


Data integration architecture is the blueprint for designing scalable frameworks that unify and manage big data across cloud platforms, APIs, and real-time sources. As organizations shift to distributed systems and event-driven architectures, the need for reliable, high-throughput integration models has become critical. Poorly structured pipelines contribute to inconsistency, latency, and non-compliant data—issues that cost U.S. businesses an estimated $3.1 trillion annually.
This guide breaks down key components, patterns, and architecture types. It helps you make informed decisions to build robust, future-ready big data integration architecture.
Data integration architecture is the structured framework that governs how data is collected, connected, transformed, and delivered across systems. It ensures that data from diverse sources—whether databases, APIs, or streaming platforms—is consistently processed and made usable for downstream applications. This architecture becomes the backbone of any data-driven organization, especially when working with large-scale, high-velocity information flows.
Think of data integration centers as the command center for your data pipelines—organized, scalable, and built for speed.
To understand its unique role, let’s look at how big data integration architecture differs from traditional models.
How Big Data Integration Architecture Differs from Traditional Models?
Streamline your data pipelines and architecture with scalable, reliable engineering solutions designed for modern analytics.
See Data Engineering Services →
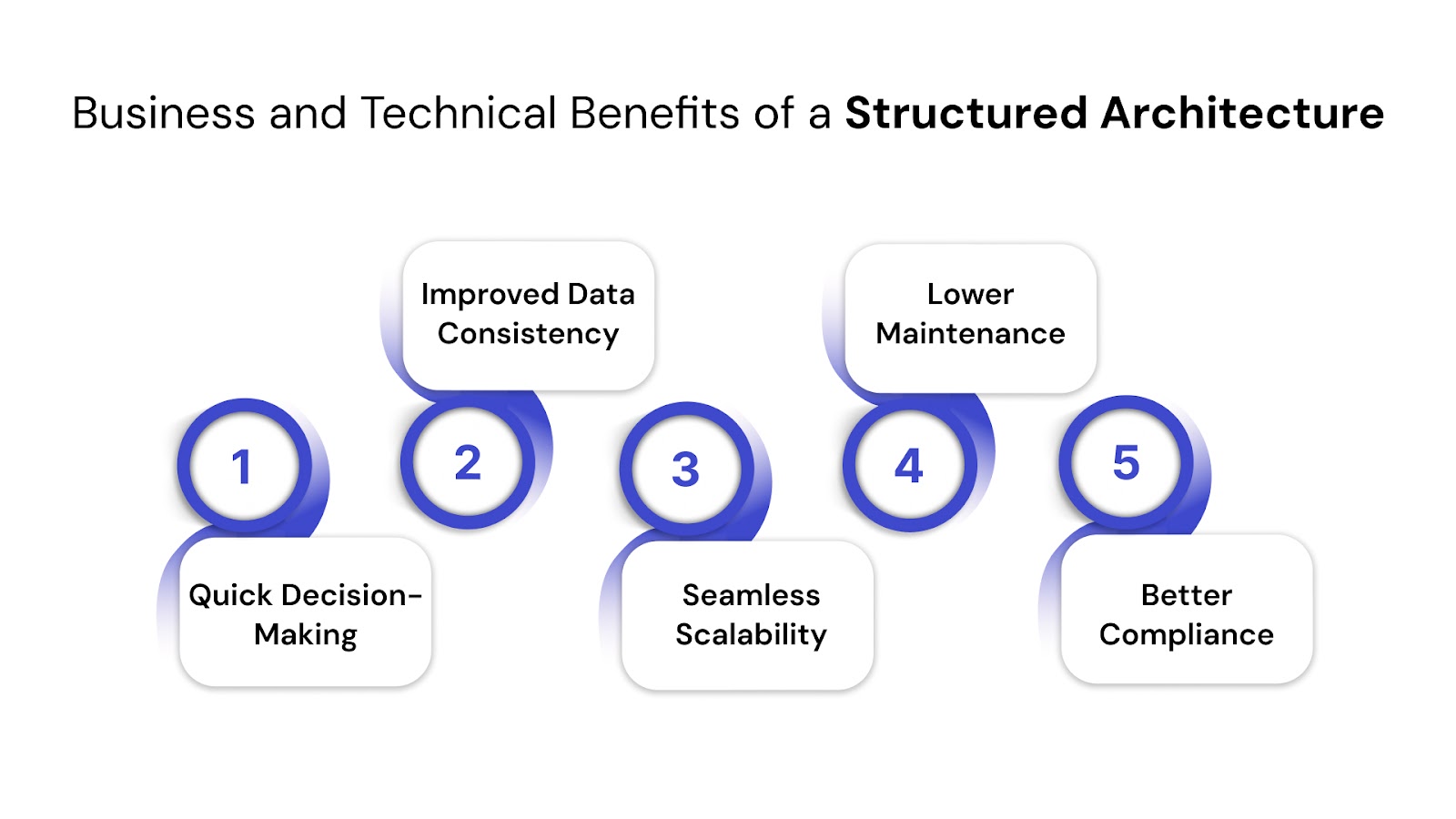
With a clear understanding of how big data integration architecture differs from traditional models, it’s equally important to recognize what you gain by designing it right—both from a business and technical standpoint.
