anywhere, without needing to know where it’s stored or how to access it. It connects systems, applies consistent rules, and reduces manual effort.
For example, an analytics team might:
This leads to better efficiency, faster insights, and fewer roadblocks in accessing high-quality data.
Example Scenario
A healthcare provider implements data fabric to connect patient records from hospitals, labs, and insurance systems. Using a metadata-driven platform, doctors and analysts access patient insights without needing to move or duplicate the data.
Let’s now directly compare both data mesh vs data fabric to help you decide.
Build high-performance pipelines that keep your data flowing reliably — from ingestion to insight.
Build with Data Engineering →
Not all data challenges need the same solution. Some businesses need centralized control and consistency, while others prioritize speed and domain-level ownership. Understanding how data mesh and data fabric differ can help you align your data strategy with your team structure and business goals.
Below is a side-by-side comparison of data mesh vs data fabric help you evaluate which approach better fits your needs:
Also read: Cloud Computing Solutions: Key Insights for Business Success
Beyond architecture, both models play a growing role in AI development.
AI systems are only as good as the data they use. That’s why both data fabric and data mesh are gaining traction in AI-driven strategies and organizations, though they support AI in very different ways.
Data fabric offers an integrated, technology-first approach to managing data across cloud, on-premise, and hybrid environments. It benefits AI initiatives when there’s a need for automation and end-to-end data access across multiple systems.
It supports AI by:
This makes data fabric a strong choice when your AI solutions rely on connected systems and centralized control.
Data mesh focuses on decentralization, which works well in large organizations where AI use cases vary by department or business unit. Instead of routing all data through a central team, it lets domain teams manage their own data products.
It enables AI by:
Data mesh fits best when you want AI innovation to come from the ground up, driven by the teams closest to the data.
To explore how modern businesses unify fragmented data systems, check out our guide on Exploring Tools and Solutions for Modern Data Integration.
Still unsure which model to use? This section will help you choose.
Deciding between data mesh and data fabric depends on your business structure, team maturity, and how data is used across the organization. Both aim to improve access and usability, but they solve different challenges and suit different operating models.
Here’s how to know which one is the right fit:
Yes, many companies do. For instance, Netflix uses a data mesh approach internally by giving its engineering and business teams control over their own data products. At the same time, it applies data fabric principles through centralized metadata management and standardized governance to ensure smooth access and compliance across its data ecosystem.
This blended model allows Netflix to unify and govern its data environment while enabling teams to innovate independently. Fabric improves access across systems, and mesh improves how data is created and shared within teams.
Let’s close with some final thoughts and key takeaways.
Understanding the difference between data mesh and data fabric helps you make smarter choices about how to manage and scale data. These models are not opposing forces. Data fabric creates a unified, governed layer for accessing data across systems. Data mesh empowers individual teams to manage and deliver data that fits their needs.
Used together, they help:
Choosing the right approach depends on your data complexity, team structure, and how quickly insights need to reach decision-makers. Combining both gives you the best of consistency and agility.
Modernize Your Data Strategy with QuartileX
QuartileX brings clarity to complex data ecosystems by combining the strengths of data mesh and data fabric. Our platform is built for flexibility, allowing your teams to move fast while staying compliant and connected.
We help you:
Ready to align your data strategy with business goals? Explore our Data Engineering Services or speak with our specialists to get Partnered with QuartileX
Streamline your data pipelines and architecture with scalable, reliable engineering solutions designed for modern analytics.
See Data Engineering Services →
Data mesh is a strategic method for managing data across distributed teams. It focuses on decentralizing ownership so each business unit can treat its data as a product, supported by shared tools and standards.
A business domain refers to a specific area within an organization, like sales or marketing. The team within that domain manages its data because they understand how it is used in their daily operations.
Data fabric is an architectural approach. It connects data across different platforms and uses a collection of tools for integration, quality control, and access management.
It collects and organizes data from various sources into one structured environment. This helps users find reliable data more easily and ensures company-wide rules are consistently applied.
Data mesh allows teams to manage their own data workflows without depending on a central team. This speeds up access to information and helps large organizations respond to change more effectively.
Yes, many companies do. Data fabric improves integration and consistency, while data mesh allows teams to manage their own data. Together, they support better data access and team collaboration.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


