


Data platform architecture for data science and analytics refers to the structured design of systems that manage data ingestion, processing, storage, and access across use cases like machine learning, forecasting, and business reporting. As 98% of organizations adopt cloud infrastructure, these architectures must support real-time pipelines, secure environments, and scalable computation.
This guide explains key components, platform patterns, and deployment models, offering actionable insights for building robust data science platform architecture and data analytics platform architecture.
Did you know? Centralized data platform architecture can speed up decision-making by up to 40%, thanks to improved data access and integration
Data platform architecture is the structured design of interconnected tools, systems, and workflows that manage data collection, processing, storage, and usage at scale. It serves as the backbone of data-driven operations, supporting everything from raw data ingestion to real-time analytics and model deployment. A well-structured architecture ensures that data flows securely and efficiently across systems while maintaining quality, consistency, and governance. It enables teams to build scalable infrastructure that supports both analytics and machine learning workloads.
To understand its impact more clearly, let’s look at how it supports end-to-end data operations.
Now that we’ve covered how it works, let’s compare traditional systems with modern data platform architecture models.
Want to go deeper into how raw data becomes actionable? Check out Exploring the Fundamentals of Data Engineering: Lifecycle and Best Practices next.
Understanding the shift from legacy to modern systems sets the stage for exploring the core components that power data science and analytics platforms.