To fully understand how data integration architecture operates in practice, it helps to explore how data flows through each stage. Check out our guide on Data Pipelines Explained: Everything You Need to Know to see how architecture decisions shape real-time data movement, transformation, and delivery.
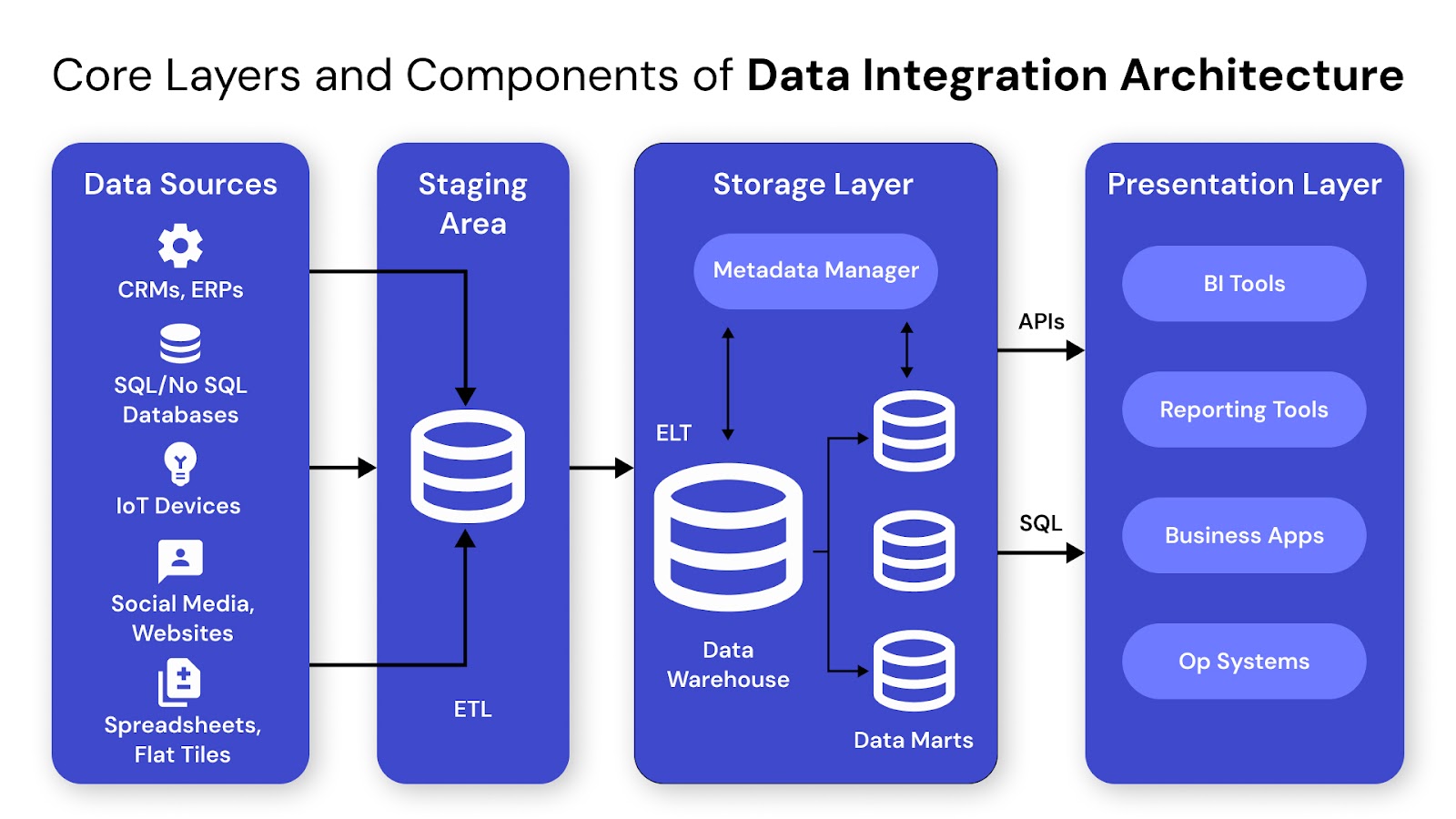
A well-designed data integration architecture is built on clearly defined layers, each handling a specific part of the data journey. These layers work together to ingest, process, store, manage, and deliver data across systems. Understanding each layer helps you identify where bottlenecks, quality issues, or latency problems might arise. This section breaks down the core layers and components that form the foundation of scalable integration frameworks.
The source layer connects your architecture to upstream systems, enabling raw data flow into pipelines. It must support various data types, formats, and ingestion speeds while ensuring validation and consistency at the entry point.
This layer prepares raw data for downstream use by applying transformation, cleaning, and quality checks. It ensures your data is consistent, usable, and aligned with business logic.
Migrate from legacy systems to modern infrastructure with zero disruption, complete security, and full business continuity.
Start Your Migration Plan →
This layer stores processed data and makes it accessible for querying, reporting, or application use. It’s optimized for performance, scalability, and user access across tools and teams.
This layer provides visibility, control, and automation across the data integration pipeline. It helps teams track data movement, monitor health, and manage workflows efficiently.
This layer ensures that data access, usage, and compliance are controlled and auditable. It protects sensitive data, enforces policies, and supports regulatory requirements across the architecture.
To get the most out of your data integration architecture, you also need a strong orchestration layer to manage workflows and dependencies. Read Understanding Data Orchestration: Process, Challenges, Benefits and Tools to learn how orchestration ties all your layers together and keeps your pipelines running smoothly.
Architectural models and patterns define how data moves, transforms, and is delivered across systems. Choosing the right model affects everything from scalability and performance to cost and maintenance. These patterns help standardize integration across growing data sources, formats, and workloads in cloud or hybrid environments.
Let’s start by looking at the common integration types used in data integration architecture.
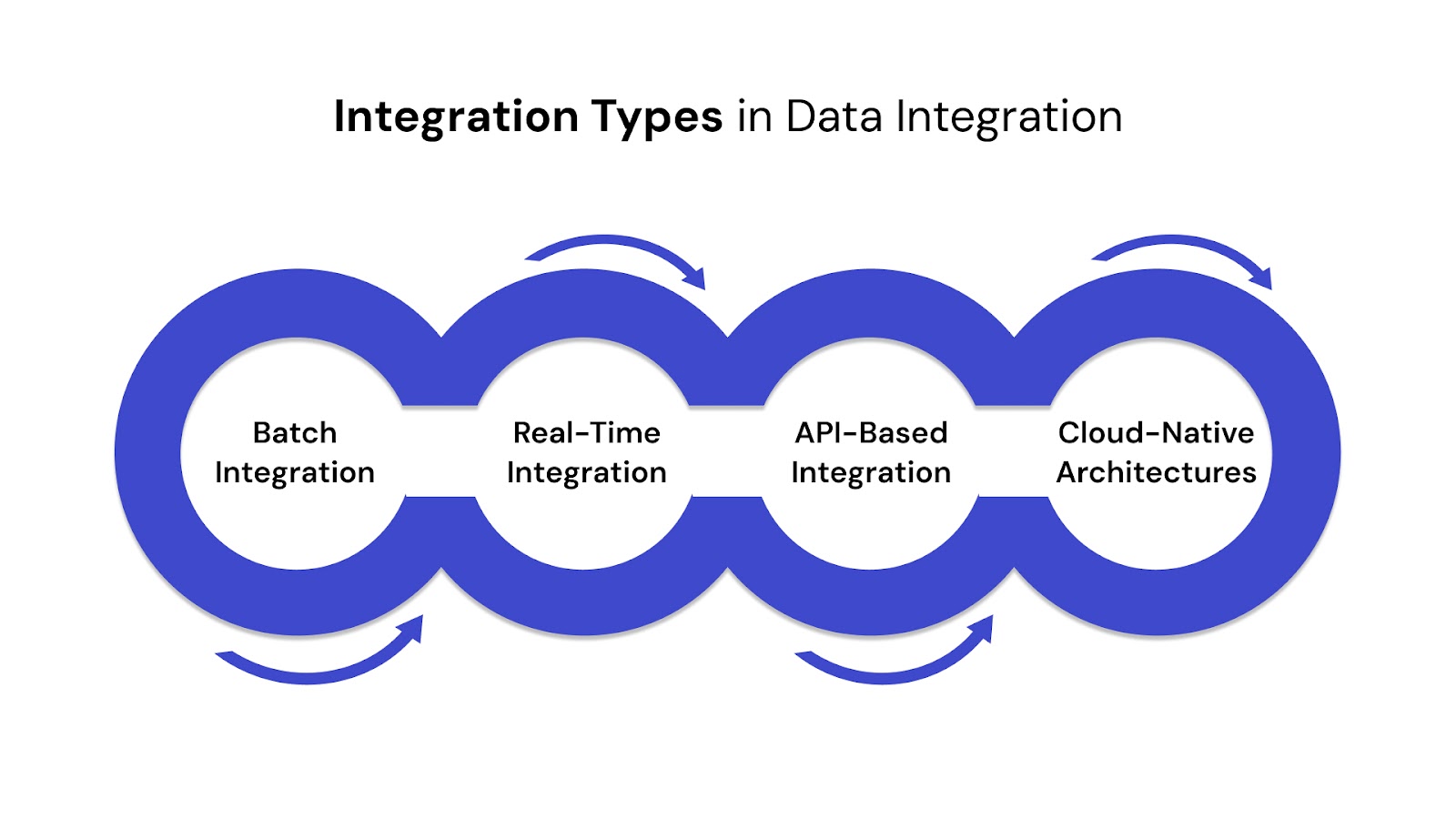
Choosing the right integration type depends on your data velocity, system dependencies, and business needs. Below are four commonly used integration types in modern data integration architecture:
Build a governance framework that not only meets compliance needs but drives trust, transparency, and business value from your data.