Building an effective data platform architecture requires a clear understanding of its foundational components. These components ensure that data flows reliably from ingestion to insight, supporting both analytics workflows and data science experimentation. While specific requirements may vary, most architectures share a common set of layers that form the operational backbone.
Let’s start by looking at the core layers shared across science and analytics platforms.
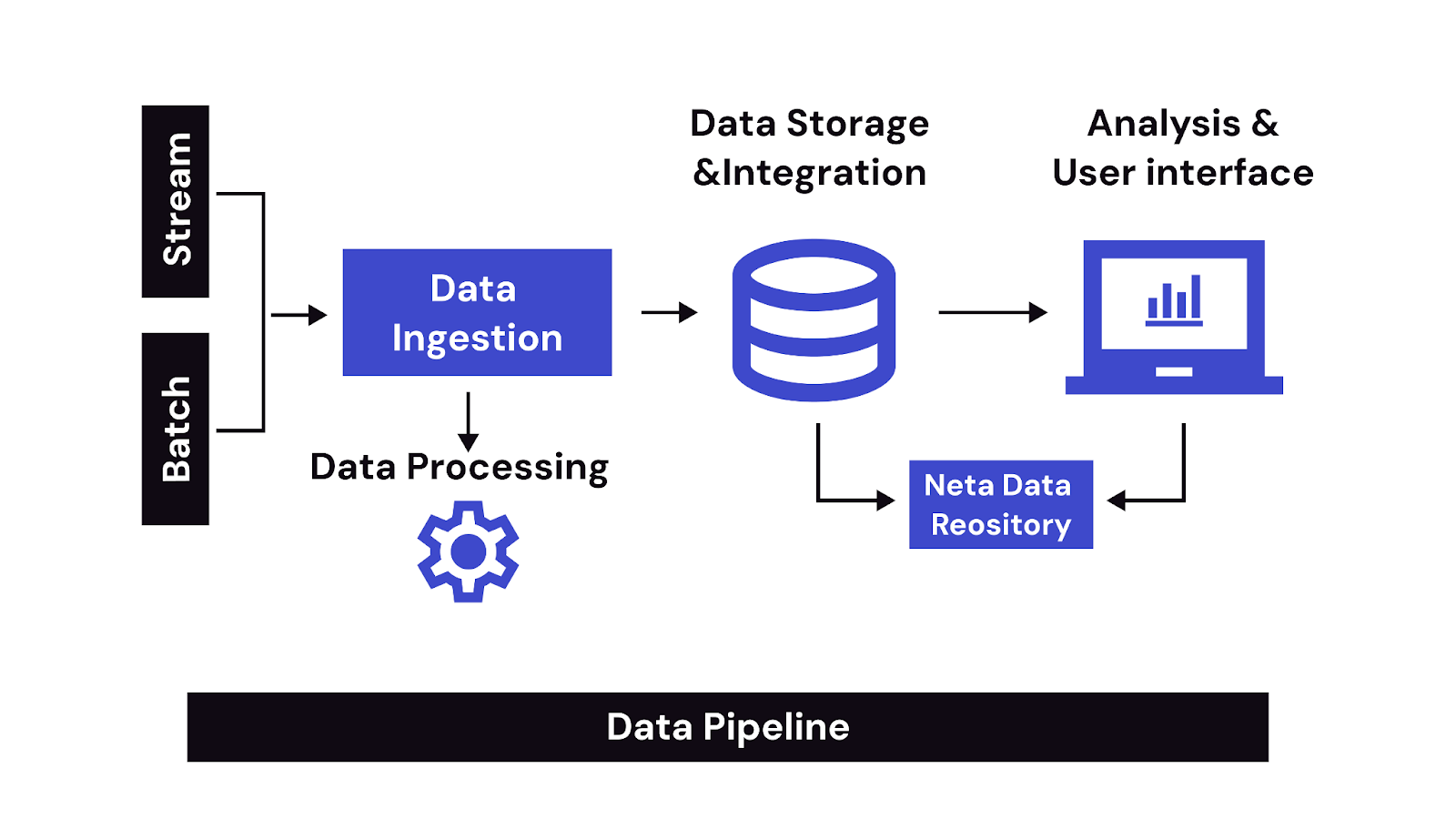
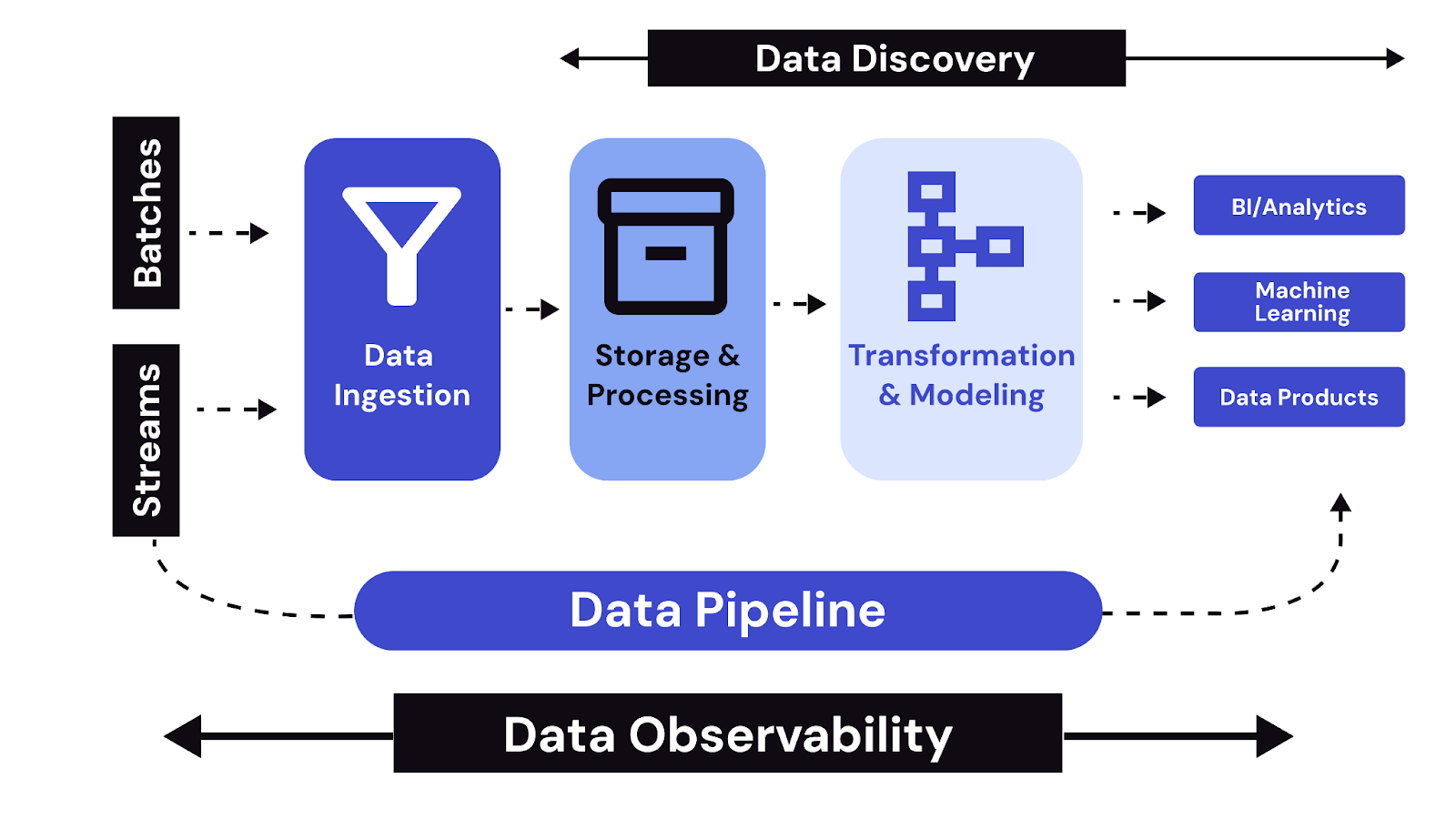
Regardless of whether a platform is designed for analytics or data science, several architectural layers are universally essential to ensure consistent, scalable, and secure data operations. These layers serve as the backbone of modern data platform architecture, enabling reliable data flow, collaboration, and system-wide observability. Below are the key components shared across both data science and analytics platform architectures:
1. Data Ingestion Layer
This layer handles the intake of raw data from multiple sources—such as APIs, IoT devices, CRM systems, databases, and logs. It supports both batch ingestion (e.g., scheduled ETL jobs) and real-time streaming (e.g., Kafka, Flink) to meet varying latency needs. The ingestion layer often includes validation steps to detect missing values, schema mismatches, or duplicate records.
2. Storage Layer
Data needs to be stored in a format that supports retrieval, processing, and scalability. Most platforms adopt a multi-tiered storage model that includes:
We help forward-thinking teams build secure, scalable systems for analytics, AI, and business agility.
Plan Your Modernization with Us →
3. Processing Layer
This is where data transformation, enrichment, and computation occur. It includes:
Processing pipelines often include operations like joins, aggregations, data quality checks, and model scoring (in science platforms).
4. Metadata and Cataloging Layer