Build Your Governance Framework →
Architectural patterns define the structural flow of data and how integration logic is centralized, distributed, or abstracted. Each pattern supports different levels of flexibility, latency, and system complexity. Here are four widely adopted patterns in modern data integration:
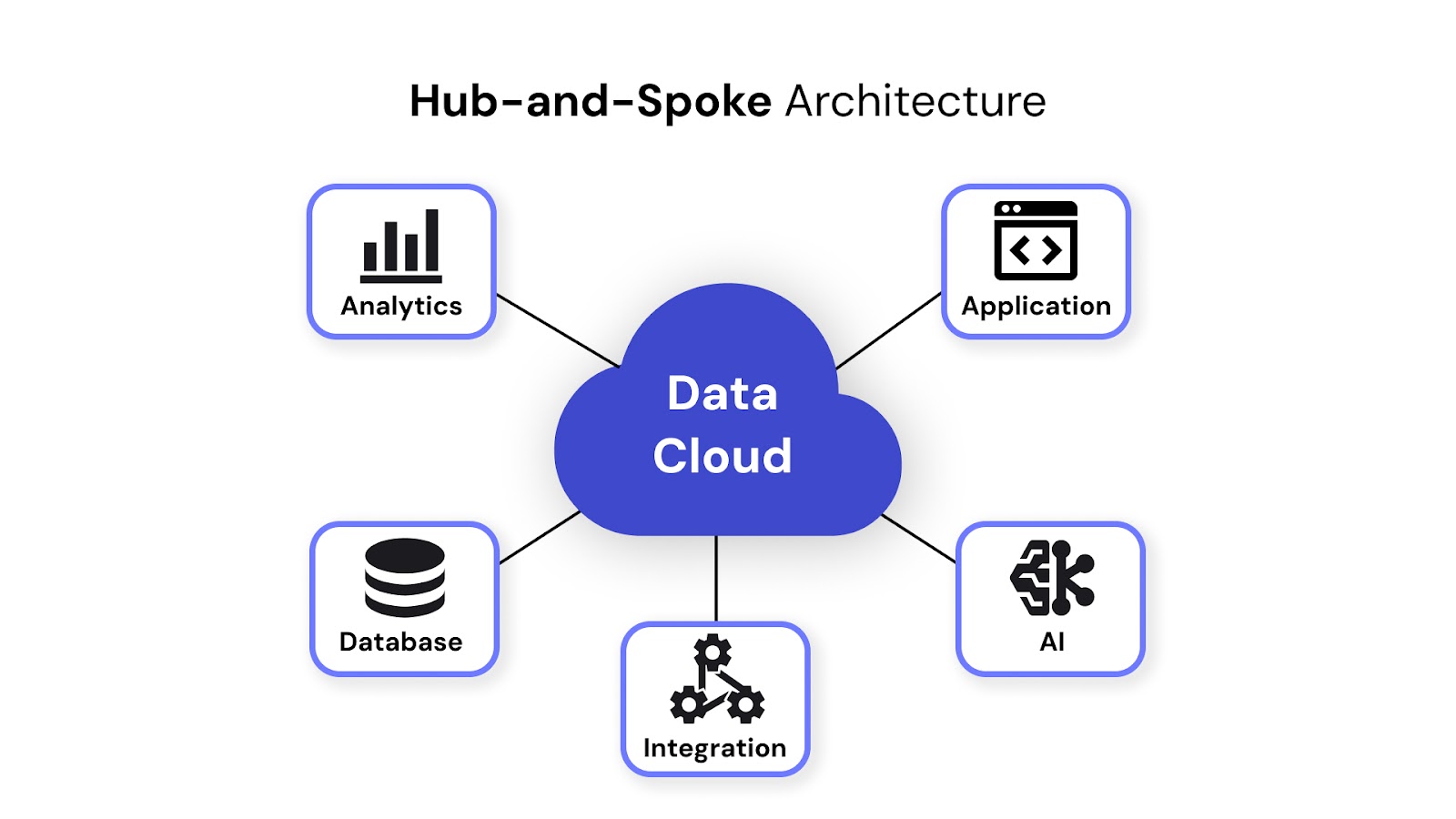
A central hub manages all data flows between source and target systems. This simplifies control and monitoring but can become a bottleneck if not scaled properly. Ideal for organizations with strict governance or centralized IT teams.
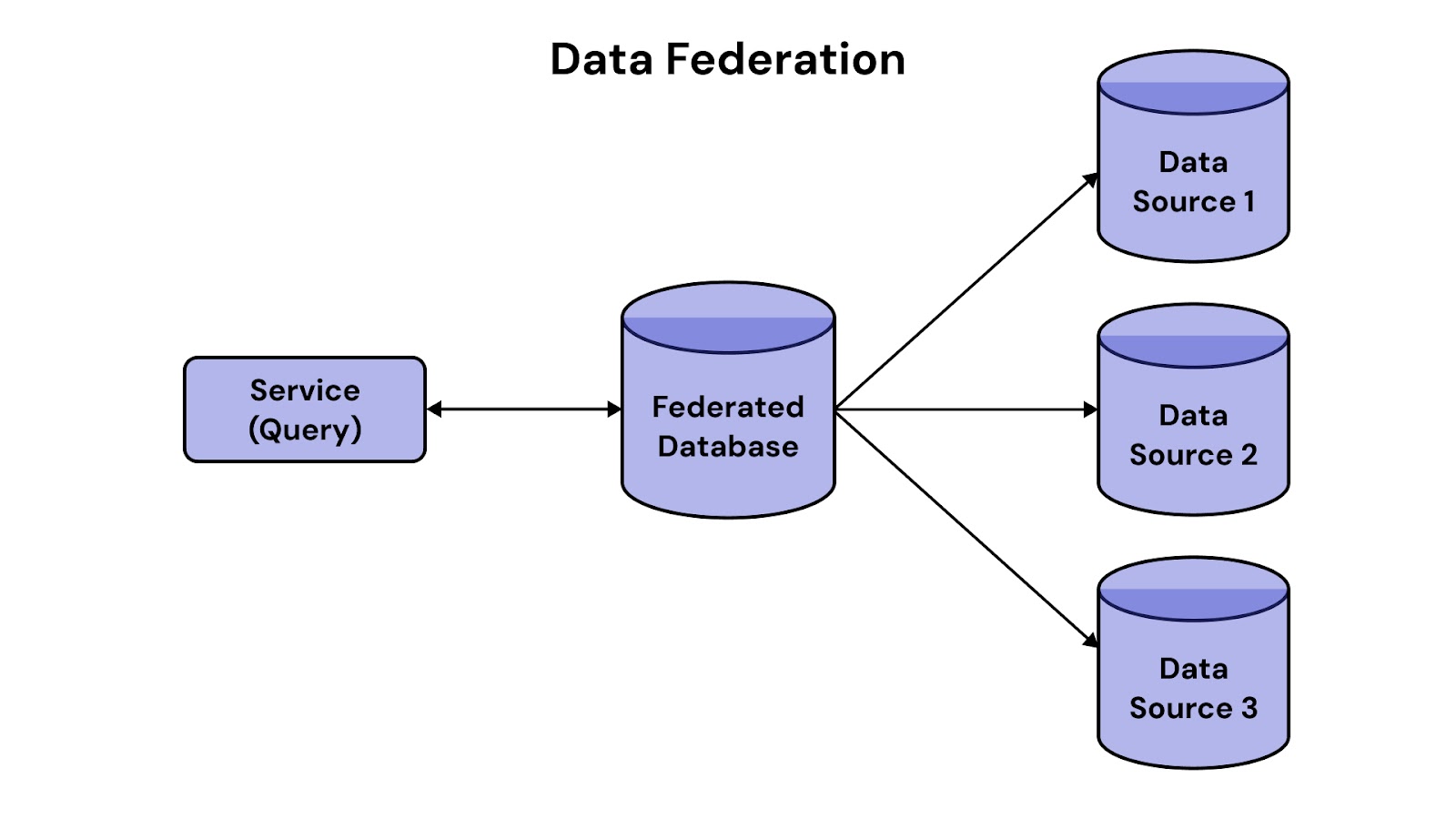
Combines data from multiple sources virtually without moving it into a single repository. It enables unified access using a single query layer while keeping data in its original location. Useful when low-latency analytics is needed without physical data consolidation.
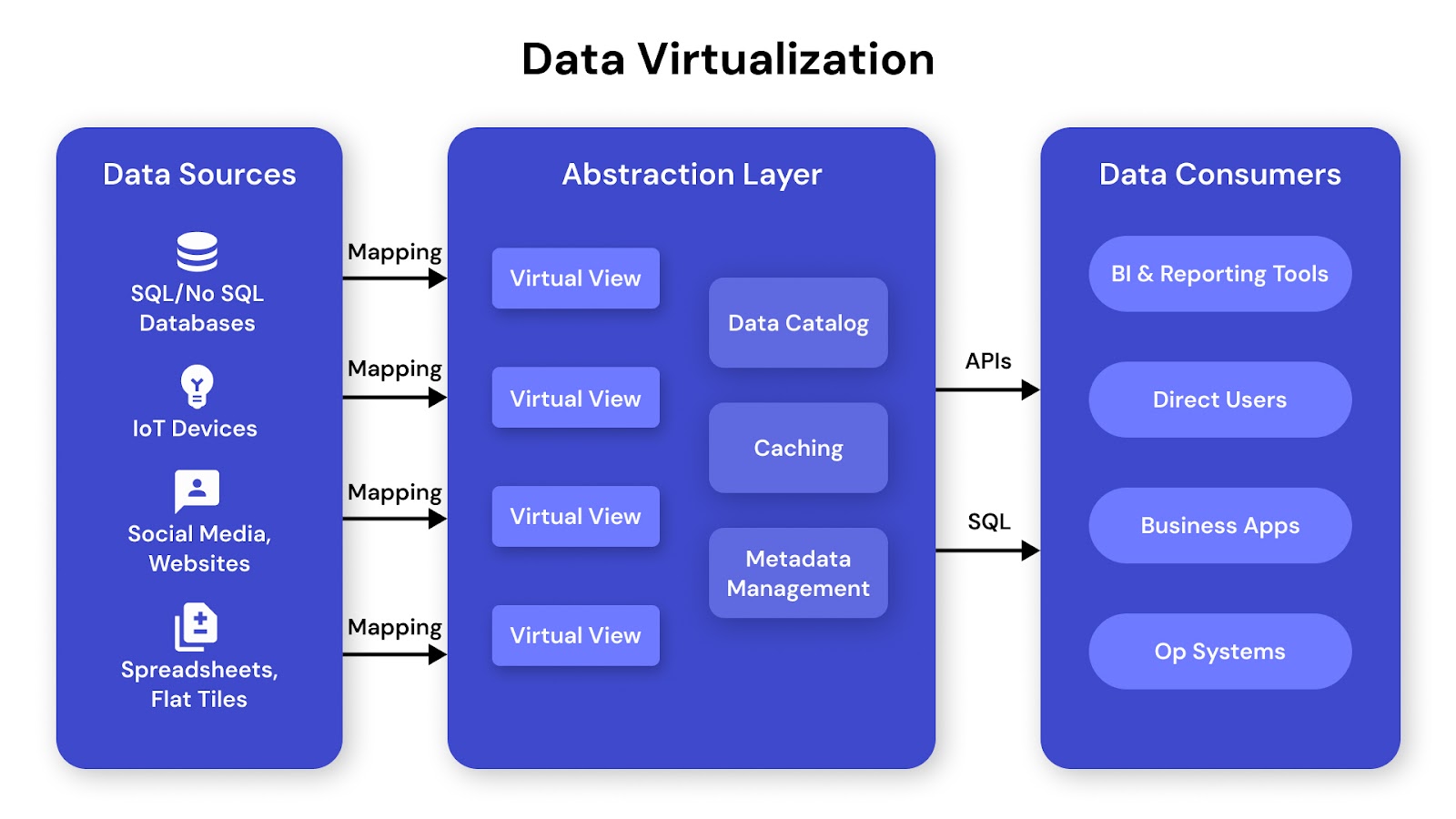
Creates an abstraction layer that lets users access and query data from multiple systems as if it's from one source. Unlike federation, it can apply transformations and joins in real-time. This reduces duplication and enhances agility in analytical environments.