Metadata management enables data discovery, lineage tracking, and schema management. Tools like Apache Atlas, Amundsen, or DataHub provide a searchable catalog of available datasets, including their ownership, update frequency, and usage stats. This layer ensures that users can trust and find the right datasets without manual guesswork.
5. Governance and Security Layer
Data governance is embedded throughout the platform to enforce access control, ensure compliance, and audit usage. Role-based access control (RBAC), attribute-based access control (ABAC), and data masking techniques are commonly implemented. Logging and monitoring tools like Prometheus, Grafana, or Splunk are often integrated to track data pipeline health and security incidents.
6. API and Access Layer
This layer provides interfaces for users and applications to interact with data. It could include:
Looking to choose the right tools for your data platform? Read Top Data Architecture Tools for 2025: A Guide to explore the best solutions for your stack.
Standardizing access via APIs and query engines improves usability and governance across diverse teams. While these shared layers form the foundation, each platform type builds on them to meet its unique functional needs.
While data science and analytics platforms share a common foundation, their specific requirements shape how that architecture is implemented and extended.
Data science platforms typically require:
Analytics platforms focus on:
Both platform types may operate on the same underlying architecture, but their configurations reflect different goals—exploration and modeling in science, versus speed and clarity in analytics. To support these varied needs, organizations adopt specific architectural patterns that align with their data goals and operational scale.
As data operations scale, choosing the right architectural pattern becomes critical. The choice impacts everything from performance and governance to cost and team workflows. Below are key architecture models and design patterns commonly used in data platform architecture, each suited to specific use cases and operational needs.