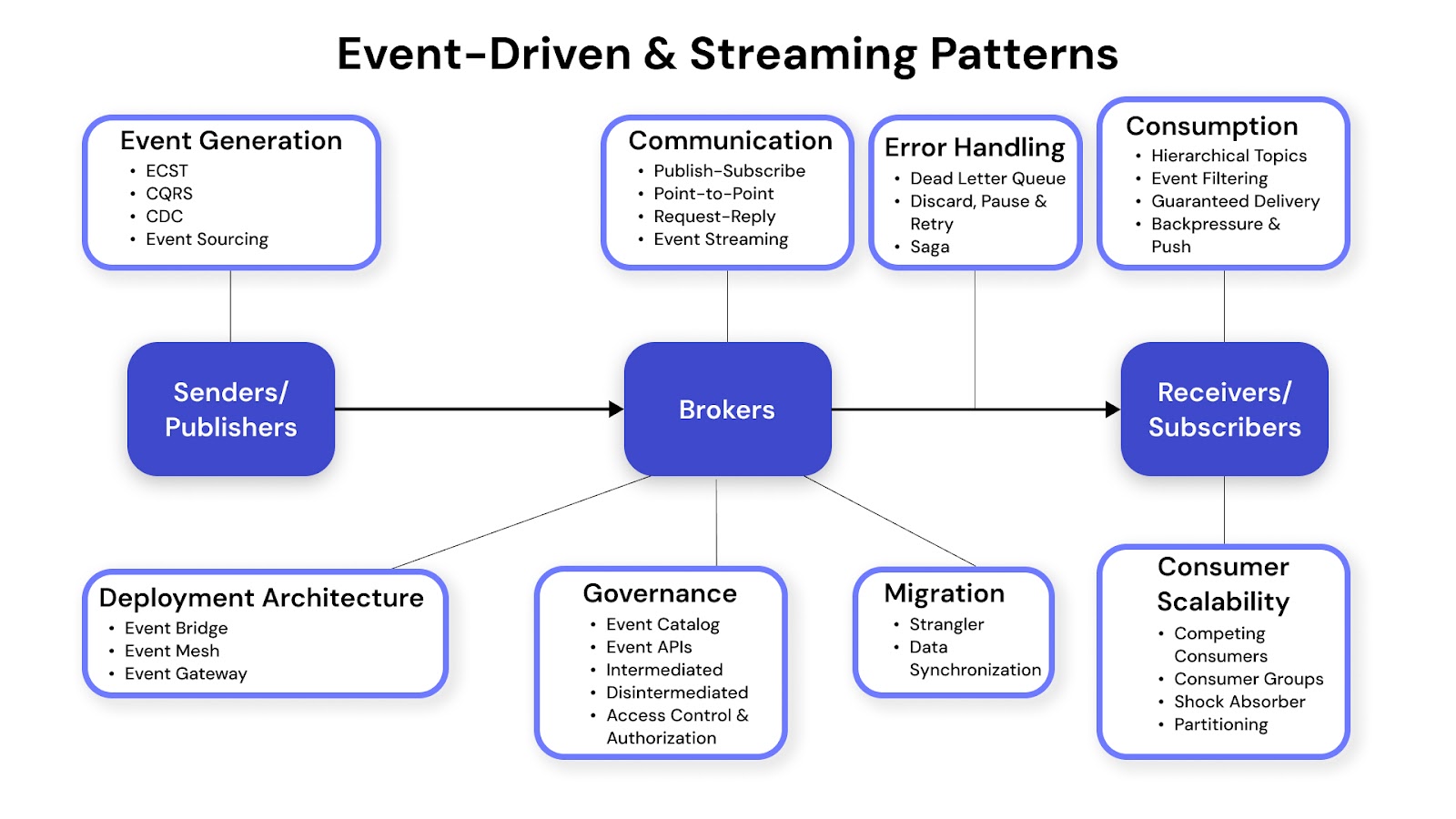
Data is moved and processed as events occur, using message brokers like Apache Kafka or AWS Kinesis. It supports real-time applications such as clickstream analytics, fraud detection, and IoT. These patterns are essential when latency and responsiveness are critical.
Looking to enhance your skills at data engineering? This guide on data engineering is just for you!
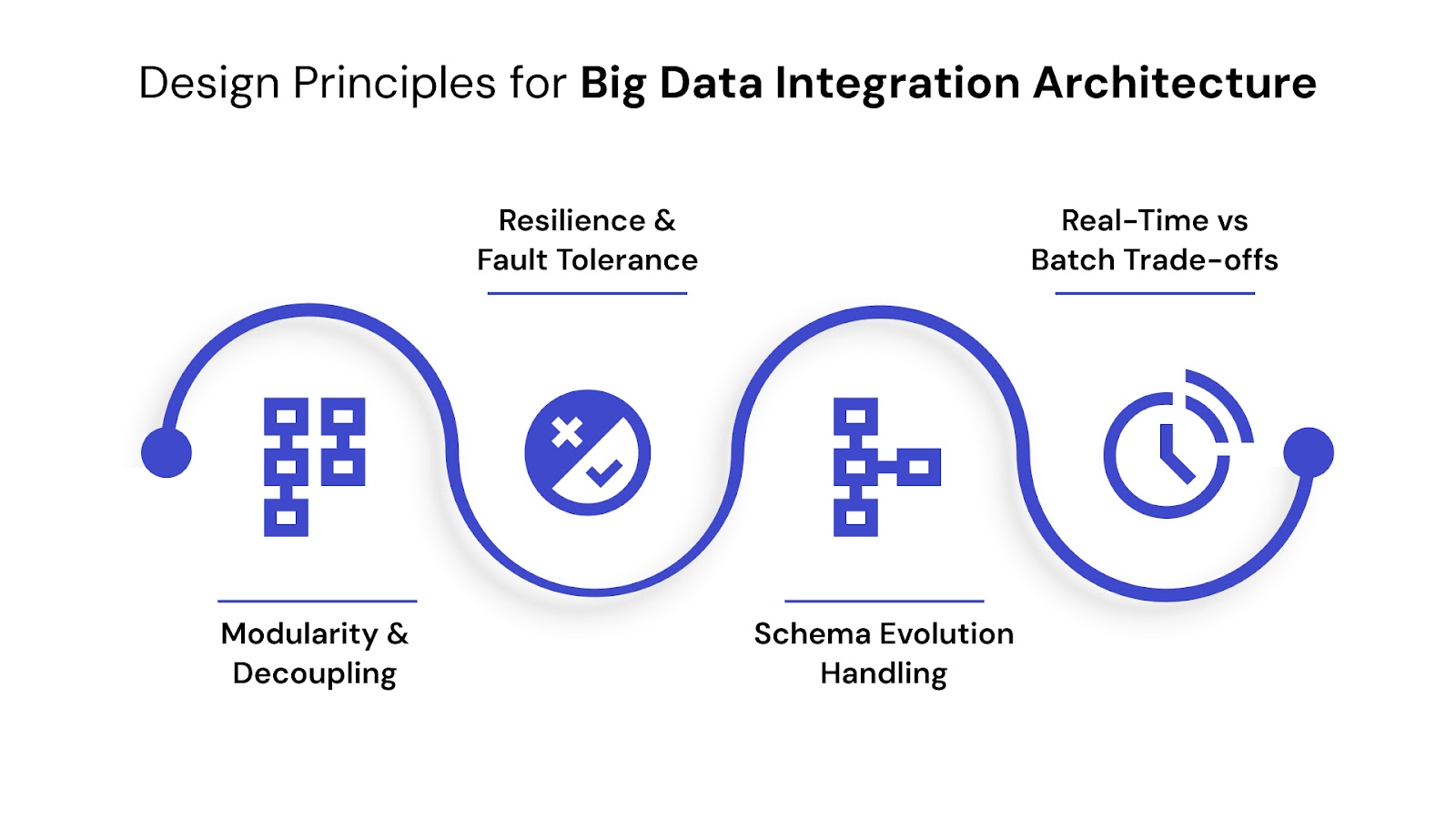
Building a scalable data integration architecture requires more than just tools—it demands thoughtful design principles that allow your system to grow, adapt, and perform reliably. The following principles ensure your architecture remains efficient, resilient, and future-proof as data sources and volumes evolve.
1. Modularity and Decoupling
Design integration components as independent modules that can be updated or replaced without disrupting the entire system. This enables easier maintenance, parallel development, and faster onboarding of new data sources. For example, use microservices or containerized ETL tasks to isolate logic.
2. Resilience and Fault Tolerance
Failures are inevitable in distributed environments. Your architecture should detect, contain, and recover from errors without manual intervention. Implement retry logic, checkpointing, and dead-letter queues to ensure data reliability across pipelines.
3. Schema Evolution Handling
Data formats often change over time—fields may be added, removed, or renamed. Scalable systems must support backward and forward compatibility using schema registries, versioning, or dynamic transformations to avoid integration breakage.
4. Real-Time vs Batch Trade-offs
Not all workloads require real-time processing. Choose between batch and streaming based on latency needs, system load, and cost. For example, use streaming for fraud alerts and batch for nightly reporting to balance performance and efficiency.