Ensure compliance, transparency, and security across your data lifecycle with expert governance frameworks tailored to your needs.
Improve Data Governance →
2. Lambda and Kappa Patterns
Lambda is suited for platforms requiring both precise batch jobs and live data views. Kappa is best when real-time responsiveness is the priority and batch isn’t necessary.
3. Data Lakehouse and Data Mesh Models
Lakehouse simplifies architectures by merging capabilities, while Data Mesh shifts responsibility to domain teams, encouraging scalability and autonomy.
Planning a system upgrade or tech stack overhaul? Check out Software Migration Simplified: A Complete Guide for 2025 to avoid downtime, data loss, and costly missteps.
4. Cloud-Native and Hybrid Deployments
Cloud-native works well for startups and cloud-first orgs, while hybrid is often necessary for regulated industries or legacy systems in transition.
Designing a scalable data platform means aligning technical decisions with real business needs, team workflows, and operational constraints. Below are key principles to follow—each illustrated with real-world examples.
1. Align tools with business and team needs
Select technologies based on what your teams actually use and need—not just what’s trending. Focus on compatibility, team expertise, and long-term support.
2. Design for modularity, not just scale
Avoid monolithic designs. Modularity enables teams to iterate, upgrade, or replace components independently.
3. Ensure security, compliance, and data quality
Build in governance from the start to meet internal standards and external regulations.
4. Monitor system performance and cost
Scaling without visibility often leads to waste or outages. Observability tools and proactive cost control are critical.
Selecting the right data platform architecture means understanding the distinct goals of data science and analytics workflows—and designing accordingly. While both rely on shared infrastructure, their technical and operational requirements differ significantly.
Comparing data science and analytics requirements
We’ll assess your current infrastructure and help you map a smarter, more cost-efficient path forward.
Request a Readiness Assessment →
Key questions to ask before building or buying
Before you commit to any architecture—custom-built or managed—use this checklist to assess fit:
Want to turn your data into decisions that drive impact? Read How to Build a Scalable, Business-Aligned Data Analytics Strategy for practical steps that connect analytics to real outcomes.
QuartileX can help your business transform raw data into strategic insights through advanced visualization and AI-driven analytics. We unlock your data’s potential through cutting-edge technology, expert guidance, and actionable insights—so you can work smarter, adapt quickly, and drive tangible growth.
Design and deploy secure, scalable cloud environments tailored to your workloads — with compliance, performance, and growth built in.
Secure Your Cloud Future →.png
)
Ready to take your data platform to the next level? Connect with our experts and get started today!
Data platform architecture is the foundation for building reliable, scalable systems that support both data science experimentation and analytics reporting. To get it right, align platform design with specific team needs, prioritize modularity, and choose tools that scale with your workloads. Use governance, observability, and cost controls to maintain system health. Whether you're modernizing or starting fresh, these principles help future-proof your architecture.
Yet many teams struggle with tool sprawl, inconsistent data flows, and unclear ownership across domains. QuartileX helps organizations design and implement tailored data platform architectures that meet real business and technical goals—without overengineering. Our experts bring proven frameworks and cross-functional alignment to every project.
Get in touch with our data experts to assess your current setup, identify key gaps, and build a platform that’s truly built to scale.
A: It enables scalable access to raw data, high-performance compute, and reproducible experiments. Without it, model development becomes slow and fragmented. Good architecture also supports tool integration like Jupyter, Spark, and MLflow.
A: Data science platforms are built for experimentation, using raw data, custom code, and scalable compute. Analytics platforms prioritize speed, structure, and dashboards using curated datasets. Both share core layers but are optimized for different goals.
A: Centralized systems work well for smaller teams needing unified governance and access. Distributed architectures suit large organizations with domain-level ownership and autonomy. Choose based on team structure, scale, and governance complexity.
A: Modular systems allow independent updates and easy integration of new tools. They reduce downtime and technical debt over time. It’s essential for future-proofing and flexibility.
A: Map tools to core use cases like ingestion, modeling, and reporting. Evaluate scalability, ease of use, integration, and team familiarity. Involve both technical and business users in decision-making.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