We help forward-thinking teams build secure, scalable systems for analytics, AI, and business agility.
Plan Your Modernization with Us →
Selecting the right data integration architecture is a strategic decision that depends on your organization’s data landscape, performance goals, and operational constraints. A one-size-fits-all model rarely works—your architecture must align with specific business and technical requirements.
Evaluate the scale and sensitivity of your data. High-volume environments may need distributed, cloud-native architectures. Real-time use cases demand low-latency, event-driven pipelines. Budget constraints may affect tool choice and storage design, while industries like finance or healthcare must prioritize compliance (e.g., GDPR, HIPAA).
Use batch architectures for large, periodic data transfers such as data warehousing or backup. Choose streaming or event-driven architectures for applications like fraud detection or real-time dashboards. Opt for API-based or hybrid models when integrating across SaaS platforms or microservices with variable data formats and frequency.
The right tools can simplify complex integration tasks, improve scalability, and reduce development time. Whether you're handling real-time streams or orchestrating large-scale batch jobs, modern data integration platforms offer flexible features to support your architecture.
Here's a comparison of widely used tools across open-source, enterprise, and cloud-native categories:
Want to explore the tools that power modern data pipelines end-to-end? Read The Ultimate Guide to Data Engineering Tools in 2025 to discover the best platforms for ingestion, processing, orchestration, and more.
Even with a well-planned architecture, data integration projects often face operational challenges that can impact performance, data reliability, and user trust. Below are three key challenges and how to address them effectively:
1. Handling Data Variety and Schema Mismatches
With data coming from diverse sources—structured databases, APIs, IoT devices, and unstructured logs—format mismatches and evolving schemas are inevitable. These inconsistencies can break pipelines or lead to data loss.
Solution: Use schema registries (e.g., Confluent Schema Registry) to manage versioning. Implement transformation logic at ingestion to normalize formats, and validate data structures before they enter processing stages.
2. Managing Pipeline Performance and Latency
As data volumes grow, pipelines can experience bottlenecks, delayed processing, or failure under load. This affects both real-time and batch workflows.
Solution: Optimize pipeline design with asynchronous processing and partitioning. Use distributed processing frameworks like Apache Spark or Beam and apply autoscaling in cloud environments to manage load variations.
3. Ensuring Data Quality and Consistency Across Systems
Poor data quality leads to unreliable analytics, misinformed decisions, and reprocessing overhead. Inconsistent records across systems also hinder compliance and reporting.
Solution: Introduce data quality checks (e.g., null checks, range validations, duplicates) early in the pipeline. Use monitoring tools like Great Expectations or custom rules to enforce consistency and track anomalies over time.
Proactively addressing these challenges not only improves integration stability but also builds trust in the data delivered to business users.
We don’t just implement technology — we solve real-world problems with intelligent, secure, and scalable solutions.
Let’s Talk Data Strategy →Maintaining a reliable and scalable data integration architecture goes beyond initial setup—it requires consistent governance, visibility, and control. The table below outlines key best practices along with their purpose and implementation tips to ensure long-term maintainability and operational efficiency.
QuartileX helps businesses design and implement scalable data integration architectures that support seamless data flow across systems. Our expertise in AI-driven automation and cloud-based solutions allows organizations to optimize performance while maintaining security and compliance.
No templates, no shortcuts — just tailored solutions built around your business, goals, and team.
Get a Free Consultation →
What sets us apart?
With a flexible, tailored approach, QuartileX helps businesses unify their data ecosystems and drive smarter decision-making.
A well-structured data integration architecture is essential for businesses to streamline operations, enhance decision-making, and scale efficiently. It eliminates data silos, ensures seamless connectivity between systems, and enables real-time insights.
With the right approach, organizations can transform raw data into actionable intelligence, driving growth and innovation. Modern, automated data practices enhance integration by improving accuracy, security, and speed.
AI-driven solutions, cloud scalability, and real-time processing make data more accessible and valuable. Want to optimize your data strategy? Explore how QuartileX helps businesses implement intelligent, scalable data solutions. Have questions? Contact our experts today to find the right approach for your organization.
A: Use real-time integration for low-latency use cases like fraud detection or live analytics. Batch works best for scheduled reporting or non-urgent data loads. Evaluate based on frequency, urgency, and cost. Many architectures combine both for flexibility.
A: Traditional ETL handles structured, low-volume data. Big data integration supports large-scale, multi-format, and real-time pipelines. It relies on distributed processing and cloud-native tools. Schema evolution and scalability are core requirements.
A: Start with reliable ingestion from key data sources. Add transformation and cleaning layers to ensure consistency. Include monitoring, logging, and basic governance early. Build modularly to scale without rework.
A: Use schema registries and version control for incoming data. Design pipelines for backward compatibility. Add automated drift detection and alerting. Test downstream impacts before rollout.
A: AWS Glue, Azure Data Factory, and Google Dataflow offer serverless scalability. They integrate well with cloud storage and analytics. Apache NiFi and Kafka suit hybrid environments. Choose based on data velocity, connectors, and cloud platform.
From cloud to AI — we’ll help build the right roadmap.
Kickstart your journey with intelligent data, AI-driven strategies!


